标签:jquer 了解 end 操作系统 压力 getname 自定义 版本 过程
当下浏览器是JavaScript重要的宿主环境,因此我们非常有必要讨论一下浏览器这款客户端应用程序。而浏览器是伴随着互联网的发展而发展的。
1969年互联网诞生,此后得到了飞速的发展,它将全世界各地互联了起来。
1991年一个划时代的东西————浏览器横空出世,自此,互联网走进普通大众的家中,我们只需要输入一个url地址再按下回车这个窗口中就显示出我们想要的内容,早期的时候这些内容通常以文字的形式呈现出来,后来又有了图形化呈现的方式,我们通常把这个窗口和里面的内容叫做网页。
通过以上过程的描述,我们思考一个问题:
首先暂时对url做一个简单的理解:每个url地址都对应远方的某一台计算机(也就是服务器)中的一部分数据,计算机在正常联网的状态下会从刚才输入的地址对应的远方的某一台计算机(也就是服务器)中拿到一些数据之后再将其显示到窗口中,我们都知道从远方的那台计算机(服务器)给浏览器传输数据的过程中肯定是通过某些模拟信号(比如光信号)的不同的值(如强光表示1,弱光表示0)来表征0 1 0 1二进制编码,这些模拟信号到达我们用户的浏览器所在的计算机时会被转换成用电信号表征的(如高电平表示1,低电平表示0)0 1 0 1的二进制编码,这些信号通过网线被送到网卡,操作系统会将这些二进制编码会从网卡加载到浏览器管理的内存中,这些二进制编码是如何转换成页面中的一系列文字、图片的呢?
实际上浏览器(应用层)会调用操作系统提供的接口从而将内存中这些0 1 0 1按照某张码表(例如utf-8、ASCII)翻译成对应的字符序列(例如0x61被翻译成字符a),翻译完成之后的东西我们都很熟悉————html,浏览器拿到这个html片段之后就开始解析,解析的过程无非就是词法分析,语法分析,语义分析,中间代码生成,优化,目标代码生成,最终目标代码调用显卡驱动将各层内容显示给我们。css的解析是同样的道理。需要注意的是在语法解析和语义分析阶段,会构造一棵DOM树和一棵CSS样式树,然后按照css的规则将对应的样式以属性的形式赋给DOM树上的各个节点,这些节点都会以对象的形式存放在内存中
最原始的浏览器非常简单,仅仅显示一些文字、图片、输入框等,浏览器和服务器的交互模式就是浏览器主动发起请求,服务器根据浏览器的请求把相应的数据回传,这个阶段的浏览器只有html和css
随着浏览器和服务器之间交互的数据量越来越多,问题开始凸显。一个很典型的场景:在输入框中输入一个关键词,点击搜索,然后网页中给我们显示对应的结果,在早期只有html和css,还没有js的时候这个需求通常会用下面的html代码实现:
<form action="/index.php/resList.html"> <input type="text" name="swd" /> <input type="submit" value="点击搜索" /> </form>
点击搜索之后,页面就会跳到当前域下的/index.php/resList.html这个页面中,这个页面包含了我们想要的结果
这样的实现简单易读,但问题也比较严重
假如还没输入或还没输完整想要搜索的内容不小心点了一下搜索按钮,那么接下来将是漫长的等待,然后resList页面中出现一行文字:您输入的结果不能为空,在当时绝大多数用户使用的是速度仅为28.8kbit/s的猫上网,因此每次在客户端进行一次操作希望得到服务器中的某些数据时都是对耐心的一次考验。在诸如登录和注册的过程中对用户输入有某些特殊要求(例如用户名至少5位,且不能有特殊符号)时这种矛盾体现的更为明显。
于是JavaScript便诞生了,是的,JavaScript最初设计之初就是为了解决这样的客户端验证的问题的,这样一来服务器的压力有所降低,作为一门语言,肯定有一些基本的语法,例如变量定义,数据类型,表达式和语句格式,作用域等等,最初这些都是由网景公司自己实现的,后来网景把这些语法规定提交给ECMA International,以便让之后的浏览器制造商遵循该标准,该标准就是ECMAScript的第一个版本。
当然我们知道后来网景被IE打败,IE自己造了一套标准,因此出现了现在这么多的IE兼容问题。
关于ECMA的设计思路有一点非常值得一提:一切皆对象,它规定实现ECMA标准的语言是基于对象的,对象通过构造函数构造出来。同时它也规定了实现ECMA标准的语言必须实现一些最基础的构造函数:Object Function Array String Boolean Number Date,构造函数里面描述对象的各个组成部分(属性和方法),那么我们怎么在脚本中得到一个对象呢?大概有以下两种方法:
1、通过new后面跟构造函数创建对象
2、简化定义方式
