标签:操作 不同 blog 十年 数据库 大数据 删除 log ges
一、介绍
目前大数据存储有两种方案可供选择:行存储和列存储。业界对两种存储方案有很多争持,集中焦点是:谁能够更有效地处理海量数据,且兼顾安全、可靠、完整性。从目前发展情况看,关系数据库已经不适应这种巨大的存储量和计算要求,基本是淘汰出局。在已知的几种大数据处理软件中,Hadoop的HBase采用列存储,MongoDB是文档型的行存储,Lexst是二进制型的行存储。
顾名思义,这两种数据库架构在存贮数据时的方式是大相径庭的。在行式数据库中,每一行中的每一块数据都是紧挨着另一块数据存放在硬盘中。一般情况下,你可以认为每一行存贮的内容就是硬盘中的一组连续的字节,像SQL server,Oracle,mysql等传统的是属于行式数据库范畴。如果是基于列的数据库,所有的数据都是以列的形式存储的,它从一开始就是面向大数据环境下数据仓库的数据分析而产生。
行存储数据排列
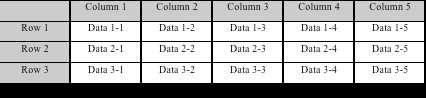
列存储数据排列
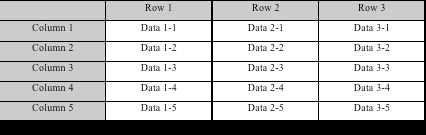
行存储的读写过程是一致的,都是从第一列开始,到最后一列结束。列存储的读取是列数据集中的一段或者全部数据,写入时,一行记录被拆分为多列,每一列数据追加到对应列的末尾处。
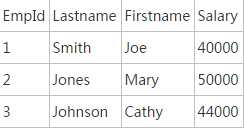
从上面表格可以看出,行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多,再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
还有数据修改,这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。 数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。列存储每次读取的数据是集合的一段或者全部,如果读取多列时,就需要移动磁头,再次定位到下一列的位置继续读取。 再谈两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
显而易见,两种存储格式都有各自的优缺点:行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
在选择使用哪种数据库时,问自己这样一个问题,哪种工作负载是你的数据库需要支持的最关键的工作负载。尽管可能你两种操作都需要,但是当核心业务是在线交易性的OLTP应用时,一个行式的数据库,再加上数十年积累的优化操作,可能是最好的选择。如果你的企业并不需要快速处理OLTP业务,但需要可以快速处理海量静态数据的分析,也就是OLAP时,那么一个列式的数据库将会成为你的不二选择。
三、总结
两种存储格式各自的特性都决定了它们不可能是完美的解决方案。 如果首要考虑是数据的完整性和可靠性,那么行存储是不二选择,列存储只有在增加磁盘并改进软件设计后才能接近这样的目标。如果以保存数据为主,行存储的写入性能比列存储高很多。在需要频繁读取单列集合数据的应用中,列存储是最合适的。如果每次读取多列,两个方案可酌情选择:采用行存储时,设计中应考虑减少或避免冗余列;若采用列存储方案,为保证读写入效率,每列数据尽可能分别保存到不同的磁盘上,多个线程并行读写各自的数据,这样避免了磁盘竞用的同时也提高了处理效率。 无论选择哪种方案,将同内容数据聚凑在一起都是必须的,这是减少磁头在磁盘上的移动,提高数据读取时间的有效办法。
其实这也验证了我当前在公司所做的系统数据库为什么是基于HBase的。因为要对用户的数据分类,对每一类数据做出对应的产品来提供服务。这个过程有在线上进行,也有在线下进行的,执行的频率相当的高,用户数量又十分庞大,虽然在数据的写入上效率会低,但是更重要的是在数据类别的维度上对大数据进行分析,实时地呈现执行结果渲染页面呈现。
标签:操作 不同 blog 十年 数据库 大数据 删除 log ges
原文地址:http://www.cnblogs.com/qiuhaojie/p/7082189.html