标签:cal 一个 recent 位置 优先 nbsp 编写 match error
正则表达式
就其本质而言,正则表达式(或 re)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
字符匹配(普通字符,元字符):
1 普通字符(完全匹配):大多数字符和字母都会和自身匹配
1 >>> import re 2 >>> res=‘hello world good morning‘ 3 >>> re.findall(‘hello‘,res) 4 [‘hello‘]
2 元字符(模糊匹配):. ^ $ * + ? { } [ ] | ( ) \
元字符
. 通配符,匹配一个除了换行符的任意字符,中间如果有换行符也不会跳过换行符,只是无法匹配
1 >>> import re 2 >>> str1="hello\n,张三" 3 #re.findall()方法,第一个元素为匹配规则,第二个元素为字符串,返回的是所有匹配项的列表,re下的方法后面详细说明 4 >>> re.findall("l",str1) #遍历匹配l,如果匹配到,则输出为列表的一个元素 5 [‘l‘, ‘l‘] 6 >>> re.findall("h.",str1) #匹配h开头,后面包含任意字符除换行符的两个字符 7 [‘he‘] 8 >>> re.findall("hello.",str1) #因为hello后的字符是换行符,所以匹配不到 9 [] 10 >>> re.findall("张.",str1) #包含的字符串在哪个位置匹配都可以 11 [‘张三‘]
^ 开始匹配,只匹配字符串的开头,开头如果没有,后边不会再进行匹配
1 >>> re.findall("^hello",str1) #开头有hello所以匹配成功 2 [‘hello‘] 3 >>> re.findall("^llo",str1) #开头没有llo,匹配失败 4 []
$ 结尾匹配,只匹配结尾
1 >>> re.findall("llo$",str1) #该字符串以三结尾 2 [] 3 >>> re.findall("三$",str1) 4 [‘三‘] 5 >>> re.findall("张三$",str1) #可匹配多个字符 6 [‘张三‘] 7 >>> re.findall("张.$",str1) #不同的元字符联用 8 [‘张三‘]
重复功能元字符
? 表示?前一个字符或组可有可无,范围即0次或1次
1 >>> re.findall("ho?el",str1) #o可有可无,匹配hel 2 [‘hel‘] 3 >>> re.findall("he?l",str1) #e可有可无,有的时候匹配hel 4 [‘hel‘] 5 >>> re.findall("he?el",str1) #第一个e可有可无,没有的时候匹配hel 6 [‘hel‘]
* 表示*前面一个字符或组的重复范围,范围从0开始到正无穷,[0,+∞]
1 >>> str2="111111133111188211111111111134234" 2 >>> re.findall("1*",str2) #1*表示字符1出现0次或多次,从字符串依次匹配,如果不是1就用空补全 3 [‘1111111‘, ‘‘, ‘‘, ‘1111‘, ‘‘, ‘‘, ‘‘, ‘111111111111‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘] 4 >>> re.findall("11*",str2) #11*表示第二个字符1出现0次或多次,第一个字符1已经固定 5 [‘1111111‘, ‘1111‘, ‘111111111111‘]
+ 类似与*,表示+前面一个字符或组的重复范围,范围从1开始到正无穷,[1,+∞]
1 >>> re.findall("11+",str2) #11+表示第二个1必须是出现1次或多次 2 [‘1111111‘, ‘1111‘, ‘111111111111‘] 3 >>> re.findall("1+",str2) #1+表示必须出现一次1及以上 4 [‘1111111‘, ‘1111‘, ‘111111111111‘]
{} {n,m},指定范围,不指定m表示从n到无穷,只有一个n是只能是这么多次
1 >>> str2="111111133111188211111111111134234" 2 >>> re.findall("1{4}",str2) #按照字符1重复4次匹配,共匹配成功5次 3 [‘1111‘, ‘1111‘, ‘1111‘, ‘1111‘, ‘1111‘] 4 >>> re.findall("3{2}",str2) #匹配出现2次3的字符串 5 [‘33‘] 6 >>> re.findall("3{1,3}",str2) #匹配出现1到3次3的情况 7 [‘33‘, ‘3‘, ‘3‘] 8 >>> re.findall("1{1,}",str2) #匹配出现1至少一次的情况 9 [‘1111111‘, ‘1111‘, ‘111111111111‘]
转义字符
\ 反斜杠后边跟元字符去除特殊功能,反斜杠后边跟普通字符实现特殊功能
\d 匹配任何十进制数; 它相当于类 [0-9]。 \D 匹配任何非数字字符; 它相当于类 [^0-9]。 \s 匹配任何空白字符; 它相当于类 [ \t\n\r\f\v]。 \S 匹配任何非空白字符; 它相当于类 [^ \t\n\r\f\v]。 \w 匹配任何字母数字汉字字符; 它相当于类 [a-zA-Z0-9_]。 \W 匹配任何非字母数字汉字字符; 它相当于类 [^a-zA-Z0-9_] \b 匹配一个特殊字符边界,比如空格 ,&,#等
字符串:包含特殊字符、数字、大小写字母及汉字