举例说明:
var arr = [1, 2, 3]; //这句话和var arr = new Array(1, 2, 3);等价 var obj = {a: 1}; //这句话和var obj = new Object(); obj.a = 1;等价 function fn(){ var a = 3; } //这个函数定义和var fn = new Function("var a = 3;"); var str = "aaa"; //对于基本类型,在程序运行过程中如果调用到了其方法,例如aaa.indexOf("a");会先构建一个new String("aaa")实例化对象,使用完毕之后立即销毁,本质上还是对象
如果想要得到Date的实例化对象,ECMA并没规定实现它的语言必须给我们提供类似上面这种“简化定义方式”,因此只能通过new Date()来创建
ECMA同时也规定实现它的语言必须提供一些对象:例如Math对象,事实上构造Math对象的函数是Object。
在此需要格外提一下Object构造函数,Object构造函数是一个空的构造函数,所谓空的构造函数就是没有任何额外的属性或方法(也有极少数用的很少的方法,例如valueOf和toString)。我们不妨拿数组Array构造函数来说明一下,Array的原型Array.prototype上已经有push pop shift等方法了,对象上也有length属性了,而Object的实例化对象什么属性和方法都没有
由于同类对象的方法都是一样的(例如[1, 2]和[2, 3]两个数组都有push pop等方法),因此为了避免空间浪费,同类对象的方法都共享在一个公共的对象上,这个对象就是原型对象
原型对象该如何访问到呢?有两种方法:
1、访问实例化对象的__proto__属性
2、访问构造函数的prototype属性(因为所有同类对象都是由同一个构造函数构造出来的,存储所有这些对象的方法的公共对象必然和构造函数有一定关系)
原型对象也是对象,既然是对象,就也应该有__proto__属性,该属性指向原型对象的原型对象,那原型对象的原型对象是一个什么对象呢?
如上所述,我们自己在程序里面创建的这些Function Array String Boolean Number Date的各个实例化对象的__proto__属性,即它的原型对象(例如new Date().__proto__)实际上是一个Object的实例化对象,该实例化对象上存储着该类对象相关的方法或属性,例如new Date().__proto__对象上有getHours getFullYear等方法
继续向上追溯,该实例化对象自然也有__proto__属性(即new Date().__proto__.__proto__),该对象(new Date().__proto__.__proto__)实际上就是Object的原型对象(即Object.prototype)
我们再往上追溯,Object的原型对象也是对象,那么它必然也有__proto__属性(即new Date().__proto__.__proto__.__proto__),这个属性是谁呢?由于已经到达了最顶层,因此该属性的值为null,可以在控制台中输入以下语句检测:
new Date().__proto__.__proto__ === Object.prototype //true
new Date().__proto__.__proto__.__proto__ === null //true
实际上,我们不仅仅可以使用系统给我们提供的最基本的Function Array String Boolean Number Date构造函数,还可以自己定义一些构造函数,构造函数也是函数,因此定义方式和普通函数没有区别,在构造函数中可以通过this给将来实例化的对象添加方法,可以通过Parent.prototype来访问到所有通过该构造函数创建出来的对象的原型对象,并在上面添加属性和方法:
function Parent(name){ this.name = name; // 给将来通过该构造函数实例化的对象添加name属性 } // 在原型对象上添加getName方法,这样所有实例化对象就可以访问到该方法 Parent.prototype.getName = function(){ return this.name; };
