标签:三层 文件 bin pen 数据 python2 pfile pip 官方文档
首先安装docx模块,通过pip install docx或者在docx官方链接上下载安装都可以
下面来看下如何解析docx文档:文档格式如下
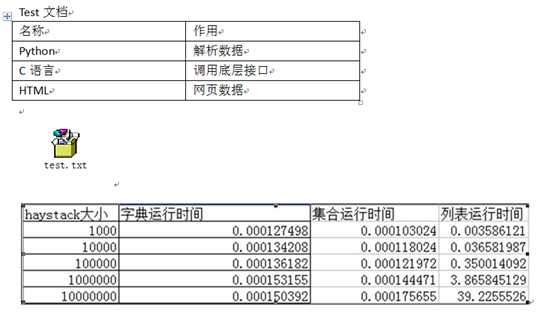
有3个部分组成 1 正文:text文档 2 一个表格。 3一个插入的文件对象。4 一个图片 这4个部分是我们在docx文档中最常见的几种格式。解析代码如下
import docx
def docx_try():
doc=docx.Document(r‘E:\py_prj\test.docx‘)
for p in doc.paragraphs:
print p.text
for t in doc.tables:
for r in t.rows:
for c in r.cells:
print c.text
E:\python2.7.11\python.exe E:/py_prj/test3.py
Test文档
名称
作用
Python
解析数据
C语言
调用底层接口
HTML
网页数据
首先是用docx.Document打开对应的文件目录。docx文件的结构比较复杂,分为三层,1、Docment对象表示整个文档;2、Docment包含了Paragraph对象的列表,Paragraph对象用来表示文档中的段落;3、一个Paragraph对象包含Run对象的列表。 因此p.text会打印出整个的文本文档。而用doc.tables来遍历所有的表格。并且对每个表格通过遍历行,列的方式来得到所有的内容。
但是在运行结果中并没有找到我们插入的文件对象和图片,text.txt文档。这部分该如何解析呢。首先我们需要先来认识下docx文档的格式组成:
docx是Microsoft Office2007之后版本使用的,用新的基于XML的压缩文件格式取代了其目前专有的默认文件格式,在传统的文件名扩展名后面添加了字母“x”(即“.docx”取代“.doc”、“.xlsx”取代“.xls”、“.pptx”取代“.ppt”)。
docx格式的文件本质上是一个ZIP文件。将一个docx文件的后缀改为ZIP后是可以用解压工具打开或是解压的。事实上,Word2007的基本文件就是ZIP格式的,他可以算作是docx文件的容器。
docx 格式文件的主要内容是保存为XML格式的,但文件并非直接保存于磁盘。它是保存在一个ZIP文件中,然后取扩展名为docx。将.docx 格式的文件后缀改为ZIP后解压, 可以看到解压出来的文件夹中有word这样一个文件夹,它包含了Word文档的大部分内容。而其中的document.xml文件则包含了文档的主要文本内容
从上面的文档我们可以了解到docx文档实际上是由XML文档打包组成的。那么我们要得到其中所有的部分,可以用ZIP解压的方式来得到所有的部件。我们先试下看是否可以
1 将docx文档改成ZIP的后缀
2 解压文件
解压之后得到如下几个文件
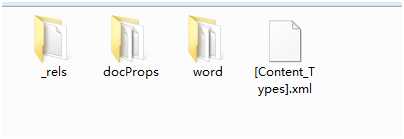
点开word文件夹:有如下的文件夹。document.xml就是描述文本对象的文件

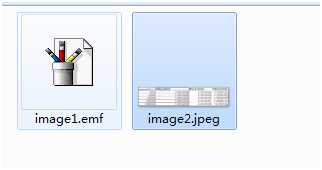
其中embeddings文件中就是我们插入的文本对象text.txt. 是一个bin文件

Media文件中就是存储的图片:
我们通过手动的方式将插入的文本以及图片解析出来,那么通过代码也是同样可以解析的。代码如下。
os.chdir(r‘E:\py_prj‘) #首先改变目录到文件的目录
os.rename(‘test.docx‘,‘test.ZIP‘) # 重命名为zip文件
f=zipfile.ZipFile(‘test.zip‘,‘r‘) #进行解压
for file in f.namelist():
f.extract(file)
file=open(r‘E:\py_prj\word\embeddings\oleObject1.bin‘,‘rb‘).read() #进入文件路径,读取二进制文件。
for f in file:
print f
通过上面的方式,就可以将docx中插入的文件以及图片全部解析出来。具体docx的写的方式可以参考官方文档的介绍
python 解析docx文档的方法,以及提取插入的文本对象和图片
标签:三层 文件 bin pen 数据 python2 pfile pip 官方文档
原文地址:http://www.cnblogs.com/zhanghongfeng/p/7043412.html