1 >>> str3=‘123456 7890@#$abcd efg!%&*HIJKLMN陈‘
\d 匹配十进制数
1 >>> re.findall("\d",str3) 2 [‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘, ‘7‘, ‘8‘, ‘9‘, ‘0‘]
\D 匹配非数字字符
1 >>> re.findall("\D",str3) 2 [‘ ‘, ‘ ‘, ‘@‘, ‘#‘, ‘$‘, ‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘ ‘, ‘ ‘, ‘e‘, ‘f‘, ‘g‘, ‘!‘, ‘%‘, ‘&‘, ‘*‘, ‘H‘, ‘I‘, ‘J‘, ‘K‘, ‘L‘, ‘M‘, ‘N‘, ‘陈‘]
\s 匹配任何空白字符
>>> re.findall("\s",str3) [‘ ‘, ‘ ‘, ‘ ‘, ‘ ‘]
\S 匹配任何非空白字符
1 >>> re.findall("\S",str3) 2 [‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘, ‘7‘, ‘8‘, ‘9‘, ‘0‘, ‘@‘, ‘#‘, ‘$‘, ‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘, ‘f‘, ‘g‘, ‘!‘, ‘%‘, ‘&‘, ‘*‘, ‘H‘, ‘I‘, ‘J‘, ‘K‘, ‘L‘, ‘M‘, ‘N‘, ‘陈‘]
\w 匹配任何字母数字汉字字符
1 >>> re.findall("\w",str3) 2 [‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘, ‘7‘, ‘8‘, ‘9‘, ‘0‘, ‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘, ‘f‘, ‘g‘, ‘H‘, ‘I‘, ‘J‘, ‘K‘, ‘L‘, ‘M‘, ‘N‘, ‘陈‘]
\W 匹配任何非字母数字汉字字符
1 >>> re.findall("\W",str3) 2 [‘ ‘, ‘ ‘, ‘@‘, ‘#‘, ‘$‘, ‘ ‘, ‘ ‘, ‘!‘, ‘%‘, ‘&‘, ‘*‘]
\b 匹配一个特殊的字符边界,注意:因为\b和py解释器有冲突,所以需要加上r表示以源生字符方式传送给re模块解释
1 >>> re.findall(r"abcd\b",str3) 2 [‘abcd‘] 3 >>> re.findall(r"123456\b",str3) 4 [‘123456‘]
源生字符r示例1:匹配“abc\le”中的‘c\l’,\l无特殊含义
1 >>> import re 2 >>> str4="abc\le" 3 >>> re.findall(‘c\l‘,‘abc\le‘) #报错,py解释器会解释一次转义字符,一个\无法解释 4 >>> re.findall(‘c\\l‘,‘abc\le‘) #报错,py解释器将两个\解释成一个\传给re模块,re模块
5 >>> re.findall(‘c\\\l‘,‘abc\le‘) #py解释器将三个\解释成\\传给re模块,re模块解释\\转义匹配c\l 6 [‘c\\l‘] #因为匹配出来的c\l的\是特殊字符,所以py解释器将\转义一次输出 7 >>> re.findall(‘c\\\\l‘,‘abc\le‘) #py解释器将第一个和第二个\解释成一个\,第三个第四个\解释成一个\,共两个\传给re模块 8 [‘c\\l‘] 9 >>> re.findall(r‘c\\l‘,‘abc\le‘) #py解释器通过r标识,将两个\解释为源生字符直接传给re模块 10 [‘c\\l‘]
源生字符r示例2:匹配“abc\be”中的‘c\b’,\b有特殊含义,为ascii表的退格
1 >>> str5="abc\be" 2 >>> re.findall(‘c\b‘,‘abc\be‘) 3 [‘c\x08‘] 4 >>> re.findall(‘c\\b‘,‘abc\be‘) 5 [‘c‘] 6 >>> re.findall(‘c\\\b‘,‘abc\be‘) 7 [‘c\x08‘] 8 >>> re.findall(‘c\\\\b‘,‘abc\be‘) 9 [] 10 >>> re.findall(r‘c\b‘,‘abc\be‘) 11 [‘c‘] 12 >>> re.findall(r‘c\\b‘,‘abc\be‘) 13 [] 14 >>> re.findall(r‘c\\\b‘,‘abc\be‘) 15 [] 16 >>> re.findall(r‘c\\\\b‘,‘abc\be‘) 17 [] 18 >>> re.findall(r‘c\b‘,r‘abc\be‘) 19 [‘c‘] 20 >>> re.findall(r‘c\\b‘,r‘abc\be‘) #当字符串内有特殊含义的字符时候,需要加r转义为源生字符 21 [‘c\\b‘] 22 >>> re.findall(r‘c\\\b‘,r‘abc\be‘) 23 [‘c\\‘] 24 >>> re.findall(r‘c\\\\b‘,r‘abc\be‘) 25 []
() 分为普通分组和命名分组两种,和的意思,匹配规则的字符串以组的方式划成一个整体,这个整体赋规则匹配字符串
1 >>> str6="faefhuknghellohellohelloafeahelloadf" 2 >>> re.findall("(hello)+",str6) #将hello组成一个整体进行+规则 3 [‘hello‘, ‘hello‘] #因为优先级的限制,只能显示分组内的内容 4 >>> re.findall("(?:hello)+",str6) 5 [‘hellohellohello‘, ‘hello‘] #?:是一个格式,取消优先级限制,将匹配到的所有显示出来
