标签:为什么 技术 blog 将不 sea 位置 java 大于 元素
1.基本概念
查找表:是由同一类型的元素构成的集合
关键字:数据元素中某个数据项的值
静态查找表和动态查找表
静态查找表:查询某个“特定的”数据元素是否在查找表中
查询某个“特定的”数据元素和各种属性
动态查找表:在查找的过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素
2.各种查找算法的比较
(1)线性查找
从表中的第一个(或最后一个)记录开始。组个进行记录的关键字和给定比值的比较,若某个记录的关键字和给定值相等,则查找成功。
C语言代码
1 int Sequential_Serach(int a[],int n,int key){ //a为数组,n为要查找的数组长度,key为要查找的关键字
2 int i;
3 for(i=1;i<=n;i++){
4
5 if(a[i]=key)
6 return i;
7 }
8 return 0;
9 }
Java代码
1 public static int Sequuential_Search(int [] a,int key){
2 for(int i=1;i<=a.length;i++){
3 if(a[i]==key){
4 return i;
5 }
6 }
7 return 0;
8 }
1 //线性查找表的优化
2 public int Sequential_Search2(int [] a,int key){
3 int i=a.length;
4 a[0]=key; //设置a[0]为关键字值
5 while(a[i]!=key){ //从数组尾部开始查找
6 i--;
7 }
8 return i; //返回0这说明查找失败,a[1]-a[n]中没有关键字
9 }
(2)折半查找
这种查找方法的前提是线性表中的记录必须是有顺序的,也就是说线性表必须采用顺序存储,基本思想:去取中间记录作为比较对象,若给定的值与中间记录的关键字相等,这还则查找成功,若给定值小于中间记录的关键字,则在左半区继续查找,相反在右半区进行查找,不断重复,找到为止。
C语言代码
1 int Binary_Serach(int a [],int n,int key){
2 int low,hing,mid;
3 low=1;
4 high=n;
5 while(low<=high){
6 mid=(low+high)/2;
7 if(key<a[mid])
8 high=mid-1;
9 else if(key>a[mid])
10 low=mid-1;
11 else
12 return mid;
13 }
14 return 0;
15 }
Java代码
1 public int Binary_Search(int [] a,int n,int key){
2 int low,high,mid;
3 low=1;
4 high=n;
5 while(low<=high){
6 mid=(low+high)/2;
7 if(key<a[mid])
8 high=mid-1;
9 else if(key>a[mid])
10 low=mid-1;
11 else
12 return mid;
13 }
14 return 0;
15 }
(3)插值查找
直接上代码吧
//在二分查找的基础上将mid=(low+high)/2换成了如下的
//mid=low+(high-low)*(key-a[low])/(a[high]-a[low])
1 public int Binary_Search(int [] a,int n,int key){ 2 int low,high,mid; 3 low=1; 4 high=n; 5 while(low<=high){ 6 mid=low+(high-low)*(key-a[low])/(a[high]-a[low]); 7 if(key<a[mid]) 8 high=mid-1; 9 else if(key>a[mid]) 10 low=mid-1; 11 else 12 return mid; 13 } 14 return 0; 15 }
(4) 斐波拉契查找
先说一下什么是黄金分割吧
黄金分割是指将整体一分为二,较大部分与整体部分的比值等于较小部分与较大部分的比值,其比值约为0.618。这个比例被公认为是最能引起美感的比例,因此被称为黄金分割。
假设一个斐波拉契数列为1,1,2,3,5,8,13,21,34,55,89,········
随着数字的增加,斐波拉契数列的钱一个数和后一个数的比值越来越接近于0.618,我们正是利用了这个性质来进行查找,一个简单的示意图如下所示
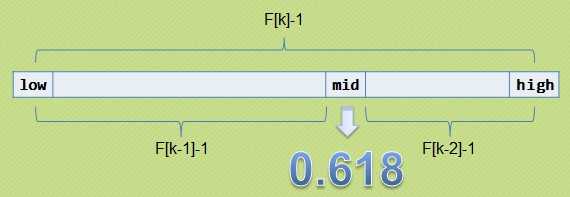
mid的开始位置如何确定?
我们刚开始分割时要满足黄金比例分割,假设待查找数组的个数为n,我们在斐波拉契数列中找到满足F[k]大于n,且最接近于n,得到F[k]之后将前两个值作为划分的依据即F[k-1]和F[k-2]两部分。
大部分说明都忽略了一个条件的说明:n=F(k)-1, 表中记录的个数为某个斐波那契数小1。这是为什么呢?
查找的时候可以分为三种情况
(1)相等的时候,mid位置即为要查找的位置
(2)当要查找的key小于mid位置的值时,即在图示的左边,就更新high值,high=mid-1,k-=1;说明:low=mid+1说明待查找的元素在[low,mid-1]范围内,k-=1 说明范围[low,mid-1]内的元素个数为F(k-1)-1个,所以可以递归的应用斐波那契查找
(3)当要查找的key大于mid位置的值时,即在图示的右边,就更新low的值,,low=mid+1,k-=2;说明:low=mid+1说明待查找的元素在[mid+1,hign]范围内,k-=2 说明范围[mid+1,high]内的元素个数为n-(F(k-1))= Fk-1-F(k-1)=Fk-F(k-1)-1=F(k-2)-1个,所以可以递归的应用斐波那契查找
C语言代码如下
1 //斐波拉契查找 2 int Fibonacci_Search(int a[],int n,int key){ 3 int low,high,mid,i,k; 4 low=1; 5 high=n; 6 k=0; 7 while(n>F[k]-1){ //计算n位于斐波拉契数列的位置 8 k++; 9 } 10 for(i=n;i<F[k]-1;i++){ //将不满的数值补全 11 a[i]=a[n]; 12 } 13 while(low<=high){ 14 mid=low+F[k]-1; //计算当前分割的下标 15 if(key<a[mid]){ 16 high=mid-1; 17 k=k-1; 18 } 19 else if(key>a[mid]){ 20 low=mid+1; 21 k=k-2; 22 } 23 else{ 24 if(mid<=n) 25 return mid; //若相等说明mid即为查找到的值 26 else 27 return n; //若大于n说明是补全的数值,返回n 28 } 29 30 } 31 return 0; //没找到 32 }
标签:为什么 技术 blog 将不 sea 位置 java 大于 元素
原文地址:http://www.cnblogs.com/zhuchuanliang/p/7067605.html