标签:中文 close 分数 info 帮助 rbo 迭代 管理系 sub
1.层次化查询select level,ttt.*,sys_connect_by_path(ttt.col1,‘,‘) from ttt start with .. Connect by prior …
因为先建立树,再进行where过滤的。在where中过滤和在cooonect by中过滤是不一样的。
2.rollup cube高级查询 select grouping(col1) .. From ttt group by rollup/cube(col1,col2),这里的select中只能使用col1,col2 和统计函数,和不用rollup一样,只是数据多了关于分组的统计信息。
3.not in 和 =<> + all应该注意null值
帮助列表
具体项目的帮助
INSERT ALL
WHEN order_total < 100000 THEN
INTO small_orders
WHEN order_total > 100000 AND order_total < 200000 THEN
INTO medium_orders
ELSE
INTO large_orders
SELECT order_id, order_total, sales_rep_id, customer_id
FROM orders;
INSERT FIRST
WHEN ottl < 100000 THEN
INTO small_orders
VALUES(oid, ottl, sid, cid)
WHEN ottl > 100000 and ottl < 200000 THEN
INTO medium_orders
VALUES(oid, ottl, sid, cid)
WHEN ottl > 290000 THEN
INTO special_orders
WHEN ottl > 200000 THEN
INTO large_orders
VALUES(oid, ottl, sid, cid)
SELECT o.order_id oid, o.customer_id cid, o.order_total ottl,
o.sales_rep_id sid, c.credit_limit cl, c.cust_email cem
FROM orders o, customers c
WHERE o.customer_id = c.customer_id;
MERGE INTO bonuses D
USING (SELECT employee_id, salary, department_id FROM employees
WHERE department_id = 80) S
ON (D.employee_id = S.employee_id)
WHEN MATCHED THEN UPDATE SET D.bonus = D.bonus + S.salary*.01
DELETE WHERE (S.salary > 8000)
WHEN NOT MATCHED THEN INSERT (D.employee_id, D.bonus)
VALUES (S.employee_id, S.salary*0.1)
WHERE (S.salary <= 8000);
1.sql执行步骤:
验证--->查询转换--->确定执行计划--->执行sql并取得结果
2.查询转换 /*+ no_query_transformation */
视图合并(在select中是视图) /*+ no_merge */
子查询解嵌套(在where中是子查询) /*+ no_unnest */
谓语前推(最常用 最好用)
利用物化视图进行查询重写
3. 对于这几种的控制,大部分情况下谓语前推肯定是要允许的,试图合并也是应该的,子查询解嵌套的应用场景较少,只在子查询保证关联列的唯一性的时候才可使用,否则会影响结果的行数。物化视图没用过,不过如果有物化视图,进行重写肯定不应该禁止的。
1.全表扫描或者索引扫描
2.数据块是最小单元 一张表的高水位线是最后一块有数据写入的数据块
删除了部分数据之后,高水位线不会立刻跌落到删除后的位置。但是执行全表扫描时,将会一直扫描到高水位线处为止,可能包含空白数据。所以说如果执行了大数据的删除,最还重新对表生成统计信息。
3.获取表分配的数据块数:
select blocks from user_segments where segment_name = ‘@table_name‘
4.获取实际的有数据的数据数据块数:
select count(distinct dbms_rowid.rowid_block_number(rowid)) from table_name;
5.索引的聚簇因子 索引代表的列的不同值在数据块中的分布情况 紧凑还是稀疏 越紧凑越适合使用索引扫描方式 聚簇因子代表数据的存储分布情况 重建索引不能改变据簇因子的值
联接方法:
嵌套循环联接:nested loops 特点:如果有一张表的数据较少可以作为驱动表的话 适合使用这种联接
排序合并联接:sort join merge join 特点排序的开销比较大,如果表过大的话,在使用内存的同时会使用临时磁盘空间,所以对资源比较消耗,但是 如果两张表比较大 而且联接条件是非等式的时候,这种联接就是唯一的选择了。
散列联接:hash join 特点:两张表都比较大 并且是等联接的情况下,使用这个。
笛卡尔联接。
一大一小:嵌套循环
两个都大的等连:散列连接
两个都打的不等连接:排序合并
1.面向集合的角度思考问题
2.执行计划中的filter操作
执行过滤操作
如果filter下面针对的是一张表,那么就是简单的过滤
如果filter下面针对的是两张表,那么就是以第一张表为驱动表,驱动表中的每一行,都要执行第二张表(内层表)的查询一次,效率极低。这种情况一般用在in,exist的关联子查询并且无法解嵌套的情况。
3.union minus intersect操作都会默认执行类似distinct一样的去除重复行的操作。Union all不会。
4.在集合操作(union minus intersect)和group by操作中,null会作为一个特定的值来运算,在这些操作中null = null。
5.在sum avg count中将忽略null。
概括:对某个区间(全表 partition by之后的分组 自定义的窗口)执行row_number sum count min max avg first_value last_value
lag lead等操作。可以获得区间的行号,前几个后几个的值,第一个最后一个的值,sum等统计信息。
以下示例中红色是可选的
1.row_number函数 不接受参数 返回行号
select row_number() over (partition by col1 order by col2) from table_name;
如果有group by,将会先执行group by,在执行窗口操作,那么col1和col2必须是group by之后可以出现在select中的有效列。