分组一般配合re.search()和re.match()方法调用
re.search()格式和findall相同,但是其返回的是一个对象,通过调用对象的group方法返回具体的值,re.search()只会匹配一次值,匹配到之后将不再向后匹配,即只有一个结果。
1 >>> re.search("(hello)+",str6) 2 <_sre.SRE_Match object; span=(9, 24), match=‘hellohellohello‘> 3 >>> ret=re.search("(hello)+",str6) 4 >>> ret.group() 5 ‘hellohellohello‘
re.match()方法和元字符^的功能类似,匹配字符串开头,返回一个对象,并且也能通过group方法返回具体的值
1 >>> str7="hellohellohellonameafeahelloadf" 2 >>> ret=re.match("(hello)+",str7) #开头有hello能匹配到 3 >>> ret.group() 4 ‘hellohellohello‘ 5 >>> ret=re.match("(name)+",str7) #开头没有name,匹配不到 6 >>> ret.group() 7 Traceback (most recent call last): 8 File "<stdin>", line 1, in <module> 9 AttributeError: ‘NoneType‘ object has no attribute ‘group‘
命名分组:在分组的基础上加上一个名字,通过group方法调用分组名字返回具体的值
1 >>> str8="-blog-aticles-2015-04" 2 >>> ret=re.search(r"-blog-aticles-(?P<year>\d+)-(?P<month>\d+)",str8) #?P是定义命名的格式,<>内是名字 3 >>> ret.group(‘year‘) 4 ‘2015‘ 5 >>> ret.group(‘month‘) 6 ‘04‘
[] 字符集,中括号内的字符集合,关系为或,即匹配括号内任意一个字符即可,字符集内的-^\三个字符具有特殊意义,其他字符丧失原来的特殊意义。
1 >>> str9="adf13415aggae8657dfc" 2 >>> re.findall("a[dg]+",str9) #匹配a开头,后面多余一个d或者g结尾的部分 3 [‘ad‘, ‘agg‘]
字符集内的-表示一个范围
1 >>> re.findall("[0-9]+",str9) #包含0-9数字的字符,匹配+规则 2 [‘13415‘, ‘8657‘] 3 >>> re.findall("[a-z]+",str9) 4 [‘adf‘, ‘aggae‘, ‘dfc‘]
字符集内的^表示取反
1 >>> re.findall("[^a-z]+",str9) #不是包含a-z字母的字符,匹配+规则 2 [‘13415‘, ‘8657‘] 3 >>> re.findall("[^0-9]+",str9) 4 [‘adf‘, ‘aggae‘, ‘dfc‘]
字符集内的\表示转义
1 >>> re.findall("[\d]",str9) 2 [‘1‘, ‘3‘, ‘4‘, ‘1‘, ‘5‘, ‘8‘, ‘6‘, ‘5‘, ‘7‘] 3 >>> re.findall("[\w]",str9) 4 [‘a‘, ‘d‘, ‘f‘, ‘1‘, ‘3‘, ‘4‘, ‘1‘, ‘5‘, ‘a‘, ‘g‘, ‘g‘, ‘a‘, ‘e‘, ‘8‘, ‘6‘, ‘5‘, ‘7‘, ‘d‘, ‘f‘, ‘c‘]
| 管道符号,表示或
1 >>> str10="www.oldboy.com;www.oldboy.cn;www.baidu.com;" 2 >>> re.findall("www\.(?:\w+)\.(?:com|cn)",str10) 3 [‘www.oldboy.com‘, ‘www.oldboy.cn‘, ‘www.baidu.com‘]
草稿
贪婪匹配:按照最长的结果匹配

非贪婪匹配:按照最短的结果匹配
re模块
re.findall 匹配到的全部返回,以列表的方式
re.search 返回一个对象,匹配到第一个就不往下匹配了,没匹配到返回一个None
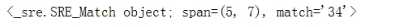
具体的内容,需要使用group方法
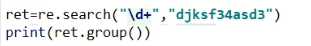
re.finditer 返回一个迭代器
也是要group方法
re.match 只在字符串开始的位置匹配

re.split() 分割,列表,中间用正则模糊匹配,可以限定次数

匹配出空
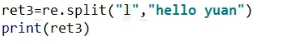
re.sub() 替换,规则-替换内容-字符串-计数限定次数
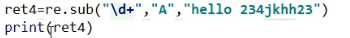
re.subn() 类似于sub,但是是元组返回
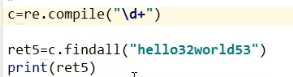
re.compile() 编译规则,用编译对象调用
标签:cal 一个 recent 位置 优先 nbsp 编写 match error
原文地址:http://www.cnblogs.com/zero527/p/7077478.html