在ECMA的基础之上,浏览器利用这些特性定义了很多自定义的构造函数和对象,例如浏览器定义了名为window的全局对象,该对象的构造函数是Window,上面提到浏览器解析html和css时会构造出很多对象,并组成一个树结构,对于html标签,浏览器内部实现了HTMLHtmlElement构造函数,浏览器内部通过new HTMLHtmlElement()会创建出来一个html节点对象,同理页面中的div span img等等都对应一个个对象,也都有各自的构造函数(HTMLDivElement、HTMLSpanElement、HTMLImageElement),因为我们可以给每个html标签添加id作为其唯一标识,因此我们可以在一个script标签中通过该id标识就能访问到该对象:
<body> <div id="div1"></div> <div id="div2"></div> <div id="div3"></div> </body> <script> console.log(div1); // 访问id为div1的对象 console.log(div2); // 访问id为div2的对象 console.log(div3); // 访问id为div3的对象 </script>
在此说明一点,html标签、html节点、html对象说的都是同一个东西,本质上说的都是浏览器在内存中创建的这些代表页面中显示的各个部分的对象
接下来继续,通过div1拿到该对象之后我们可以访问一下它身上的属性,例如:
div1.id // "div1"
div1.tagName // "DIV"
此外,页面上的元素肯定是要和用户交互的,例如用户可以把鼠标指针移入div1这个元素,用户也可以点击div2元素,那么如果希望在用户做这些操作的时候干某些事情,就需要和这个div1、div2对象提前约定好,如何约定呢?通过事件,事件这个叫法也是比较形象的,因为用户的点击或移入做的这个动作本身就是一件事情,所以就叫事件。绑定事件有两种方式,比较直接的方式是:
<body> <div id="div1"></div> </body> <script> div1.onclick = function(){ alert("div1"); }; </script>
或者给这个事件起一个名字:
<body> <div id="div1" onclick="fnClick()"></div> </body> <script> function fnClick(){ alert("div1"); } </script>
html里面fnClick()就代表点击div1这个动作发生的时候执行script里面标识为fnClick对应的代码(即函数)
再回到我们上面提到的那个例子中:
<form action="/index.php/resList.html"> <input type="text" name="swd" id="swd" /> <input type="submit" value="点击搜索" id="submit" /> <span style="display: none;" id="prompt">搜索信息不能为空</span> </form> <script> submit.onclick = function(){ if (swd.value == "") { prompt.style.display = "block"; return false; } }; </script>
通过上面的代码我们就可以实现如果没有输入搜索信息,就显示错误提示这一功能,同样的登录、注册等表单验证也顺理成章比较优雅的实现了,这样一来,减少了大量不必要的服务器请求,服务器压力大幅下降
随后在1999年12月,ECMAScript3诞生,提供了强大的正则表达式,更好的词法作用域链处理,新的控制指令,异常处理,错误定义更加明确,数据输出的格式化及其它改变。此时的js除了让表单校验变的更为方便,还可以实现页面上一些飞来飞去的广告、选项卡、轮播图等效果。
随着网络时代的来临,互联网深入到各个领域,例如邮件、社交、文件传输等等,而服务器和客户端依然采用老一套的交互模式,因此问题也开始慢慢凸显出来,例如如果我希望给别人发邮件,则必须安装邮件应用程序(例如早期的Outlook)、如果我希望和别人聊天,则必须安装聊天的应用(例如早期的MSN以及现在的QQ),文件的上传下载也是同理。久而久之,电脑上安装了很多很多应用,假如能有一款应用可以干所有的这些事情,那无疑是非常受欢迎的,而浏览器就在慢慢成为这个角色,传统的应用程序(Client)和服务器(Server)之间的数据交互就被称为C/S架构,而通过浏览器(Browser)和服务器(Server)之间进行数据交互就被称为B/S架构,从刚才的分析来看,网络的发展慢慢从 Client/Server 结构开始向 Browser/Server 结构过渡,因此浏览器被赋予收发邮件、通讯、上传下载等等越来越重要的功能。
