标签:提高 headers rdkafka css stream 关系 增删改查 cookie 慢慢
我始终坚信的一点是,学习的效果80%来自总结,甚至全部都是。总结的好处就是让你能翻出你的过往,指出其中的不足,看到未来的改进方法,好的总结更能让知识产生飞跃,所以在工作之余,部署项目之际,总结一番。
一、背景
公司数据量庞大,万花筒一样的领导随即用上了pipeline_kafka这样的流式数据架构。其实在接手项目之前,作为一个应用开发、我是不太清楚kafka是什么鬼的,还有stream、transform、等等一系列名词,听起来很高大上,但是很懵比=-=。
领导的目标是做一个数据流管理系统,目的是关联postgresql+kafka+流;通过平台的方式管理kafka的关联、流的数据规则、转换数据的操作,简单的来说就是集成一下数据工程师平时的sql操作,用可视化平台的方式提高工作效率。
二、前端结构
前端框架,选用了React.js,浅略的使用一下便感受到了react作为一个视图库的魅力,它将前端变得更优雅。因为React.js只能处理视图层,而具体的controller我只是使用了jQuery作为补充,项目的体量不大,变动较多,使用jquery是最好的选择。
列出使用到的技术:
① React.js
② jQuery
③ react-tools 打包jsx
④ sass对css模块化处理
由于项目足够简单,React也是浅略的使用了一下,并没有用到es6,也没有用到webpack打包,算是一边做项目,一边入了门,构思简单,实用为上,且看代码结构:
以首页为例子:
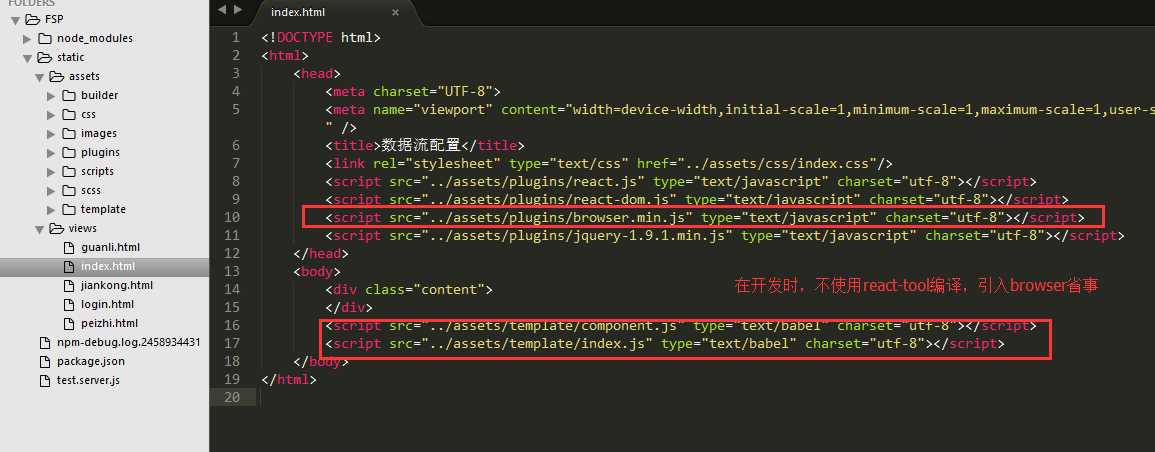
首先一个公共的index.html文件 引入需要的文件资源:
css的处理,使用sass的@import进行模块化加载:
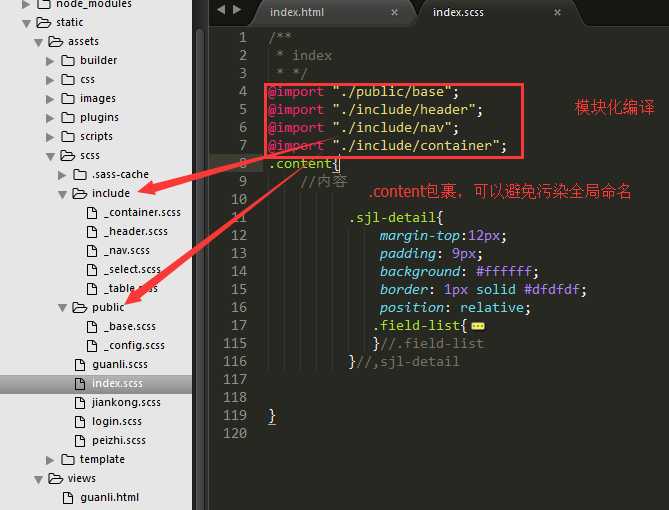
这么做的好处是可以按需加载,并且一个index.scss就可以解决所有的依赖关系,在引入时也可以减少请求数量。
再看react:
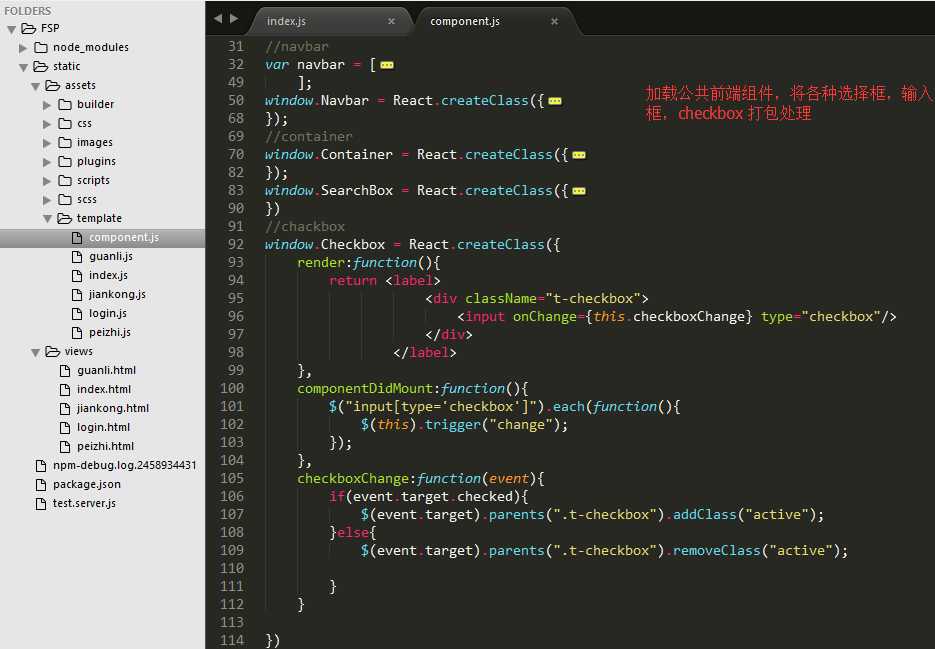
component.js 将所有组件打包,页面公用
