标签:第二范式 删除 重复 tun 查询 nbsp 数据库 ima 个数
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能同时有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。
在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。在当前的任何关系数据库管理系统(DBMS)中,不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是唯一的,因此每个员工可以被唯一区分。这个唯一属性列被称为主关键字或主键、主码。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。简而言之,第二范式就是属性完全依赖于主键。
这里说的主关键字可能不只有一个,有些情况下是存在联合主键的,就是主键有多个属性。
举例:
以学生选课为例,每个学生都可以选课,并且有这一门课程的成绩,那么如果将这些信息都放在一张表StuGrade(stuNo,stuName,age,sex,courseNo,courseName,credit,score)。
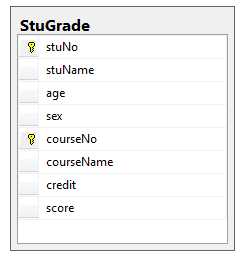
如果不仔细看,我们会以为这张表的主键是stuNo,但是当我们看到最后一个score属性以后,在想想如果没有课程信息,那么哪里有学生成绩信息呢。所以这张表的主键是一个联合主键(stuNo,corseNo),这个联合属性能够唯一确定score属性。那么再看其他信息,比如stuName只需要stuNo就能够唯一确定,courseName只需要courseNo就能够唯一确定,因此这样就存在了部分依赖,不符合第二范式。如果要让学生课程成绩信息满足第二范式,那么久需要将这张表拆分成多张表,一张学生表Studnet(stuNo,stuName,age,sex),一张课程表Course(courseNo,courseName,credit),还有最后一张学生课程成绩表StuGrade(stuNo,courseNo,score)。
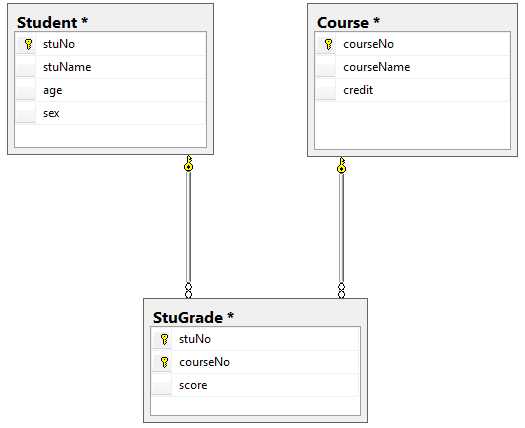
这样就符合第二范式了。
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
举例:
每一个员工都有一个所属部门,假如有一个员工信息表Employee(emp_id,emp_name,emp_age,dept_id,dept_name,dept_info)。
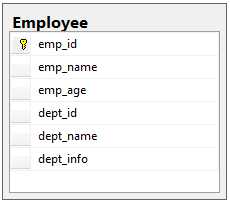
这张员工信息表的主键是emp_id,因为这个属性能够唯一确定其他所有属性,比如知道员工编号emp_id以后,肯定能够知道员工姓名,所属部门编号,部门名称和部门介绍。所以这里dept_id不是主属性,而是非主属性。但是,我们又可以发现dept_name,dept_info这两个属性也可以由dept_id这个非主属性决定,即dept_name依赖dept_id,而dept_id依赖emp_id,这样就存在了传递依赖。而且我们可以看出传递依赖的一个明显缺点就是数据冗余非常严重。
那么如何解决传递依赖问题,其实非常简单,我们只需要将dept_name,dept_info这连个属性删除就可以了,即Employee(emp_id,emp_name,emp_age,dept_id),然后再创建一个部门表Dept(dept_id,dept_name,dept_info)。
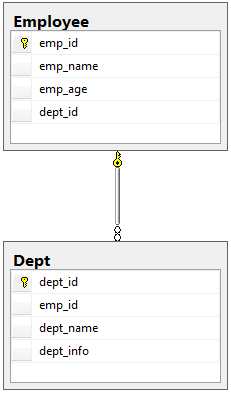
这样如果要搜索某一个员工的部门信息dept_info,可以通过数据库连接来实现,查询语句如下:
select e.emp_id,e.emp_name,d.dept_name from Employee e,Dept d where e.dept_id=d.dept_id
注意点:
标签:第二范式 删除 重复 tun 查询 nbsp 数据库 ima 个数
原文地址:http://www.cnblogs.com/wihainan/p/7050046.html