然而,面对这么多复杂的功能要从独立的应用程序迁移到浏览器中,那个年代的浏览器显然没有做好充分准备,用浏览器实现这类复杂的功能出现的问题很明显,通过举个例子说明: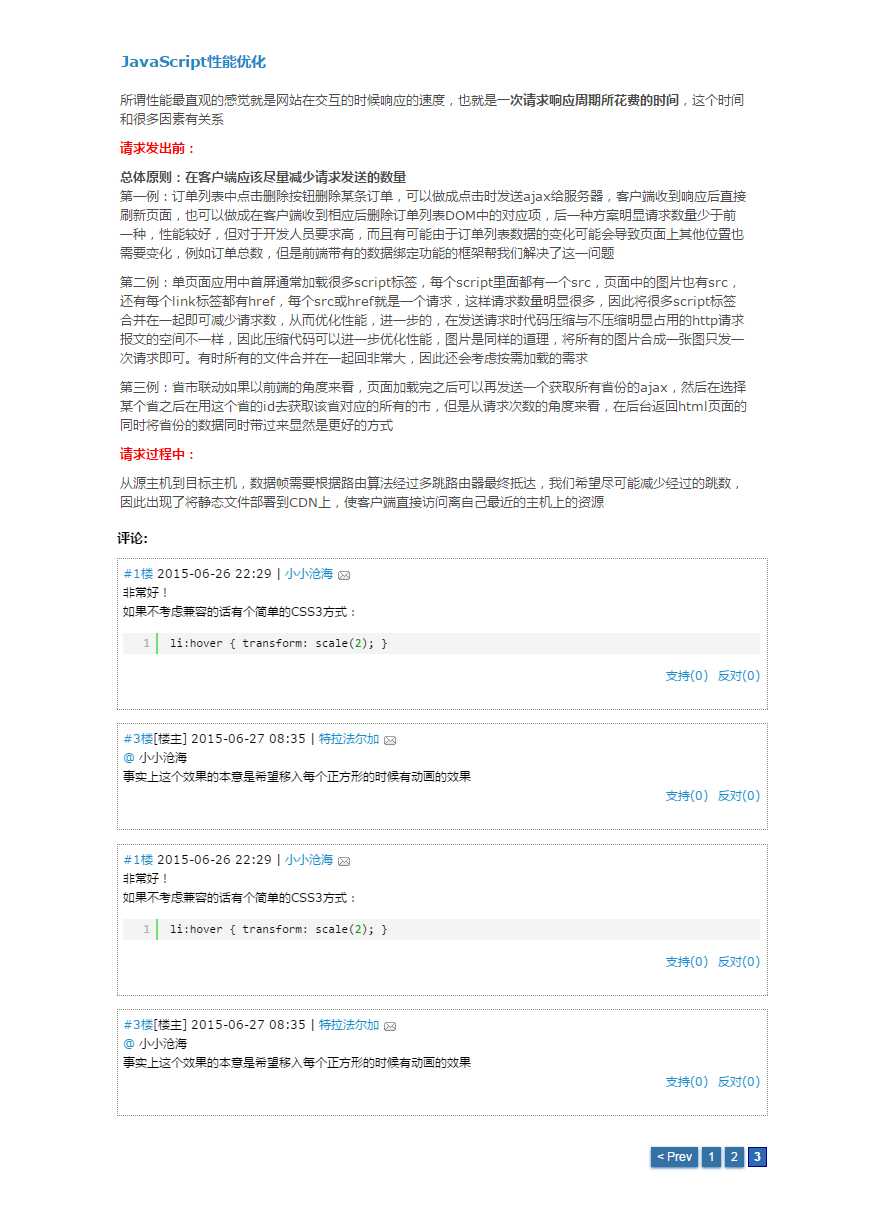
对于这样一个页面,由于一篇文章的评论可能会有很多条,因此肯定需要实现分页效果,因此这里的代码通常会这样实现:
<div id="article"> <p>文章内容</p> <p>文章内容</p> <p>文章内容</p> <p>文章内容</p> <p>文章内容</p> </div> <ul class="comment-list" id="commentList"> <li class="item"> <span>评论内容</span> <span>顶:12</span> <span>踩:12</span> </li> <li class="item"> <span>评论内容</span> <span>顶:12</span> <span>踩:12</span> </li> <li class="item"> <span>评论内容</span> <span>顶:12</span> <span>踩:12</span> </li> </ul> <ul class="pageCode"> <!-- 注意a链接的href值直接是一个地址,点击之后就转到一个新的页面了 --> <li class="item"><a href="/article/566844.html">1</a></li> <li class="item"><a href="/article/566844.html?comment_page=2">2</a></li> <li class="item"><a href="/article/566844.html?comment_page=3">3</a></li> </ul>
但是当我们点击页码切换到第2页、第3页评论时会发现浏览器重新把整个页面刷新了一遍,就连评论上方的文章都重新加载了一遍,评论上方的文章数据量可能非常大,这部分内容的重新发送很显然是浪费了大量的资源。随着网页越来越复杂,这种矛盾也更明显,因此,一个急需解决的问题出现了,如何在点击页码的时候单独发出一个请求,这个请求专门去拿点击的页码对应的评论数据,拿到之后再渲染到.comment-list中去。
于是,各个浏览器就在内部实现一个名为XMLHttpRequest的构造函数(早期的IE是通过ActiveXObject实现的),该构造函数和上面提到的HTMLDivElement、HTMLSpanElement没有什么本质区别,因此通过该构造函数可以得到一个对象,该对象有以下方法:
var oXHR = new XMLHttpRequest();
oXHR.open("GET", "/comment/getCommentList?pageNum=2&pageSize=4", true); // 接受三个参数,分别为请求方式、请求地址、是否异步,第三个参数如果不传默认为true
oXHR.send(null);
oXHR.onreadystatechange = function(ev){}; // 从应用层封装好数据,调用传输层接口,发送数据到最终接收到数据的整个过程中有几个关键时间点,每到一个时间点就会触发一次该事件,该方法的事件对象属性readyState可以区分到底是哪个关键时间点:
0 初始状态
1 open方法被调用,HTTP数据包已封装好,交给传输层,三次握手,建立TCP链接
2 send方法被调用,TCP链接已经建立,开始发数据
3 已根据端口号和进程ID确定好将接收来的数据转发给哪个应用程序(浏览器),浏览器已把HTTP响应报文的头信息解析完毕
4 浏览器已把HTTP响应报文的数据部分解析完毕,可供程序使用
到达上面描述的状态4的时候,onreadystatechange事件对象里一个叫做responseText的属性将被赋值为HTTP响应报文的数据部分,这个数据部分就是一个普通的字符串,这个串里面数据的格式可以有多种,例如,服务器可以直接将所有数据处理好返给前端,即拿到的字符串是以下这种形式:
"<li class=\"item\">
<span>评论内容</span>
<span>顶:12</span>
<span>踩:12</span>
</li>
<li class=\"item\">
<span>评论内容</span>
<span>顶:12</span>
<span>踩:12</span>
</li>
<li class=\"item\">
<span>评论内容</span>
<span>顶:12</span>
<span>踩:12</span>
</li>"
