标签:ecc 网页 取出 data- tran ted 爬取图片 路径 refresh
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片。
下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程:
1 首先需要在一个爬虫中,获取到图片的url并存储起来。也是就是我们项目中test_spider.py中testSpider类的功能
2 项目从爬虫返回,进入到项目通道也就是pipelines中
3 在通道中,在第一步中获取到的图片url将被scrapy的调度器和下载器安排下载。
4 下载完成后,将返回一组列表,包括下载路径,源抓取地址和图片的校验码
大致的过程就以上4步,那么我们来看下代码如何具体实现
1 首先在settings.py中设置下载通道,下载路径以下载参数
ITEM_PIPELINES = {
# ‘test1.pipelines.Test1Pipeline‘: 300,
‘scrapy.pipelines.images.ImagesPipeline‘:1,
}
IMAGES_STORE =‘E:\\scrapy_project\\test1\\image‘
IMAGES_EXPIRES = 90
IMAGES_MIN_HEIGHT = 100
IMAGES_MIN_WIDTH = 100
其中IMAGES_STORE是设置的是图片保存的路径。IMAGES_EXPIRES是设置的项目保存的最长时间。IMAGES_MIN_HEIGHT和IMAGES_MIN_WIDTH是设置的图片尺寸大小
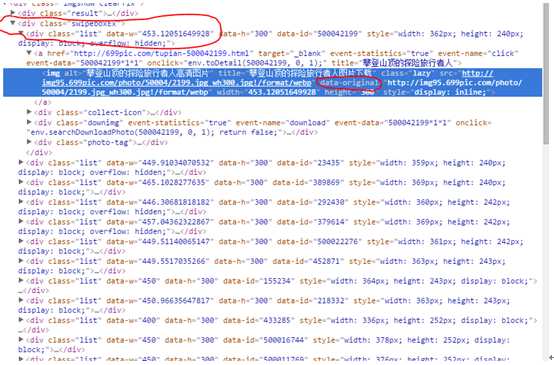
2 设置完成后,我们就开始写爬虫程序,也就是第一步获取到图片的URL。我们以http://699pic.com/people.html网站图片为例。中文名称为摄图网。里面有各种摄影图片。我们首先来看下网页结构。图片的地址都保存在
<div class=“swipeboxex”><div class=”list”><a><image>中的属性data-original
首先在item.py中定义如下几个结构体
class Test1Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls=Field()
images=Field()
image_path=Field()
根据这个网页结构,在test_spider.py文件中的代码如下。在items中保存了
class testSpider(Spider):
name="test1"
allowd_domains=[‘699pic.com‘]
start_urls=["http://699pic.com/people.html"]
print start_urls
def parse(self,response):
items=Test1Item()
items[‘image_urls‘]=response.xpath(‘//div[@class="swipeboxEx"]/div[@class="list"]/a/img/@data-original‘).extract()
return items
3 在第二步中获取到了图片url后,下面就要进入pipeline管道。进入pipeline.py。首先引入ImagesPipeline
from scrapy.pipelines.images import ImagesPipeline
然后只需要将Test1Pipeline继承自ImagesPipeline就可以了。里面可以不用写任意代码
class Test1Pipeline(ImagesPipeline):
pass
ImagesPipeline中主要介绍2个函数。get_media_requests和item_completed.我们来看下代码的实现:
def get_media_requests(self, item, info):
return [Request(x) for x in item.get(self.images_urls_field, [])]
从代码中可以看到get_meida)_requests是从管道中取出图片的url并调用request函数去获取这个url
Item_completed函数
def item_completed(self, results, item, info):
if isinstance(item, dict) or self.images_result_field in item.fields:
item[self.images_result_field] = [x for ok, x in results if ok]
return item
当下载完了图片后,将图片的路径以及网址,校验码保存在item中
下面运行代码,这里贴出log中的运行日志:
2017-06-09 22:38:17 [scrapy] INFO: Scrapy 1.1.0 started (bot: test1)
2017-06-09 22:38:17 [scrapy] INFO: Overridden settings: {‘NEWSPIDER_MODULE‘: ‘test1.spiders‘, ‘IMAGES_MIN_HEIGHT‘: 100, ‘SPIDER_MODULES‘: [‘test1.spiders‘], ‘BOT_NAME‘: ‘test1‘, ‘USER_AGENT‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36‘, ‘LOG_FILE‘: ‘log‘, ‘IMAGES_MIN_WIDTH‘: 100}
2017-06-09 22:38:18 [scrapy] INFO: Enabled extensions:
[‘scrapy.extensions.logstats.LogStats‘,
‘scrapy.extensions.telnet.TelnetConsole‘,
‘scrapy.extensions.corestats.CoreStats‘]
2017-06-09 22:38:18 [scrapy] INFO: Enabled downloader middlewares:
[‘scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware‘,
‘scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware‘,
‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware‘,
‘scrapy.downloadermiddlewares.retry.RetryMiddleware‘,
‘scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware‘,
‘scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware‘,
‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware‘,
‘scrapy.downloadermiddlewares.redirect.RedirectMiddleware‘,
‘scrapy.downloadermiddlewares.cookies.CookiesMiddleware‘,
‘scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware‘,
‘scrapy.downloadermiddlewares.stats.DownloaderStats‘]
2017-06-09 22:38:18 [scrapy] INFO: Enabled spider middlewares:
[‘scrapy.spidermiddlewares.httperror.HttpErrorMiddleware‘,
‘scrapy.spidermiddlewares.offsite.OffsiteMiddleware‘,
‘scrapy.spidermiddlewares.referer.RefererMiddleware‘,
‘scrapy.spidermiddlewares.urllength.UrlLengthMiddleware‘,
‘scrapy.spidermiddlewares.depth.DepthMiddleware‘]
2017-06-09 22:38:19 [scrapy] INFO: Enabled item pipelines:
[‘scrapy.pipelines.images.ImagesPipeline‘]
2017-06-09 22:38:19 [scrapy] INFO: Spider opened