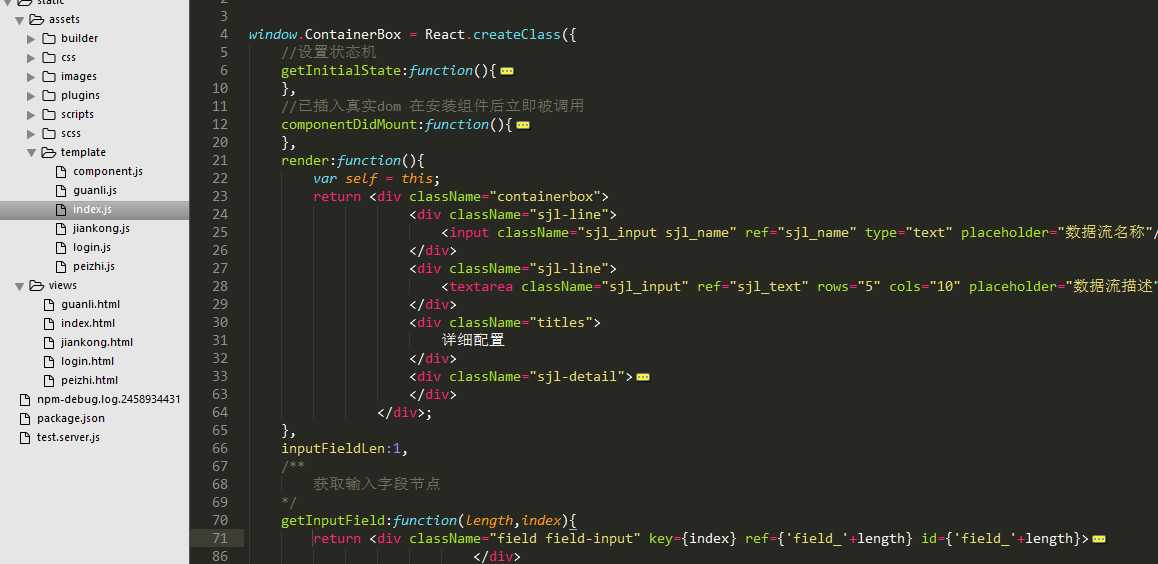
index.js承载了页面主要组件,交互处理。
跑完所有页面之后,部署到node中 开启react-tool,移除browser.js进行应用开发。
个人觉得这种前端结构的亮点在于,前端结构清晰,组织逻辑比较易懂,适合用作从传统开发转入自动化开发的过度结构,也适合开发环境特殊,使用npm苦难的群众,比如我的公司,工作电脑是完全隔绝互联网的,使用webpack打包极为不便。另外一个项目如果不确定将来会落到哪位程序员的手里维护,使用webpack打包有可能造成困扰,毕竟维护代码的人,他可能是个java开发......
参考资料:
三、server端结构
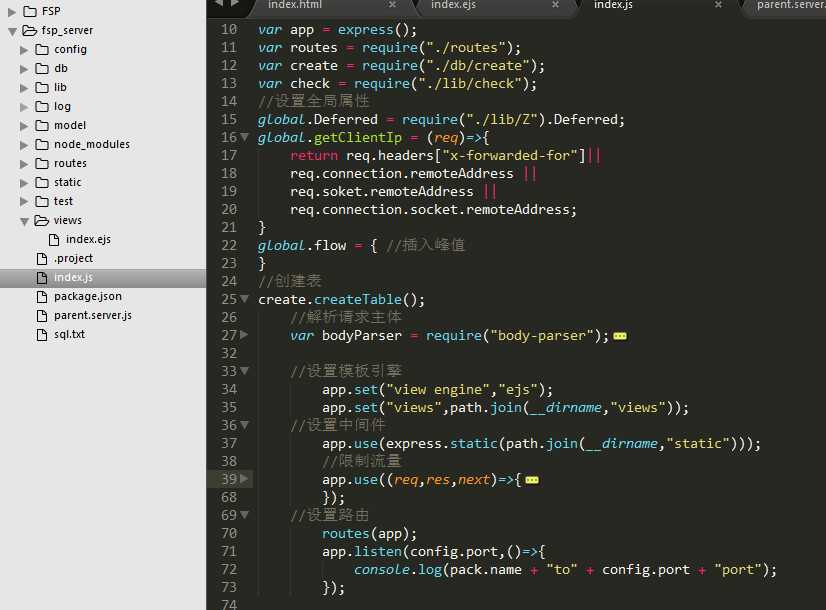
经典的express框架mvc结构,将前端代码拿到node中,入口文件看起来是这样的:
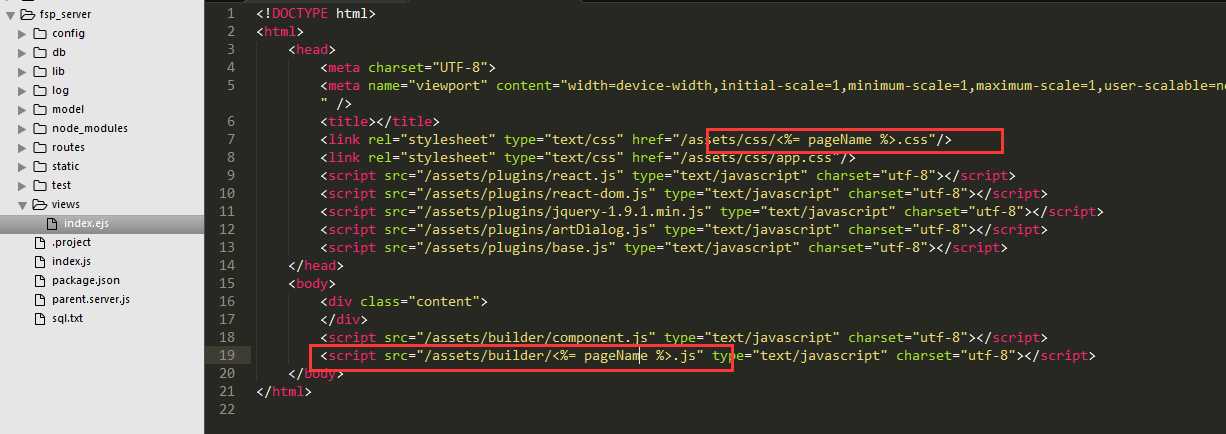
pageName变量由router的render决定,这样做引出的优化点是,页面由react托管,独立的js文件可修改性能更强,也加强了逻辑性。