2.窗口函数:窗口函数是在一个自定义的"窗口"中执行sum count min max avg first_value last_value等函数,这些函数都要传递一个列名作为参数。
定义窗口:
partition by col2 order by col1 rows between (current row)/(unbounded/123.. preceding) and (current row)/(unbounded/123.. following)
例如:
select sum(col1) over (order by col2 rows between unbounded preceding and current row) from table_name;
3.报表函数:对partition by的结果集执行sum count min max avg。这和group by的效果是一样的,只不过group by限制结果集中只能包含group by的列和sum count等列。而报表函数能够打破这个限制。例如:
select s.*,sum(s.col1) over(partiton by s.col2),sum(s.col3) over(partiton by s.col4) from table_name s;
4.lag和lead 获取前面第n个的值 或者 后面第n个的值 不能用在窗口函数中,只能over(partition by col2 order by col1)
例如:
select lead(col1) over (order by col2) from table_name;
如何获取实际的执行计划:
select /*+ gather_plan_statistics pub_organ_sig */ * from pub_organ o where o.organ_code like ‘2562%‘;
select * from v$sql s where s.SQL_TEXT like ‘%pub_organ_sig%‘
select * from table(dbms_xplan.display_cursor(‘2cg64wudvfkr6‘,null,‘ALLSTATS LAST -COST -BYTES‘));
PLAN_TABLE_OUTPUT |
SQL_ID 2cm7ax09dcpjf, child number 0 |
------------------------------------- |
select /*+ gather_plan_statistics pub_organ_sig */ * from pub_organ o where |
o.organ_code like ‘2562%‘ |
|
Plan hash value: 33305308 |
|
----------------------------------------------------------------------------------------- |
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | |
----------------------------------------------------------------------------------------- |
|* 1 | TABLE ACCESS FULL| PUB_ORGAN | 1 | 2 | 0 |00:00:00.01 | 240 | |
----------------------------------------------------------------------------------------- |
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
1 - filter("O"."ORGAN_CODE" LIKE ‘2562%‘) |
|
E-Rows : expect rows 预测的行
A-Rows : actual rows 实际的行
如果A-Rows比E-Rows小的多,那么需要重新生成统计信息。
重新生成统计信息:
在命令窗口中执行: EXEC dbms_stats.gather_table_stats(user,‘PUB_ORGAN‘,estimate_percent => 100, cascade => TRUE,method_opt => ‘FOR ALL COLUMNS SIZE 1‘);
begin dbms_stats.gather_table_stats方法:
This procedure gathers table and column (and index) statistics. It attempts to
parallelize as much of the work as possible, but there are some restrictions as
described in the individual parameters.
DBMS_STATS.GATHER_TABLE_STATS (
partname VARCHAR2 DEFAULT NULL,
estimate_percent NUMBER DEFAULT to_estimate_percent_type
(get_param(‘ESTIMATE_PERCENT‘)),
block_sample BOOLEAN DEFAULT FALSE,
method_opt VARCHAR2 DEFAULT get_param(‘METHOD_OPT‘),
degree NUMBER DEFAULT to_degree_type(get_param(‘DEGREE‘)),
granularity VARCHAR2 DEFAULT GET_PARAM(‘GRANULARITY‘),
cascade BOOLEAN DEFAULT to_cascade_type(get_param(‘CASCADE‘)),
stattab VARCHAR2 DEFAULT NULL,
statown VARCHAR2 DEFAULT NULL,
no_invalidate BOOLEAN DEFAULT to_no_invalidate_type (
running the GATHER_INDEX_STATS Procedure on each of th
table‘s indexes. Use the constant DBMS_STATS.AUTO_
CASCADE to have Oracle determine whether index statistics to
be collected or not. This is the default. The default value can b
changed using theSET_PARAM Procedure.