2017-06-09 22:38:19 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-06-09 22:38:19 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-06-09 22:38:19 [scrapy] DEBUG: Crawled (200) <GET http://699pic.com/people.html> (referer: None)
2017-06-09 22:38:19 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/50004/2199.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:19 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/50004/2199.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00015/5234.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00015/5234.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/50002/2276.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/50002/2276.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00029/2430.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00029/2430.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00002/3435.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00002/3435.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00045/2871.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00045/2871.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00037/9614.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00037/9614.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00038/9869.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00038/9869.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00021/8332.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00021/8332.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/50001/6744.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/50001/6744.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00031/3314.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00031/3314.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/50006/3243.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/50006/3243.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/50000/4373.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/50000/4373.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00013/4480.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00013/4480.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00043/3285.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00043/3285.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/50001/1769.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/50001/1769.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00002/9278.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00002/9278.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00004/4944.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00004/4944.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00014/2406.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00014/2406.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00002/3437.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00002/3437.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00022/2328.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00022/2328.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00019/6796.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00019/6796.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00007/4890.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00007/4890.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/00017/0701.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/00017/0701.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Crawled (200) <GET http://img95.699pic.com/photo/50016/6025.jpg_wh300.jpg> (referer: None)
2017-06-09 22:38:20 [scrapy] DEBUG: File (downloaded): Downloaded file from <GET http://img95.699pic.com/photo/50016/6025.jpg_wh300.jpg> referred in <None>
2017-06-09 22:38:20 [scrapy] DEBUG: Scraped from <200 http://699pic.com/people.html>
