标签:str 简单 src img 适合 字节 表示 com 规则
所谓编码 即char->byte
所谓解码 即byte->char
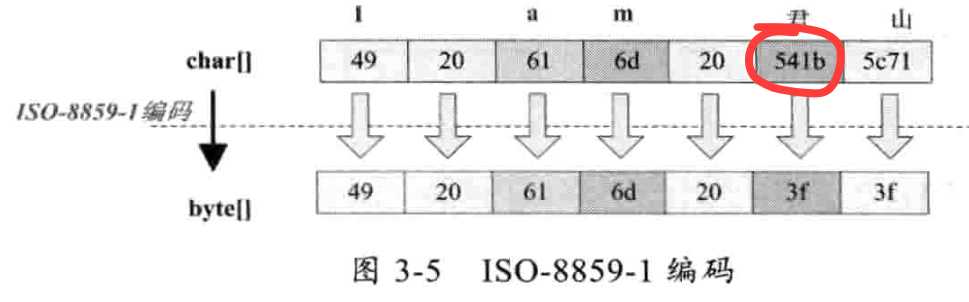
ISO-8859-1 中文字符会被黑洞吸收 全部变为"?"
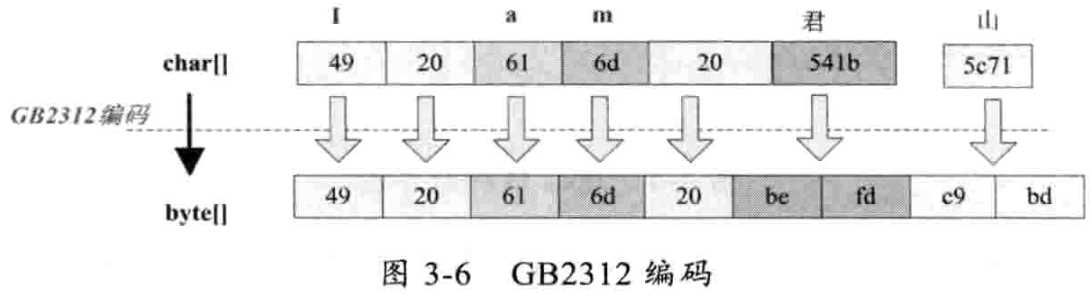
GB2312 汉字可以被编码为双字节 但是该标准仅仅支持6763个汉字 且char到byte需要查表
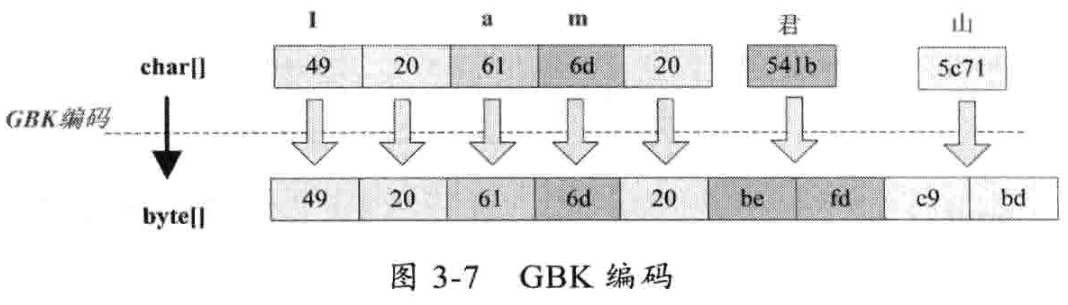
GBK 与GB2312基本相同 只不过包含更多的汉字
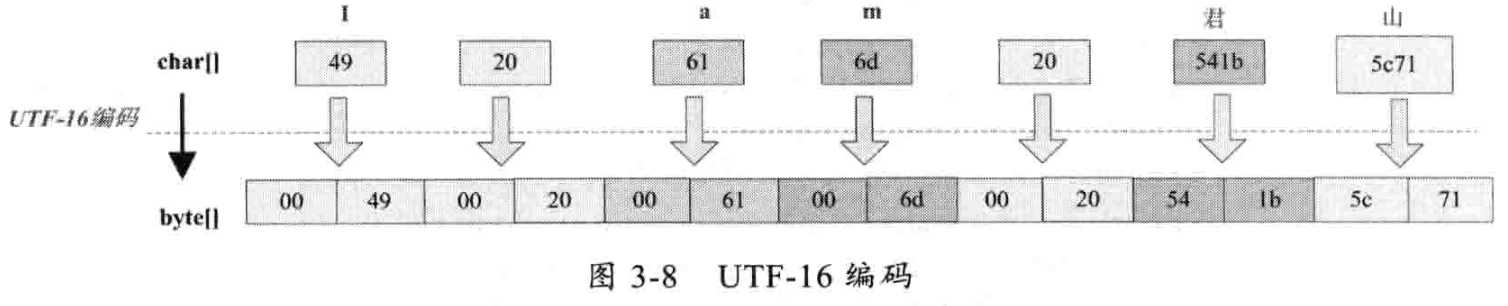
UTF-16 将char强行拆成两个字节 不存在的部分写00 规则简单 编码效率高 缺点浪费了部分存储空间 且一个汉字拆为三个字节
其中一个字符码损坏 后面会受影响 适合在本地磁盘和内存之间使用 不适合网络传输(易损坏字节流 数据经过网络传输时都是以字节为单位的)
UTF-8 对单字节范围内的字符仍然使用1个字节表示,对汉字则采用3个字节表示 更适合在网络传输 且UTF-8在编码效率上和编
码安全性上做了平衡,是理想的中文编码方式
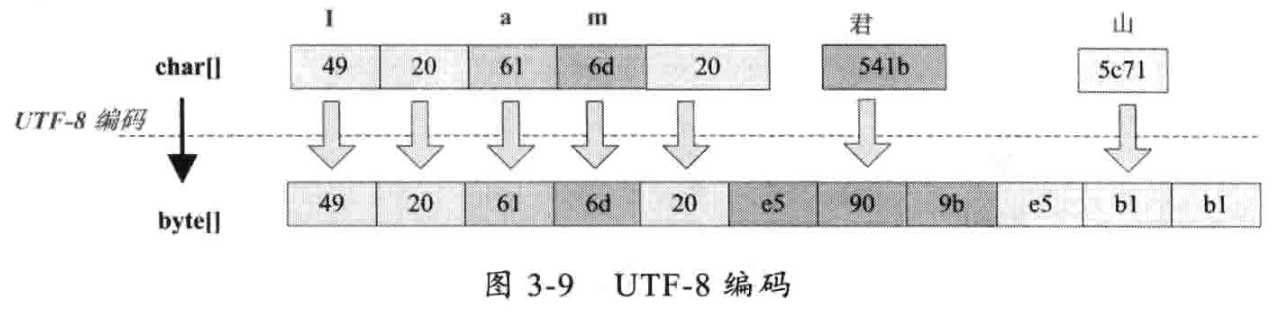
UTF-16 UTF-8都是处理Unicode编码
当采用压缩算法对字符进行压缩时候,不能仅仅看字符数量的减少(这是没意义的),而要重点关注最终的字节数,这还取决于选择的编码方式。
标签:str 简单 src img 适合 字节 表示 com 规则
原文地址:http://www.cnblogs.com/luyu1993/p/7092544.html