■ FOR ALL [INDEXED | HIDDEN] COLUMNS [size_
■ FOR COLUMNS [size clause] column|attribut
[size_clause] [,column|attribute [size_
size_clause is defined as size_clause := SIZ
{integer | REPEAT | AUTO | SKEWONLY}
- integer : Number of histogram buckets. Must be in the
- REPEAT : Collects histograms only on the columns that
- AUTO : Oracle determines the columns to collect histogram
based on data distribution and the workload of the columns
- SKEWONLY : Oracle determines the columns to collect
histograms based on the data distribution of the columns.
The default is FOR ALL COLUMNS SIZE AUTO.The defaul
value can be changed using the SET_PARAM Procedure.
group by z.zyear, z.zmonth, z.jxzbid
order by z.zyear, z.zmonth, z.jxzbid
first_value(count(1)) over(order by z.zyear, z.zmonth, z.jxzbid)
group by z.zyear, z.zmonth, z.jxzbid
order by z.zyear, z.zmonth, z.jxzbid
lag(count(1),1) over(order by z.zyear, z.zmonth, z.jxzbid)
group by z.zyear, z.zmonth, z.jxzbid
order by z.zyear, z.zmonth, z.jxzbid
如果没有上一个,lag取出来为空,而first_value取出来为当前行的值。
count(1) over(partition by z.zyear),--当前年有多少条
count(1) over(partition by z.zmonth),--当前月有多少条
count(1) over(partition by z.jxzbid)--当前指标有多少条
order by z.zyear, z.zmonth, z.jxzbid
PLAN_TABLE_OUTPUT |
SQL_ID ab4nygf153qa5, child number 0 |
------------------------------------- |
with max_v as (select /*+ gather_plan_statistics zjf_flag */ t.zyear, t.zmonth, max(t.bndywcz) |
over(partition by t.zyear order by t.zmonth) from Z00HRJDWWCZ t) select * from max_v v where v.zyear = |
‘2011‘ and v.zmonth = ‘2‘ |
|
Plan hash value: 1995484584 |
|
------------------------------------------------------------------------------------------------------------------------ |
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | O/1/M | |
------------------------------------------------------------------------------------------------------------------------ |
|* 1 | VIEW | | 1 | 4053 | 100 |00:00:00.01 | 38 | | | | |
| 2 | WINDOW SORT | | 1 | 4053 | 1981 |00:00:00.01 | 38 | 160K| 160K| 1/0/0| |
|* 3 | TABLE ACCESS FULL| Z00HRJDWWCZ | 1 | 4053 | 4053 |00:00:00.01 | 38 | | | | |
------------------------------------------------------------------------------------------------------------------------ |
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
1 - filter("V"."ZMONTH"=‘2‘) |
3 - filter("T"."ZYEAR"=‘2011‘) |
|
filter("V"."ZMONTH"=‘2‘)操作是在window操作之后执行的,没有执行谓语前推。此种情况下ZMONTH的索引也不会被使用到。
PLAN_TABLE_OUTPUT |
SQL_ID arcp0y6pauqmc, child number 0 |
------------------------------------- |
select /*+ gather_plan_statistics zjf_flag */ * from pub_functions s where |
s.function_name like ‘%YJKH%‘ or exists (select null from pub_resources f where |
s.function_id = f.function_id) |
|
Plan hash value: 21887211 |
|
---------------------------------------------------------------------------------------------- |
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | |
---------------------------------------------------------------------------------------------- |
|* 1 | FILTER | | 1 | | 100 |00:00:00.01 | 1297 | |
| 2 | TABLE ACCESS FULL| PUB_FUNCTIONS | 1 | 383 | 102 |00:00:00.01 | 5 | |
|* 3 | TABLE ACCESS FULL| PUB_RESOURCES | 102 | 2 | 100 |00:00:00.01 | 1292 | |
---------------------------------------------------------------------------------------------- |
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
1 - filter(("S"."FUNCTION_NAME" LIKE ‘%YJKH%‘ OR IS NOT NULL)) |
3 - filter("F"."FUNCTION_ID"=:B1) |
|
使用(不加not的)in 还是exists,对于性能不会有影响。oralce会根据查询的特点,自动选择半连接,如果不能选择半连接,就使用filter,但这跟in或者exists的取舍已经无关了。
PLAN_TABLE_OUTPUT |
SQL_ID as36cfwft7khf, child number 0 |
------------------------------------- |