{‘image_urls‘: [u‘http://img95.699pic.com/photo/50004/2199.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00002/3435.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00038/9869.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00029/2430.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00037/9614.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/50002/2276.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00045/2871.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00015/5234.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00021/8332.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00043/3285.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/50001/6744.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/50001/1769.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00031/3314.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/50006/3243.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/50000/4373.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00013/4480.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00002/9278.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00017/0701.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00022/2328.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00019/6796.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00004/4944.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/50016/6025.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00002/3437.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00014/2406.jpg_wh300.jpg‘,
u‘http://img95.699pic.com/photo/00007/4890.jpg_wh300.jpg‘],
‘images‘: [{‘checksum‘: ‘09d39902660ad2e047d721f53e7a2019‘,
‘path‘: ‘full/eb33d8812b7a06fbef2f57b87acca8cbd3a1d82b.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/50004/2199.jpg_wh300.jpg‘},
{‘checksum‘: ‘dc87cfe3f9a3ee2728af253ebb686d2d‘,
‘path‘: ‘full/63334914ac8fc79f8a37a5f3bd7c06abeffac2a8.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00002/3435.jpg_wh300.jpg‘},
{‘checksum‘: ‘b19e55369fa0a5061f48fe997b0085e5‘,
‘path‘: ‘full/4f06b529a4a5fd752339fc120a1bcf89a7125da0.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00038/9869.jpg_wh300.jpg‘},
{‘checksum‘: ‘786e0cfacf113d00302794c5fda7e93f‘,
‘path‘: ‘full/9540903ee92ec44d59916b4a5ebcbcec32e50a67.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00029/2430.jpg_wh300.jpg‘},
{‘checksum‘: ‘c4266a539b046c1b8f66609b3fef36e2‘,
‘path‘: ‘full/ea9bda3236f78ac319b02add631d7a713535c8d0.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00037/9614.jpg_wh300.jpg‘},
{‘checksum‘: ‘0b4d75bb3289a2bda05dac84bfee3591‘,
‘path‘: ‘full/1831779855e3767e547653a823a4c986869bb6df.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/50002/2276.jpg_wh300.jpg‘},
{‘checksum‘: ‘0c7b9e849acf00646ef06ae4ade0a024‘,
‘path‘: ‘full/cac4915246f820035198c014a770c80cb078300b.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00045/2871.jpg_wh300.jpg‘},
{‘checksum‘: ‘4482da90e8b468e947cd2872661c6cac‘,
‘path‘: ‘full/118dc882386112ab593e86743222200bedb8752a.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00015/5234.jpg_wh300.jpg‘},
{‘checksum‘: ‘12b8d957b3a1fd7a29baf41c06b17105‘,
‘path‘: ‘full/ac2e45ed2716678a5045866a65d86e304e97e8ad.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00021/8332.jpg_wh300.jpg‘},
{‘checksum‘: ‘44275a83945dfe4953ecc82c7105b869‘,
‘path‘: ‘full/b0ec1a2775ec55931e133c46e9f1d8680bea39e6.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00043/3285.jpg_wh300.jpg‘},
{‘checksum‘: ‘e960e51ebbc4ac7bd12c974ca8a33759‘,
‘path‘: ‘full/5f2a293333ea3f1fd3c63b7d56a9f82e1d9ff4d8.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/50001/6744.jpg_wh300.jpg‘},
{‘checksum‘: ‘08acf086571823fa739ba1b0aa5c99f3‘,
‘path‘: ‘full/70b24f8e7e1c4b4d7e3fe7cd6056b1ac4904f92e.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/50001/1769.jpg_wh300.jpg‘},
{‘checksum‘: ‘2599ccd44c640948e5331688420ec8af‘,
‘path‘: ‘full/a20b9c4eaf12a56e8b5506cc2a27d28f3e436595.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00031/3314.jpg_wh300.jpg‘},
