标签:小说 raw url 不同的 close lines 处理 .sh html
前面介绍的scrapy爬虫只能爬取单个网页。如果我们想爬取多个网页。比如网上的小说该如何如何操作呢。比如下面的这样的结构。是小说的第一篇。可以点击返回目录还是下一页
对应的网页代码:
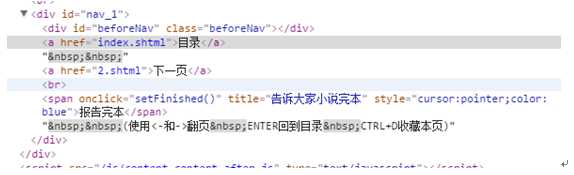
我们再看进入后面章节的网页,可以看到增加了上一页

对应的网页代码:
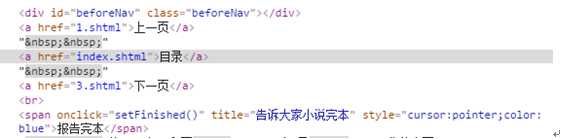
通过对比上面的网页代码可以看到. 上一页,目录,下一页的网页代码都在<div>下的<a>元素的href里面。不同的是第一章只有2个<a>元素,从二章开始就有3个<a>元素。因此我们可以通过<div>下<a>元素的个数来判决是否含有上一页和下一页的页面。代码如下

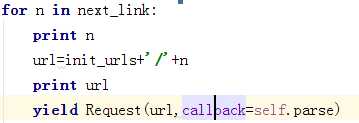
最终得到生成的网页链接。并调用Request重新申请这个网页的数据
那么在pipelines.py的文件中。我们同样需要修改下存储的代码。如下。可以看到在这里就不是用json. 而是直接打开txt文件进行存储
class Test1Pipeline(object):
def __init__(self):
self.file=‘‘
def process_item(self, item, spider):
self.file=open(r‘E:\scrapy_project\xiaoshuo.txt‘,‘wb‘)
self.file.write(item[‘content‘])
self.file.close()
return item
完整的代码如下:在这里需要注意两次yield的用法。第一次yield后会自动转到Test1Pipeline中进行数据存储,存储完以后再进行下一次网页的获取。然后通过Request获取下一次网页的内容
class testSpider(Spider):
name="test1"
allowd_domains=[‘http://www.xunsee.com‘]
start_urls=["http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/1.shtml"]
def parse(self, response):
init_urls="http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615"
sel=Selector(response)
context=‘‘
content=sel.xpath(‘//div[@id="content_1"]/text()‘).extract()
for c in content:
context=context+c.encode(‘utf-8‘)
items=Test1Item()
items[‘content‘]=context
count = len(sel.xpath(‘//div[@id="nav_1"]/a‘).extract())
if count > 2:
next_link=sel.xpath(‘//div[@id="nav_1"]/a‘)[2].xpath(‘@href‘).extract()
else:
next_link=sel.xpath(‘//div[@id="nav_1"]/a‘)[1].xpath(‘@href‘).extract()
yield items
for n in next_link:
url=init_urls+‘/‘+n
print url
yield Request(url,callback=self.parse)
对于自动爬取网页scrapy有个更方便的方法:CrawlSpider
前面介绍到的Spider中只能解析在start_urls中的网页。虽然在上一章也实现了自动爬取的规则。但略显负责。在scrapy中可以用CrawlSpider来进行网页的自动爬取。
爬取的规则原型如下:
classscrapy.contrib.spiders.Rule(link_extractor, callback=None, cb_kwargs=None, follow=None,process_links=None, process_request=None)
LinkExtractor.:它的作用是定义了如何从爬取到的的页面中提取链接
Callback指向一个调用函数,每当从LinkExtractor获取到链接时将调用该函数进行处理,该回调函数接受一个response作为第一个参数。注意:在用CrawlSpider的时候禁止用parse作为回调函数。因为CrawlSpider使用parse方法来实现逻辑,因此如果使用parse函数将会导致调用失败
Follow是一个判断值,用来指示从response中提取的链接是否需要跟进
在scrapy shell中提取www.sina.com.cn为例

LinkExtractor中的allow只针对href属性:
例如下面的链接只针对href属性做正则表达式提取
结构如下:可以得到各个链接。
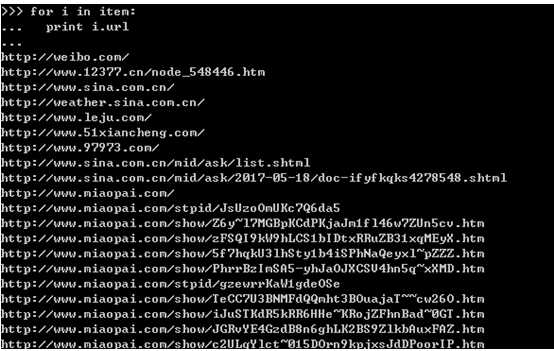
可以通过restrict_xpaths对各个链接加以限制,如下的方法:

实例2:还是以之前的迅读网为例
提取网页中的下一节的地址:
网页地址:
http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/1.shtml
下一页的的相对URL地址为2.shtml。
通过如下规则提取出来
>>> item=LinkExtractor(allow=(‘\d\.shtml‘)).extract_links(response)
>>> for i in item:
... print i.ur
...
http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/2.shtml

也通过导航页面直接获取所有章节的链接:
C:\Users\Administrator>scrapy shell http://www.xunread.com/article/8c39f5a0-ca54
-44d7-86cc-148eee4d6615/index.shtml
from scrapy.linkextractors import LinkExtractor
>>> item=LinkExtractor(allow=(‘\d\.shtml‘)).extract_links(response)
>>> for i in item:
... print i.url
得到如下全部的链接
那么接下来构造在scrapy中的代码,如下
class testSpider(CrawlSpider):
name="test1"
allowd_domains=[‘http://www.xunsee.com‘]
start_urls=["http://www.xunsee.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/1.shtml"]
rules=(Rule(LinkExtractor(allow=(‘\d\.shtml‘)),callback=‘parse_item‘,follow=True),)
print rules
def parse_item(self, response):
print response.url
sel=Selector(response)
context=‘‘
content=sel.xpath(‘//div[@id="content_1"]/text()‘).extract()
for c in content:
context=context+c.encode(‘utf-8‘)
items=Test1Item()
items[‘content‘]=context
yield items
关键的是rules=(Rule(LinkExtractor(allow=(‘\d\.shtml‘)),callback=‘parse_item‘,follow=True),) 这个里面规定了提取网页的规则。以上面的例子为例。爬取的过程分为如下几个步骤:
1 从http://www.xunsee.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/1.shtml开始,第一调用parse_item,用xpath提取网页内容,然后用Rule提取网页规则,在这里提取到2.shtml。
2 进入2.shtml.进入2.shtml后再重复运行第一步的过程。直到Rules中提取不到任何规则
我们也可以做一下优化,设置start_urls为页面索引页面
http://www.xunsee.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/index.shtml
这样通过Rule可以一下提取出所有的链接。然后对每个链接调用parse_item进行网页信息提取。这样的效率比从1.shtml要高效很多。
标签:小说 raw url 不同的 close lines 处理 .sh html
原文地址:http://www.cnblogs.com/zhanghongfeng/p/7076160.html