经典的express入口文件
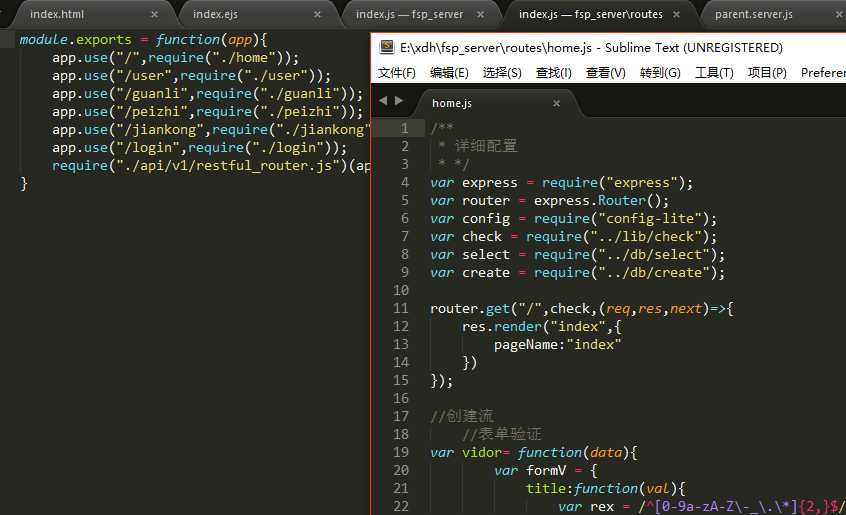
router路由控制:
参考资料
Nodejs进阶:如何玩转子进程(child_process)
项目需要跨域,通过token做登陆验证
项目需要跨域请求,因此如何远程登录成了问题,谷歌很久采用了token机制,生成token这一步并没有使用第三方包,而是耍了下花枪,且看代码实现:
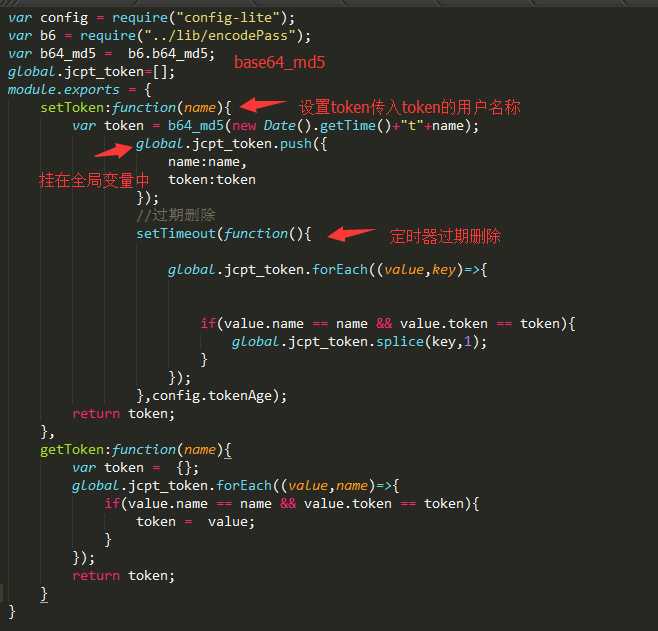
将token挂在global上,setTimeout延时删除,获取时再根据name获取token对比,跨域时设置credentials获取cookie,或者通过headers获取token,安全性能良好,后期我将它挂在了另一个进程中,获取和设置使用另一个进程进行管理。
更多我将另开文章慢慢的说。〓
一、kafka
nodejs连接kafka我使用的node-rdkafka组件,这个组件只能在linux环境下编译使用,node-rdkafka git地址
