标签:pipe dict elf 调试 内容 dom rac 过程 app
Shell调试:
进入项目所在目录,scrapy shell “网址”
如下例中的:
scrapy shell http://www.w3school.com.cn/xml/xml_syntax.asp
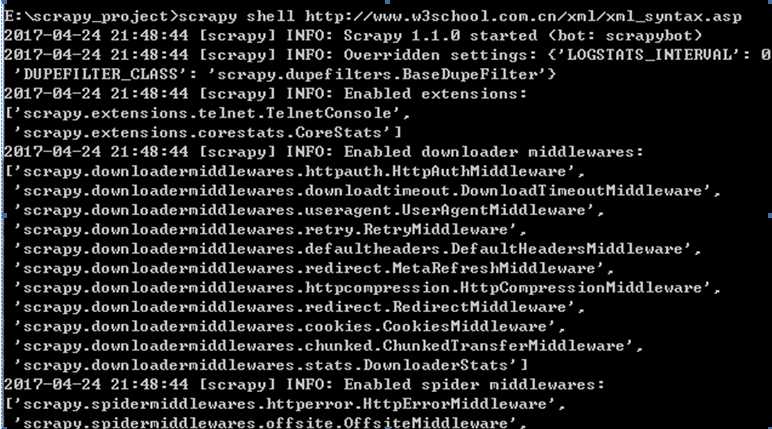
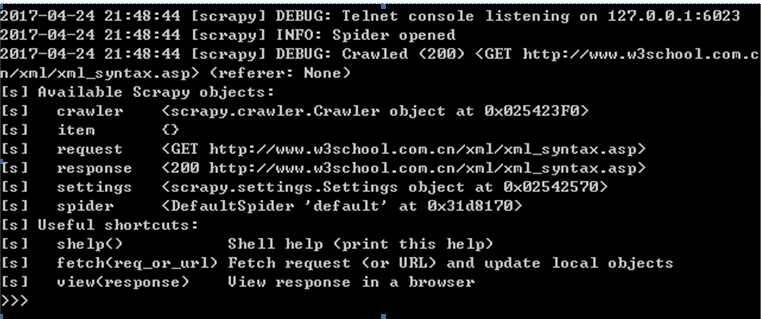
可以在如下终端界面调用过程代码如下所示:
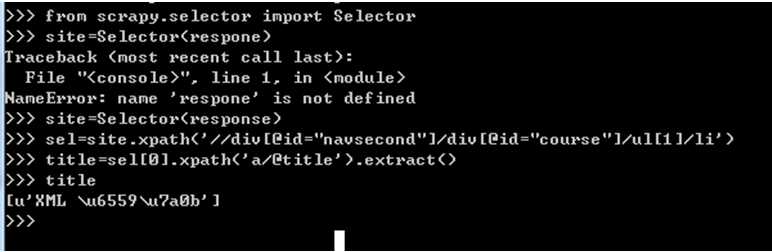
相关的网页代码:

我们用scrapy来爬取一个具体的网站。以迅读网站为例。
如下是首页的内容,我想要得到文章列表以及对应的作者名称。
首先在items.py中定义title, author. 这里的Test1Item和Django中的modul作用类似。这里可以将Test1Item看做是一个容器。这个容器继承自scrapy.Item.
而Item又继承自DictItem。因此可以认为Test1Item就是一个字典的功能。其中title和author可以认为是item中的2个关键字。也就是字典中的key
class Item(DictItem):
class Test1Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=Field()
author=Field()
下面就在test_spider.py中开始写网页解析代码
from scrapy.spiders import Spider
from scrapy.selector import Selector
from test1.items import Test1Item
class testSpider(Spider):
name="test1" #这里的name必须和创建工程的名字一致,否则会提示找不到爬虫项目
allowd_domains=[‘http://www.xunsee.com‘]
start_urls=["http://www.xunsee.com/"]
def parse(self, response):
items=[]
sel=Selector(response)
sites = sel.xpath(‘//*[@id="content_1"]/div‘) #这里是所有数据的入口。下面所有的div都是存储的文章列表和作者
for site in sites:
item=Test1Item()
title=site.xpath(‘span[@class="title"]/a/text()‘).extract()
h=site.xpath(‘span[@class="title"]/a/@href‘).extract()
item[‘title‘]=[t.encode(‘utf-8‘) for t in title]
author=site.xpath(‘span[@class="author"]/a/text()‘).extract()
item[‘author‘]=[a.encode(‘utf-8‘) for a in author]
items.append(item)
return items
获取到title以及author的内容后,存储到item中。再将所有的item存储在items的列表中
在pipelines.py中修改Test1Pipeline如下。这个类中实现的是处理在testSpider中返回的items数据。也就是存储数据的地方。我们将items数据存储到json文件中去
class Test1Pipeline(object):
def __init__(self):
self.file=codecs.open(‘xundu.json‘,‘wb‘,encoding=‘utf-8‘)
def process_item(self, item, spider):
line=json.dumps(dict(item)) + ‘\n‘
self.file.write(line.decode("unicode_escape"))
return item
工程运行后,可以看到在目录下生成了一个xundu.json文件。其中运行日志可以在log文件中查看
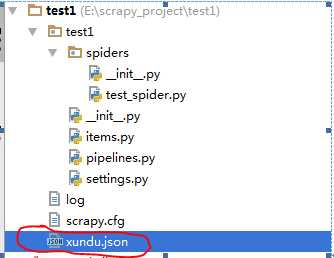
从这个爬虫可以看到,scrapy的结构还是比较简单。主要是三步:
1 items.py定义内容存储的关键字
2 自定义的test_spider.py中进行网页数据的爬取并返回数据
3 pipelines.py中对tes_spider.py中返回的内容进行存储
标签:pipe dict elf 调试 内容 dom rac 过程 app
原文地址:http://www.cnblogs.com/zhanghongfeng/p/7056353.html