{‘checksum‘: ‘39bcb67a642f1cc9776be934df292f59‘,
‘path‘: ‘full/8b3d1eee34fb752c5b293252b10f8d9793f05240.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/50006/3243.jpg_wh300.jpg‘},
{‘checksum‘: ‘d2e554d618de6d53ffd76812bf135edf‘,
‘path‘: ‘full/907c628df31bf6d6f2077b5f7fd37f02ea570634.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/50000/4373.jpg_wh300.jpg‘},
{‘checksum‘: ‘6fc5c1783080cee030858b9abb5ff6a5‘,
‘path‘: ‘full/f42a1cca0f7ec657aa66eca9a751a0c4d8defbb1.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00013/4480.jpg_wh300.jpg‘},
{‘checksum‘: ‘906d1b79cec6ac8a0435b2c5c9517b4a‘,
‘path‘: ‘full/35853ef411058171381dc65e7e2c824a86caecbe.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00002/9278.jpg_wh300.jpg‘},
{‘checksum‘: ‘3119eca5ffdf5c0bb2984d7c6dc967c0‘,
‘path‘: ‘full/b294005510b8159f7508c5f084a5e0dbbfb63fbe.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00017/0701.jpg_wh300.jpg‘},
{‘checksum‘: ‘7ce71cece48dcf95b86e0e5afce9985d‘,
‘path‘: ‘full/035017aa993bb72f495a7014403bd558f1883430.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00022/2328.jpg_wh300.jpg‘},
{‘checksum‘: ‘ac1d9a9569353ed92baddcedd9a0d787‘,
‘path‘: ‘full/71038a4d15c0e5613831d49d7a6d5901d40426ac.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00019/6796.jpg_wh300.jpg‘},
{‘checksum‘: ‘ad1732345aeb5534cb77bd5d9cffd847‘,
‘path‘: ‘full/c01104e93ed52a3d62c6a5edb2970281b2d0902b.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00004/4944.jpg_wh300.jpg‘},
{‘checksum‘: ‘c3c216d12719b5c00df3a85baef90aff‘,
‘path‘: ‘full/1470a42ad964c97867459645b14adc73c870f0e1.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/50016/6025.jpg_wh300.jpg‘},
{‘checksum‘: ‘74c37b5a6e417ecfa7151683b178e2b3‘,
‘path‘: ‘full/821cea60c4ee6b388b5245c6cc7e5aa5d07dacb5.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00002/3437.jpg_wh300.jpg‘},
{‘checksum‘: ‘f991181e76a5017769140756097b18f5‘,
‘path‘: ‘full/a8aa882e28f0704dd0c32d783df860f8b5617b45.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00014/2406.jpg_wh300.jpg‘},
{‘checksum‘: ‘0878fe7552a6c1c5cfbd45ae151891c8‘,
‘path‘: ‘full/9c147ed85db3823b1072a761e30e8f2a517e7af0.jpg‘,
‘url‘: ‘http://img95.699pic.com/photo/00007/4890.jpg_wh300.jpg‘}]}
2017-06-09 22:38:20 [scrapy] INFO: Closing spider (finished)
2017-06-09 22:38:20 [scrapy] INFO: Dumping Scrapy stats:
{‘downloader/request_bytes‘: 10145,
‘downloader/request_count‘: 26,
‘downloader/request_method_count/GET‘: 26,
‘downloader/response_bytes‘: 1612150,
‘downloader/response_count‘: 26,
‘downloader/response_status_count/200‘: 26,
‘file_count‘: 25,
‘file_status_count/downloaded‘: 25,
‘finish_reason‘: ‘finished‘,
‘finish_time‘: datetime.datetime(2017, 6, 9, 14, 38, 20, 962000),
‘item_scraped_count‘: 1,
‘log_count/DEBUG‘: 53,
‘log_count/INFO‘: 7,
‘response_received_count‘: 26,
‘scheduler/dequeued‘: 1,
‘scheduler/dequeued/memory‘: 1,
‘scheduler/enqueued‘: 1,
‘scheduler/enqueued/memory‘: 1,
‘start_time‘: datetime.datetime(2017, 6, 9, 14, 38, 19, 382000)}
2017-06-09 22:38:20 [scrapy] INFO: Spider closed (finished)
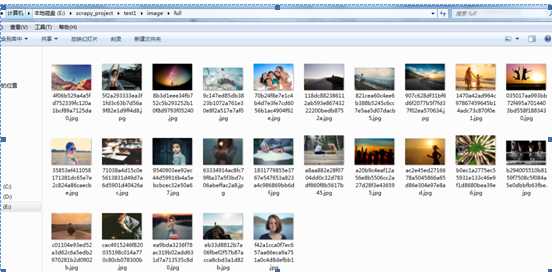
从log日志中可以看到image_urls和images中分别保存了图片URL以及返回的路径。比如下面的这个例子。Jpg图片保存在full文件夹下面
full/1470a42ad964c97867459645b14adc73c870f0e1.jpg
结合之前设置的IMAGES_STORE的值,图片的完整路径应该是在E:\scrapy_project\test1\image\full。在这个路径下可以看到下载完成的图片
根据scrapy的官方文档,get_media_requests和item_completed也可以自己重写,代码如下,和系统自带的代码差不多是一样的
class Test1Pipeline(ImagesPipeline):
def get_media_requests(self,item,info):
for image_url in item[‘image_urls‘]:
yield Request(image_url)
def item_completed(self, results, item, info):
image_path=[x[‘path‘] for ok,x in results if ok]
print image_path
if not image_path:
raise DropItem(‘items contains no images‘)
item[‘image_paths‘]=image_path
return item
标签:ecc 网页 取出 data- tran ted 爬取图片 路径 refresh
原文地址:http://www.cnblogs.com/zhanghongfeng/p/7082510.html