标签:服务 har 添加 解决方法 ret 问题 步骤 lis 返回
追求极致才能突破极限
首先看一下系统架构,方便解释:
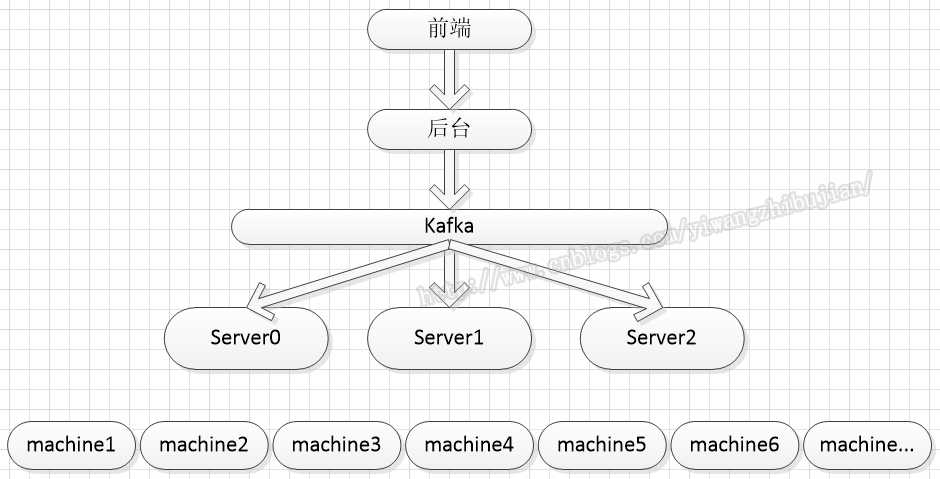
页面给用户展示的功能就是,可以查看任何一台机器的某些属性(以下简称系统信息)。
消息流程是,页面发起请求查看指定机器的系统信息到后台,后台可以查询到有哪些server在提供服务,根据负载均衡算法(简单的轮询)指定由哪个server进行查询,并将消息发送到Kafka,然后所有的server消费Kafka的信息,当发现消费的信息要求自己进行查询时,就连接指定的machine进行查询,并将结果返回回去。
Server是集群架构,可能动态增加或减少。
至于架构为什么这么设计,不是重点,只能说这是符合当时环境的最优架构。
遇到的问题就是慢,特别慢,经过初步核实,最耗时的事是server连接machine的时候,基本都要5s左右,这是不能接受的。
因为耗时最大的是server连接machine的时候,所以决定在server端缓存machine的连接,经过测试如果通过使用的连接缓存进行查询,那么耗时将控制在1秒以内,满足了用户的要求,不过还有一个问题因此产生,那就是根据现有负载均衡算法,假如server1已经缓存了到machine1的连接,但是再次查询时,请求就会发送到下一个server,如server2,这就导致了两个问题,一是,重新建立了连接耗时较长,二是,两个server同时缓存着到machine1的连接,造成了连接浪费。
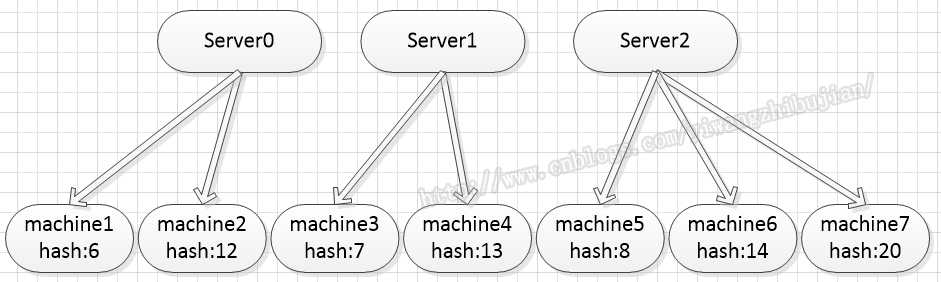
一开始想到最简单的就是将查询的machine进行hash计算,并除sever的数量取余,这样保证了查询同一个machine时会要求同一个server进行操作,满足了初步的需求。但是因为server端是集群,机器有可能动态的增加或减少,假如根据hash计算,指定的 machine会被指定的server连接,如下图:
然后又增加了一个server,那么根据当前的hash算法,server和machine的连接就会变成如下:
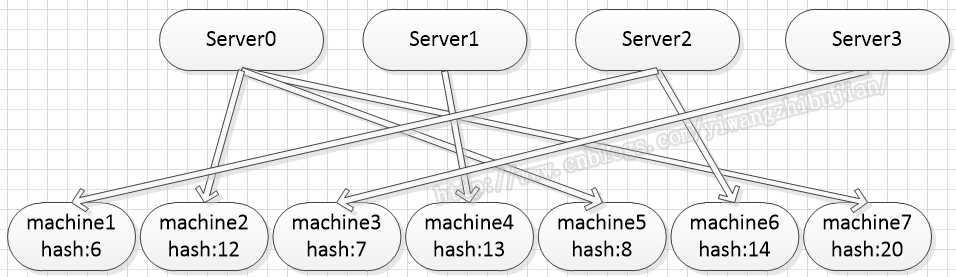
可以发现,四个machine和server的连接关系发生变化了,这将导致4次连接的初始化,以及四个连接的浪费,虽然server集群变动的几率很小,但是每变动一次将有一半的连接作废掉,这还是不能接受的,当时想的最理想的结果是:
简单来说,就是变动不可避免,但是让变动最小化。根据这种思想,就想到了一致性hash,觉得这个应该可以满足要求。
一致性Hash的定义或者介绍在第三节,现在写出一致性Hash的Java的解决方法。只写出示例实现代码,首先最重要的就是Hash算法的选择,根据现有情况以及已有Hash算法的表现,选择了FNV Hash算法,以下是其实现:
public static int FnvHash(String key) { final int p = 16777619; long hash = (int) 2166136261L; for (int i = 0,n = key.length(); i < n; i++){ hash = (hash ^ key.charAt(i)) * p; } hash += hash << 13; hash ^= hash >> 7; hash += hash << 3; hash ^= hash >> 17; hash += hash << 5; return ((int) hash & 0x7FFFFFFF); }
然后是对能提供服务的server进行预处理:
public static ConcurrentSkipListMap<Integer, String> init(){ //创建排序Map方便后面的计算 ConcurrentSkipListMap<Integer,String> servers=new ConcurrentSkipListMap<>(); //获得可以提供服务的server List<String> serverUrls=Arrays.asList("192.168.2.1:8080","192.168.2.2:8080","192.168.2.3:8080"); //将server依次添加到Map中 for(String serverUrl:serverUrls){ servers.put(FnvHash(serverUrl), serverUrl); //以下三个是当前server的三个虚拟节点,Hash不同 servers.put(FnvHash(serverUrl+"#1"), serverUrl); servers.put(FnvHash(serverUrl+"#2"), serverUrl); servers.put(FnvHash(serverUrl+"#3"), serverUrl); } return servers; }
这段代码将能提供的server放入排序Map,键为其Hash值,值为server的主机和IP,接下来就要对每一个请求的要连接的machin计算需要哪一个server进行连接:
/** * @param machine 要连接的机器 * @param servers 可提供服务的server * @return */ private static String getServer(int machine, ConcurrentSkipListMap<Integer, String> servers) { int left=Integer.MAX_VALUE; int right=Integer.MAX_VALUE; int leftDis=0; int rightDis=0; for(Entry<Integer, String> server:servers.entrySet()){ int key=server.getKey(); if(key<machine){ left=key; }else{ right=key; } if(right!=Integer.MAX_VALUE){ break; } } if(left==Integer.MAX_VALUE){ left=servers.lastKey(); leftDis=Integer.MAX_VALUE-left+machine; }else{ leftDis=machine-left; } if(right==Integer.MAX_VALUE){ right=servers.firstKey(); rightDis=Integer.MAX_VALUE-machine+right; }else{ rightDis=right-machine; } return servers.get(rightDis<=leftDis?right:left); }
这个方法就是计算,具体逻辑可以在看完下一节有更深的了解。
经过上面的三个方法就解决了上面提出的要求,经过测试也完美,或许算法还看不懂,也或许一致Hash算法还不知道是什么,虚拟节点是什么,但是现在应该了解需求是怎么产生的,已经通过什么满足了要求,现在唯一要做的就是了解一致性Hash了,下面进行介绍。
一致性Hash的简介,摘自百度百科。
一致性哈希算法在1997年由麻省理工学院提出,设计目标是为了解决因特网中的热点(Hot spot)问题。一致性哈希提出了在动态变化的Cache环境中,哈希算法应该满足的4个适应条件:
均衡性(Balance):
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
单调性(Monotonicity):
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。(这段翻译信息有负面价值的,当缓冲区大小变化时一致性哈希(Consistent hashing)尽量保护已分配的内容不会被重新映射到新缓冲区。)
分散性(Spread):
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load):
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
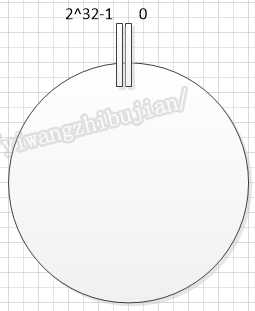
一般的一致性Hash的设计实现都是按照如下方式:
首先所有的Hash值应该构成一个环,就像钟表的时刻一样,也就是说有明确的Hash最大值,环内Hash的数量一般为2的32次方:
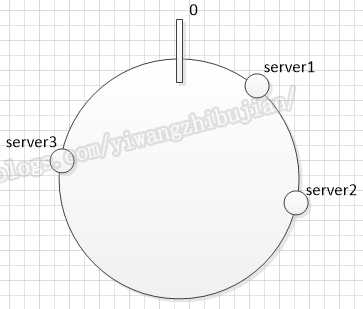
将server通过Hash计算映射到环上,注意选取能区别开server的唯一属性,比如ip加端口:
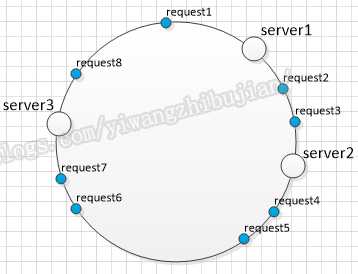
然后所有的把所有的请求使用唯一的属性计算Hash值,然后请求到最近的server上面:
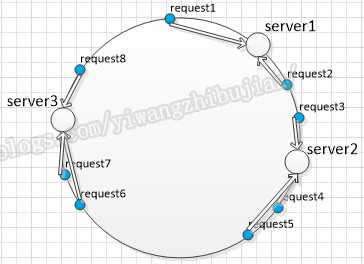
假如有新机器加入时:
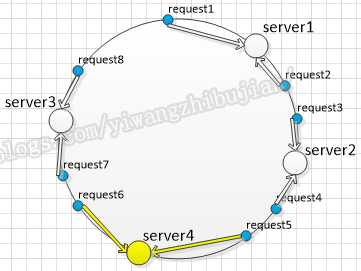
新机器相邻的请求会被重新定向到新的server,如果有机器挂掉的话,挂掉机器的请求也会重新分配给就近的server:
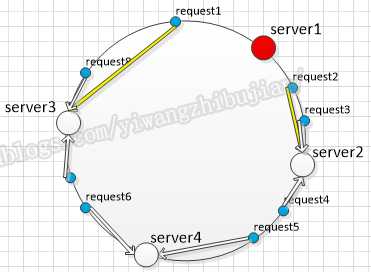
通过上面的图例讲解,应该可以看出环形设计的好处,那就是不管新增还是减少机器,变动的都是变动机器附近的请求,已有请求的映射不会变动到已有的节点上。
通过一致性Hash的特性来看,一致性Hash极力保证变动的最小化,比较适用于有状态连接,如果连接是无状态的,那么完全没必要使用这种算法,轮询或者随机都是可以的。效率要比一致性Hash高,省去了每一次请求的计算过程。
本质上没有特殊的要求,选取的原则可以考虑以下几点:
所以上面的例子,环Hash数量选择了2^32,恰好fnv Hash算法的最大值也是它,FNV Hash算法参照此。
看过上面代码的应该知道,对server进行Hash的时候,会同时创建server的几个虚拟节点,它们同样代表着它们的server,有如下作用:
至于虚拟节点的数量,这个没有硬性要求,节点的数量越多,负载均衡越好,但是计算量也越大,如果考虑到server集群的易变性,每一次请求都需要重新计算server及其虚拟节点的Hash值,那么节点的数量不要太大,不然也是一个性能的瓶颈。
Hash算法有很多种,上面fnv hash的可以参考一下,至于其他的,考虑以下几点就可以:
考虑以上几点就可以了,后续会针对Hash算法,写一篇博客。
不用一致Hash可不可以,能不能满足相同的需求,答案是可以的,那就是主动维护一个路由表。基本要做以下操作:
优缺点简单说一下:
优点:
缺点:
以上就是我对一致Hash的理解,以及我在项目中的应用,希望可以帮助到有需要的人。
标签:服务 har 添加 解决方法 ret 问题 步骤 lis 返回
原文地址:http://www.cnblogs.com/yiwangzhibujian/p/7090471.html