标签:编码问题 tom pac csdn 没有 default 程序 ror 手动
问题描述: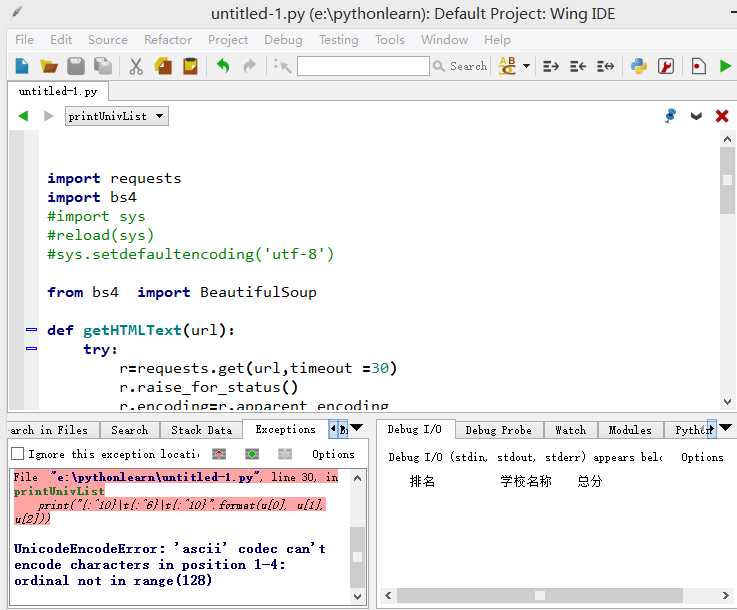
Python在安装时,默认的编码是ascii,当程序中出现非ascii编码时,python的处理常常会报这样的错UnicodeDecodeError: ‘ascii‘ codec can‘t decode byte 0x?? in position 1: ordinal not in range(128),python没办法处理非ascii编码的,此时需要自己设置将python的默认编码,一般设置为utf8的编码格式。
查询系统默认编码可以在解释器中输入以下命令:
Python代码
设置默认编码时使用:
Python代码
可能会报AttributeError: ‘module‘ object has no attribute ‘setdefaultencoding‘的错误,执行reload(sys),在执行以上命令就可以顺利通过。
此时在执行sys.getdefaultencoding()就会发现编码已经被设置为utf8的了,但是在解释器里修改的编码只能保证当次有效,在重启解释器后,会发现,编码又被重置为默认的ascii了,那么有没有办法一次性修改程序或系统的默认编码呢。
有2种方法设置python的默认编码:
一个解决的方案在程序中加入以下代码:
Python代码
另一个方案是在python的Lib\site-packages文件夹下新建一个sitecustomize.py,内容为:
Python代码
此时重启python解释器,执行sys.getdefaultencoding(),发现编码已经被设置为utf8的了,多次重启之后,效果相同,这是因为系统在python启动的时候,自行调用该文件,设置系统的默认编码,而不需要每次都手动的加上解决代码,属于一劳永逸的解决方法。
但是问题描述:按照上面所叙述的解决方案发现,打出来的是中文乱码。。。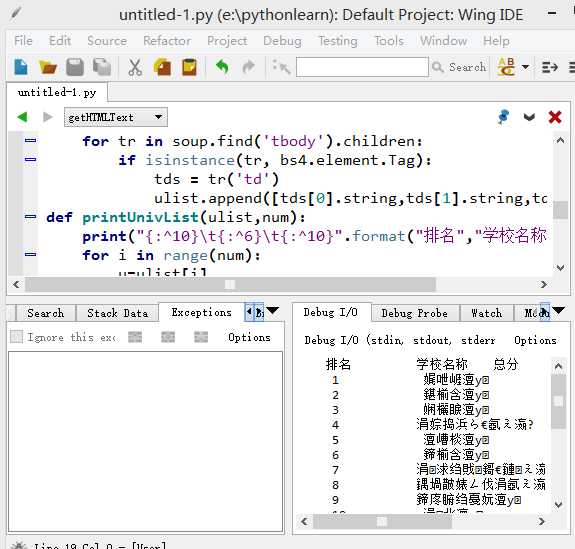
python 编码问题:'ascii' codec can't encode characters in position 的解决方案
标签:编码问题 tom pac csdn 没有 default 程序 ror 手动
原文地址:http://www.cnblogs.com/bebox/p/7071817.html