使用它的原因,是它支持sasl认证,这个组件找了很久才找到,具体的连接代码在工作环境拿不出来,这里也就不演示介绍,github上有详细的说明。
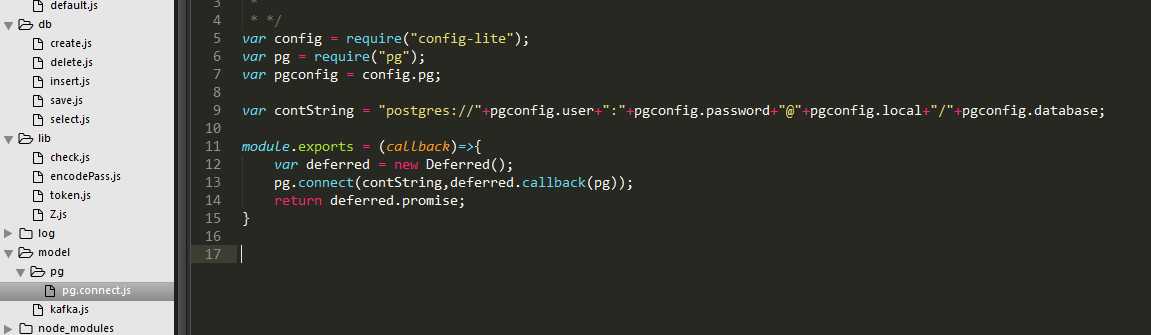
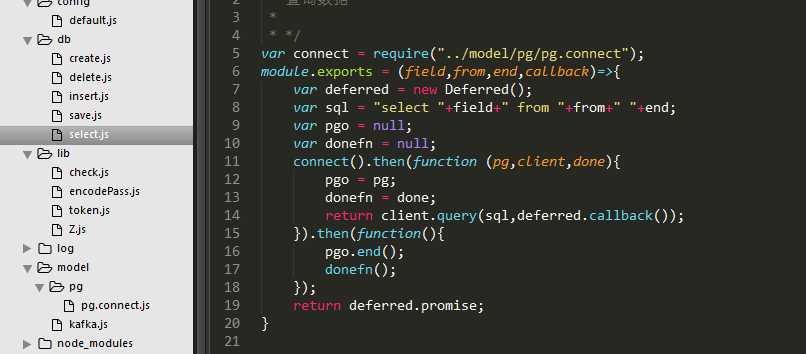
二、postgresql
用pg组件连接postgresql,封装出增删改查方法:
三、其他
更多的细节,因为篇幅太大,放到其他文章中讲述,这里略略的总结一下项目主要结构。
总的来说,项目不大,能玩的花样不多,其中的技术要点,点透也就得心应手了,博主从接到任务到部署,花了十天的时间才开发完成,感觉各个地方还是有很多的不足之处。总结写在博客上和大家探讨。
有什么建议,欢迎留言。
需要了解其中更详细的知识点,可以联系我。
【node】记录项目的开始与完成——pipeline_kafka流式数据库管理项目
标签:提高 headers rdkafka css stream 关系 增删改查 cookie 慢慢
原文地址:http://www.cnblogs.com/ztfjs/p/zj.html