标签:bsp python2 node 字母 and inux 程序 扩展 空间换时间
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。通俗的说,按照何种规则将字符存储在计算机中,如‘a‘用什么表示,称为"编码";反之,将存储在计算机中的二进制数解析显示出来,称为"解码",如同密码学中的加密和解密。在解码过程中,如果使用了错误的解码规则,则导致‘a‘解析成‘b‘或者乱码。
字符(Character):是一个信息单位,在计算机里面,一个中文汉字是一个字符,一个英文字母是一个字符,一个阿拉伯数字是一个字符,一个标点符号也是一个字符。
字符集(Charset):是一个系统支持的所有抽象字符的集合。通常以二维表的形式存在,二维表的内容和大小是由使用者的语言而定,可以是英语,是汉语,或者阿拉伯语。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。在这里我们把字符集中的字符编码为特定的二进制数,以便在计算机中存储。编码方式一般就是对二维表的横纵坐标进行变换的算法。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。即:字符--------(翻译过程)------->二进制数
字符集和字符编码一般都是成对出现的,如ASCII、GBK、Unicode、UTF-8等,都是即表示了字符集又表示了对应的字符编码,以后统称为编码。
第一阶段:起源,ASCII
计算机是美国人发明的,人家用的是美式英语,字符比较少,所以一开始就设计了一个不大的二维表,128个字符,取名叫ASCII(American Standard Code for Information Interchange)。但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。即其最多只能用 8 位来表示(一个字节)。
第二阶段:GBK
当计算机传到了亚洲,尤其是东亚,国际标准被秒杀了,路边小孩随便说句话,256个码位就不够用了。于是,中国定制了GBK。用2个字节代表一个字符(汉字)。其他国家也纷纷定制了自己的编码,例如:
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里。
第三阶段:unicode
当互联网席卷了全球,地域限制被打破了,不同国家和地区的计算机在交换数据的过程中,就会出现乱码的问题,跟语言上的地理隔离差不多。为了解决这个问题,一个伟大的创想产生了——Unicode(万国码)。Unicode编码系统为表达任意语言的任意字符而设计。
规定所有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,注:此处说的的是至少2个字节(16位),可能更多。
第四阶段:UTF-8
unicode的编码方式虽然包容万国,但是对于英文等字符就会浪费太多存储空间。于是出现了UTF-8,是对Unicode编码的压缩和优化,遵循能用最少的表示就用最少的表示,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
补充:
unicode:包容万国,优点是字符->数字的转换速度快,缺点是占用空间大 utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
内存中使用的编码是unicode,用空间换时间,为了快
因为程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快。
硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
如下图:
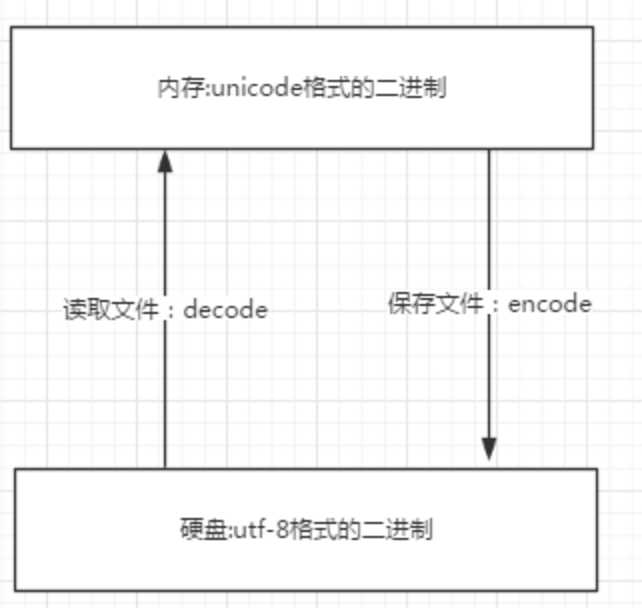
1)文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就打开了启动了一个进程,是在内存中的,所以在编辑器编写的内容也都是存放与内存中的,断电后数据丢失。因而需要保存到硬盘上,点击保存按钮,就从内存中把数据刷到了硬盘上。在这一点上,我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
无论是何种编辑器,要防止文件出现乱码,核心法则就是,文件以什么编码保存的,就以什么编码方式打开。
2)python解释器执行py文件的原理 (python test.py)
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中
第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码
补充:
所以,在写代码时,为了不出现乱码,推荐使用UTF-8,会加入 # -*- coding: utf-8 -*-
即
#!/usr/bin/env python # -*- coding: utf-8 -*- print "你好,世界"
python解释器会读取test.py的第二行内容,# -*- coding: utf-8 -*-,来决定以什么编码格式来读入内存,这一行就是来设定python解释器这个软件的编码使用的编码格式这个编码。
如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的python2中默认使用ascii,python3中默认使用utf-8
总结:
1)python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
2)与文本编辑器不一样的地方在于,python解释器不仅可以读文件内容,还可以执行文件内容
1) python2中默认使用ascii,python3中默认使用utf-8
2) Python2中,str就是编码后的结果bytes,str=bytes,所以s只能decode。
3) python3中的字符串与python2中的u‘字符串‘,都是unicode,只能encode,所以无论如何打印都不会乱码,因为可以理解为从内存打印到内存,即内存->内存,unicode->unicode
4) python3中,str是unicode,当程序执行时,无需加u,str也会被以unicode形式保存新的内存空间中,str可以直接encode成任意编码格式,s.encode(‘utf-8‘),s.encode(‘gbk‘)
#unicode(str)-----encode---->utf-8(bytes) #utf-8(bytes)-----decode---->unicode
5)在windows终端编码为gbk,linux是UTF-8.
标签:bsp python2 node 字母 and inux 程序 扩展 空间换时间
原文地址:http://www.cnblogs.com/zhangyingai/p/7097992.html