如果要是这种形式的数据的话,浏览器端则不用再做过多处理,只需要先把.comment-list的innerHTML属性直接替换成拿来的数据放进去即可:
oXHR.onreadystatechange = function(e){ var sCommentHTML; if (oXHR.status == 200 && e.readyState == 4) { sCommentHTML = e.responseText; } commentList.innerHTML = sCommentHTML; };
当数据量较小时这样做也没问题,但是当数据量变大时,这样做的弊端也很明显,拼接html需要服务器来做,请求的浏览器越多,服务器压力就越大,因此从性能上来讲肯定不好,因此这里通常采用一种轻量级数据格式——json来传递,使用json的另一个原因是对于传统后台语言,都有直接将其语言自身的数据结构转为json字符串的API,例如PHP中的json_encode
使用json数据传输之后体积是缩小了,服务器压力也有所下降,但是对于浏览器来说麻烦来了,还是上面的评论列表,假如回来的数据是下面这种形式:
"[ { comment_id: "1", content: \"评论内容\", support: 12, opposite: 23 }, { comment_id: "2", content: \"评论内容\", support: 12, opposite: 23 }, { comment_id: "3", content: \"评论内容\", support: 12, opposite: 23 } ]"
浏览器的处理方式就变为:
oXHR.onreadystatechange = function(e){ var aComments; if (oXHR.status == 200 && e.readyState == 4) { aComments = eval(e.responseText); // 这里先将序列化的数组转换为真正的数组 var sCommentHTML = ""; // 接下来需要根据json数据生成对应的DOM结构,共有两种思路,我们先说第一种:拼接HTML for(var i = 0; i < aComments.length; i++) { var item = "<li class=\"item\"> <span>评论内容</span> <span>顶:" + aComments[i].support + "</span> <span>踩:" + aComments[i].opposite + "</span> </li>"; sCommentHTML += item; } commentList.innerHTML = sCommentHTML; } };
虽然每条数据只有三个字段要处理,但是可以看出来,字符串的拼接已经比较麻烦,而有些评论的列表里面还会有图片,还会有代码等等,我们这里还没有涉及到给顶和踩添加事件,但是操作起来已经极为不便了,因此第二种方式(利用浏览器提供的DOM操作接口)就出来了:
oXHR.onreadystatechange = function(e){ var aComments; if (oXHR.status == 200 && e.readyState == 4) { aComments = eval(e.responseText); for(var i = 0; i < aComments.length; i++) { var oCommentItem = document.createElement("li"); oCommentItem.className = "item"; var oCommentContent = document.createElement("span"); oCommentContent.innerHTML = aComments[i].content; var oSupportCount = document.createElement("span"); oSupportCount.innerHTML = aComments[i].support; var oOppositeCount = document.createElement("span"); oOppositeCount.innerHTML = aComments[i].opposite; oCommentItem.appendChild(oCommentContent); oCommentItem.appendChild(oSupportCount); oCommentItem.appendChild(oOppositeCount); commentList.appendChild(oCommentItem); } } };