select /*+ gather_plan_statistics zjf_flag1 */ * from pub_functions s where |
s.function_id not in (select f.function_id from pub_resources f ) |
|
Plan hash value: 21887211 |
|
---------------------------------------------------------------------------------------------- |
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | |
---------------------------------------------------------------------------------------------- |
|* 1 | FILTER | | 1 | | 8 |00:00:00.03 | 9572 | |
| 2 | TABLE ACCESS FULL| PUB_FUNCTIONS | 1 | 383 | 376 |00:00:00.01 | 7 | |
|* 3 | TABLE ACCESS FULL| PUB_RESOURCES | 376 | 2 | 368 |00:00:00.03 | 9565 | |
---------------------------------------------------------------------------------------------- |
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
1 - filter( IS NULL) |
3 - filter(LNNVL("F"."FUNCTION_ID"<>:B1))
|
create index pub_functions_inx_subname on pub_functions(substr(function_name,1,1))
PLAN_TABLE_OUTPUT |
SQL_ID 6q1h79t54h0dd, child number 0 |
------------------------------------- |
select /*+ gather_plan_statistics zjf_flag */ * from pub_functions s where |
s.function_name is null |
|
Plan hash value: 2496286864 |
|
------------------------------------------------------------------------------------ |
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | |
------------------------------------------------------------------------------------ |
|* 1 | FILTER | | 1 | | 0 |00:00:00.01 | |
| 2 | TABLE ACCESS FULL| PUB_FUNCTIONS | 0 | 383 | 0 |00:00:00.01 | |
------------------------------------------------------------------------------------ |
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
1 - filter(NULL IS NOT NULL) |
|
Connection conn = ds.getConnection();
每次执行executeUpdate都会自动触发commit操作,所以第二个报错,第一个仍然后执行成功。
也就是说如果不加conn.setAutoCommit(false);,那么每条sql都是一个事务。
update pub_organ o set o.organ_name = ‘1‘ where o.organ_id = ‘O50649824‘; --事务开始第一个可执行语句
update pub_organ o set o.organ_name = ‘2‘ where o.organ_id = ‘O50649824‘; --新事务开始
update pub_organ o set o.in_use = ‘ddd0‘ where o.organ_id = ‘O50649824‘;--此处会报错 rollback
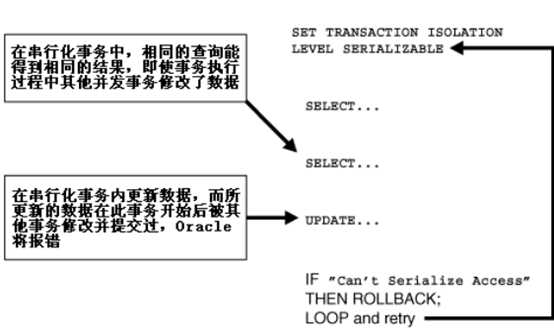
获取表的共享锁:
lock
table pub_organ in
share
mode;;锁定整张表 其他用户不可以执行dml操作,但是也可以获取共享锁。
不管是那种模式,lock table的代码就像一句update的代码一样,遇到commit或者rollback后才会解除lock。如果表中的某一行被更新未提交,或者插入为提交,那么lock操作将阻塞。
方法1 PLAN_TABLE_OUTPUT |
SQL_ID 597rg6z4t563b, child number 0 |
------------------------------------- |
delete /*+ gather_plan_statistics zjf_flag */ from pub_organ o where rowid not in (select max(rowid) from |
pub_organ o1 group by o1.organ_name) |
|
Plan hash value: 1304593988 |
|
-------------------------------------------------------------------------------------------------------------------------- |
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | O/1/M | |
-------------------------------------------------------------------------------------------------------------------------- |
| 1 | DELETE | PUB_ORGAN | 2 | | 0 |00:00:00.06 | 5039 | | | | |
|* 2 | HASH JOIN RIGHT ANTI| | 2 | 2014 | 4028 |00:00:00.09 | 426 | 985K| 985K| 2/0/0| |
| 3 | VIEW | VW_NSO_1 | 2 | 10665 | 21330 |00:00:00.10 | 352 | | | | |
| 4 | SORT GROUP BY | | 2 | 10665 | 21330 |00:00:00.04 | 352 | 604K| 489K| 2/0/0| |
| 5 | TABLE ACCESS FULL| PUB_ORGAN | 2 | 12679 | 25358 |00:00:00.04 | 352 | | | | |
| 6 | INDEX FULL SCAN | PUBORGAN_PK | 2 | 12679 | 25358 |00:00:00.03 | 74 | | | | |
-------------------------------------------------------------------------------------------------------------------------- |
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
|
|
方法2 PLAN_TABLE_OUTPUT | |||||||||||||||||||||||||
SQL_ID bud1rjjndxukr, child number 0 | |||||||||||||||||||||||||
------------------------------------- | |||||||||||||||||||||||||