这样看起来逻辑是清晰了,但是代码操作冗余度极大,重复代码写了很多,看起来依然非常难受。
到此为止,明显暴露出了很多问题,为了暴露更多问题,我们把顶一下这个功能也加上:
假如我们想要得到的html如下:
<ul class="comment-list" id="commentList"> <li class="item"> <span class="content">评论内容</span> <input type="button" value="顶一下" class="support-button" /> <span class="support-num">12</span> </li> <li class="item"> <span class="content">评论内容</span> <input type="button" value="顶一下" class="support-button" /> <span class="support-num">12</span> </li> <li class="item"> <span class="content">评论内容</span> <input type="button" value="顶一下" class="support-button" /> <span class="support-num">12</span> </li> </ul>
实现的代码为:
oXHR.onreadystatechange = function(e){ var aComments; if ((xhr.status == 200 || xhr.status == 304) && e.readyState == 4) { aComments = eval(e.responseText); for(var i = 0; i < aComments.length; i++) { var oCommentItem = document.createElement("li"); oCommentItem.className = "item"; var oCommentContent = document.createElement("span"); oCommentContent.className = "content"; oCommentContent.innerHTML = aComments[i].content; var oSupportButton = document.createElement("input"); oSupportButton.type = "button"; oSupportButton.value = "顶一下"; oSupportButton.className = "support-button"; oSupportButton.comment_id = aComments[i].comment_id; var oSupportCount = document.createElement("span"); oSupportCount.innerHTML = aComments[i].opposite; oCommentItem.appendChild(oCommentContent); oCommentItem.appendChild(oSupportButton); oCommentItem.appendChild(oSupportCount); // isClickedSupportButton防止重复点击 var isClickedSupportButton = false; oSupportButton.onclick = function(){ var _this = this; isClickedSupportButton = true; if (isClickedSupportButton) { return; } var xhr = new XMLHttpRequest(); xhr.open("POST", "/Comment/supportComment"); var sendData = { "comment_id": this.comment_id }; xhr.send(JSON.stringify(sendData)); xhr.onreadystatechange = function(e){ if ((xhr.status == 200 || xhr.status == 304) && e.readyState == 4) { if (e && e.status) { oSupportCount.innerHTML = parseInt(oSupportCount.innerHTML) + 1; // 在更多的场合下,无法直接拿到oSupportCount对象的引用,但是当前点击对象是很容易拿到的 // 这样一来,就需要调用DOM相关API来获取 // 而由于浏览器的兼容问题,调用DOM相关API获取将会是一件极其麻烦的事情 // 在此我们采用两种获取方式来说明问题 // 1、由于.support-num就在.support-button的后面,因此可以调用nextElementSibling获取 // 但是IE8没有nextElementSibling,只有nextSibling // 对于高版本浏览器虽然也有nextSibling但是它会把文本节点 注释节点都算进去,因此不方便用 // 所以只能是根据浏览器判断 // 如果有nextElementSibling直接用(高版本浏览器),如果没有就用nextSibling(低版本浏览器) var oSupportCount = _this.nextElementSibling || _this.nextSibling; oSupportCount.innerHTML = parseInt(oSupportCount.innerHTML) + 1; // 2、当要操作的DOM对象不是当前点击对象的相邻对象时,如果还用上面的方法 // 就可能出现找好多次nextElementSibling,再找好多次previousElementSibling,再加上兼容的问题 // 代码将会极其恶心 // 对于找DOM元素,我们之前一直都是通过ID的方式去找 // 这次我们绝不能用id了,因为id是唯一标识,而评论会有好多条,给每个评论都加id明显不合适 // 我们迫切需要一种通过类名来获取元素的方式,但遗憾的是既在标准里面提供的又在浏览器实现的方法只有两个: // document.getElementById() 通过id获取元素,跟我们之前直接通过id名获取元素一样 // document.getElementsByTagName() 通过标签名获取元素 // 注意:虽然浏览器实现了querySelector和querySelectorAll来通过CSS选择器获取元素 // 但这两个方法在标准中没有定义,直到HTML5才被标准化 // 在HTML5问世之前,有的代码中通过getElementsByTagName先获取到所有元素,再通过类名来判断目标元素集的方式得到最终结果 // 有的代码中则直接使用querySelector或querySelectorAll了 var oParent = _this.parentNode; var oSupportCount = oParent.querySelector(".support-num"); oSupportCount.innerHTML = parseInt(oSupportCount.innerHTML) + 1; } } }; }; commentList.appendChild(oCommentItem); } } };
还有一点需要注意到,虽然代码已经比较啰嗦,但是我们并没有把顶一下的功能写到外面,因为ajax还存在异步的问题,尽管我们可以在XMLHttpRequest对象的open方法中通过传参控制为同步请求:
oXHR.open("GET", "/Comment/getCommentsList?pageIndex=1&pageSize=4", false); // 第三个参数代表是否异步,如果设置为false代表不异步
这样做会严重影响用户体验,在发出获取评论这个请求到请求成功这段时间内用户什么都干不了,只能干等着,而且这样做浏览器也会给出警告
至此,顶一下的功能终于也实现了,但是我们为此付出了很大代价,代码量相当庞大,根本的原因就在于浏览器为我们提供的接口太底层、太单一,而且存在很多兼容性问题,而web端应用的复杂度远不止上面这个例子这样,于是出现了很多的库函数来封装一些常见的功能:
2005年2月,Sam Stephenson发布了Prototype.js的第一个版本
2006年1月,John Resig发布了jQuery的第一个版本
从国内目前的现状来看明显jQuery比Prototype更为流行一些,因此我们接下来的工作就是以jQuery为蓝本,自己逐步搭建起来一个库来把各种功能封装起来。
从下一篇开始,我们将分析我们需要实现的功能
JavaScript框架探索1——为何JavaScript开发需要框架
标签:jquer 了解 end 操作系统 压力 getname 自定义 版本 过程
原文地址:http://www.cnblogs.com/zhaohuiziwo901/p/7041618.html