delete /*+ gather_plan_statistics zjf_flag */ from pub_organ o where exists (select null from pub_organ o1 | |||||||||||||||||||||||||
where o.organ_name = o1.organ_name and o.rowid > o1.rowid) | |||||||||||||||||||||||||
| |||||||||||||||||||||||||
Plan hash value: 3527544481 | |||||||||||||||||||||||||
| |||||||||||||||||||||||||
------------------------------------------------------------------------------------------------------------------------ | |||||||||||||||||||||||||
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | O/1/M | | |||||||||||||||||||||||||
------------------------------------------------------------------------------------------------------------------------ | |||||||||||||||||||||||||
| 1 | DELETE | PUB_ORGAN | 2 | | 0 |00:00:00.09 | 13238 | | | | | |||||||||||||||||||||||||
|* 2 | HASH JOIN RIGHT SEMI| | 2 | 634 | 4028 |00:00:00.04 | 704 | 1191K| 1059K| 2/0/0| | |||||||||||||||||||||||||
| 3 | TABLE ACCESS FULL | PUB_ORGAN | 2 | 12679 | 25358 |00:00:00.04 | 352 | | | | | |||||||||||||||||||||||||
| 4 | TABLE ACCESS FULL | PUB_ORGAN | 2 | 12679 | 25358 |00:00:00.04 | 352 | | | | | |||||||||||||||||||||||||
------------------------------------------------------------------------------------------------------------------------ | |||||||||||||||||||||||||
| |||||||||||||||||||||||||
Predicate Information (identified by operation id): | |||||||||||||||||||||||||
--------------------------------------------------- | |||||||||||||||||||||||||
| |||||||||||||||||||||||||
2 - access("O"."ORGAN_NAME"="O1"."ORGAN_NAME") | |||||||||||||||||||||||||
filter("O1".ROWID<"O".ROWID) | |||||||||||||||||||||||||
|
| PLAN_TABLE_OUTPUT |
1 | SQL_ID gp7kzxzjfwx37, child number 0 |
2 | ------------------------------------- |
3 | select /*+ gather_plan_statistics zjf_flag */ o.organ_name,o.organ_code from |
4 | pub_organ o group by o.organ_name,o.organ_code |
5 |
|
6 | Plan hash value: 647668416 |
7 |
|
8 | ------------------------------------------------------------------------------------------ |
9 | | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | |
10 | ------------------------------------------------------------------------------------------ |
11 | | 1 | HASH GROUP BY | | 1 | 12679 | 100 |00:00:00.01 | 176 | |
12 | | 2 | TABLE ACCESS FULL| PUB_ORGAN | 1 | 12679 | 12679 |00:00:00.01 | 176 | |
13 | ------------------------------------------------------------------------------------------ |
14 |
|
| PLAN_TABLE_OUTPUT |
1 | SQL_ID d3q8bz6h4msgg, child number 0 |
2 | ------------------------------------- |
3 | select /*+ gather_plan_statistics zjf_flag */ distinct |
4 | o.organ_name,o.organ_code from pub_organ o |
5 |
|
6 | Plan hash value: 4103017490 |
7 |
|
8 | ------------------------------------------------------------------------------------------ |
9 | | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | |
10 | ------------------------------------------------------------------------------------------ |
11 | | 1 | HASH UNIQUE | | 1 | 12679 | 100 |00:00:00.01 | 176 | |
12 | | 2 | TABLE ACCESS FULL| PUB_ORGAN | 1 | 12679 | 12679 |00:00:00.03 | 176 | |
13 | ------------------------------------------------------------------------------------------ |
14 |
|
这两种那个快还真不知道,不过是distinct不是group by还是用distinct的好,毕竟group by要分组,应该有耗费。
(select name1 from zjf_test2 where zjf_test1.id1 = zjf_test2.id1);
update (select zjf_test1.name1, zjf_test2.name1 name_new
where zjf_test1.id1 = zjf_test2.id1)
--如果id1不是主键 上面写法将会报错 但是下面这种写法不会报错
on (zjf_test1.id1 = zjf_test2.id1)
update set zjf_test1.name1 = zjf_test2.name1;
标签:中文 close 分数 info 帮助 rbo 迭代 管理系 sub
原文地址:http://www.cnblogs.com/xiaolang8762400/p/7078686.html