标签:机制 file 多个 基本类型 数组使用 hba ready 本地 imu
本文参考连接:http://blog.csdn.net/class281/article/details/24849275
http://zhhphappy.iteye.com/blog/1562427
一、IO包简要类图
Java I/O流部分分为两个模块,即Java1.0中就有的面向字节的流(Stream),以及Java1.1中大幅改动添加的面向字符的流(Reader & Writer)。添加面向字符的流主要是为了支持国际化,旧的I/O流仅支持8位的字节流,并不能很好的处理16位的Unicode字符(Java的基础类型char也是16位的Unicode)。下面就针对这两类流做一个简要的分析。
二、面向字节的流
InputStream(OutputStream)是所有面向字节流的基类。它的子类分为两大块,一是诸如ByteArrayInputStream(ByteArrayOutputStream),FileInputStream(FileOutputStream)等等面向各种不同的输入(输出)源的子类,另一块为了方便流操作的而进一步封装的装饰器系列FilterInputStream(FilterOutputStream)类及其子类。
BufferedInputStream 是一个带有内存缓冲的 InputStream.
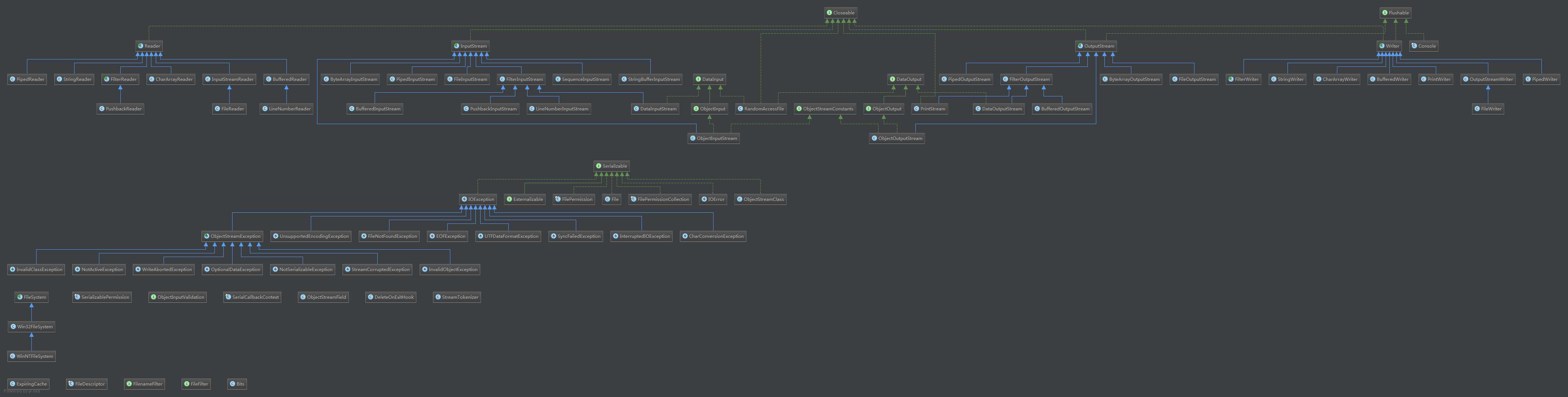
1.首先来看类结构 :
BufferedInputStream是继承自FilterInputStream。
FilterInputStream继承自InputStream属于输入流中的链接流,同时引用了InputStream,将InputStream封装成一个内部变量,同时构造方法上需要传入一个InputStream。这是一个典型的装饰器模式,他的任何子类都可以对一个继承自InputStream的原始流或其他链接流进行装饰,如我们常用的使用BufferedInputStream对FileInputStream进行装饰,使普通的文件输入流具备了内存缓存的功能,通过内存缓冲减少磁盘io次数。
1 protected volatile InputStream in; 2 protected FilterInputStream(InputStream in) { 3 this.in = in; 4 }
注意:成员变量in使用了volatile关键字修饰,保障了该成员变量多线程情况下的可见性。
2.内存缓冲的实现
概要的了解完BufferedInputStream的继承关系,接下来详细理解BufferedInputStream是如何实现内存缓冲。既是内存缓冲,就涉及到内存的分配,管理以及如何实现缓冲。
通过构造方法可以看到:初始化了一个byte数组作为内存缓冲区,大小可以由构造方法中的参数指定,也可以是默认的大小。
1 protected volatile byte buf[]; 2 private static int defaultBufferSize = 8192; 3 public BufferedInputStream(InputStream in, int size) { 4 super(in); 5 if (size <= 0) { 6 throw new IllegalArgumentException("Buffer size <= 0"); 7 } 8 buf = new byte[size]; 9 } 10 public BufferedInputStream(InputStream in) { 11 this(in, defaultBufferSize); 12 }
看完构造函数,大概可以了解其实现原理:通过初始化分配一个byte数组,一次性从输入字节流中读取多个字节的数据放入byte数组,程序读取部分字节的时候直接从byte数组中获取,直到内存中的数据用完再重新从流中读取新的字节。那么从api文档中我们可以了解到BufferedStream大概具备如下的功能:

从api可以了解到BufferedInputStream除了使用一个byte数组做缓冲外还具备打标记,重置当前位置到标记的位置重新读取数据,忽略掉n个数据。这些功能都涉及到缓冲内存的管理,首先看下相关的几个成员变量:
1 protected int count; 2 protected int pos; 3 protected int markpos = -1; 4 protected int marklimit;
count表示当前缓冲区内总共有多少有效数据;pos表示当前读取到的位置(即byte数组的当前下标,下次读取从该位置读取);markpos:打上标记的位置;marklimit:最多能mark的字节长度,也就是从mark位置到当前pos的最大长度。
从最简单的read()读取一个字节的方法开始看:
1 public synchronized int read() throws IOException { 2 if (pos >= count) { 3 fill(); 4 if (pos >= count) 5 return -1; 6 } 7 return getBufIfOpen()[pos++] & 0xff; 8 }
1 /** 2 * Fills the buffer with more data, taking into account 3 * shuffling and other tricks for dealing with marks. 4 * Assumes that it is being called by a synchronized method. 5 * This method also assumes that all data has already been read in, 6 * hence pos > count. 7 */ 8 private void fill() throws IOException { 9 byte[] buffer = getBufIfOpen(); 10 if (markpos < 0) 11 pos = 0; /* no mark: throw away the buffer */ 12 else if (pos >= buffer.length) /* no room left in buffer */ 13 if (markpos > 0) { /* can throw away early part of the buffer */ 14 int sz = pos - markpos; 15 System.arraycopy(buffer, markpos, buffer, 0, sz); 16 pos = sz; 17 markpos = 0; 18 } else if (buffer.length >= marklimit) { 19 markpos = -1; /* buffer got too big, invalidate mark */ 20 pos = 0; /* drop buffer contents */ 21 } else if (buffer.length >= MAX_BUFFER_SIZE) { 22 throw new OutOfMemoryError("Required array size too large"); 23 } else { /* grow buffer */ 24 int nsz = (pos <= MAX_BUFFER_SIZE - pos) ? 25 pos * 2 : MAX_BUFFER_SIZE; 26 if (nsz > marklimit) 27 nsz = marklimit; 28 byte nbuf[] = new byte[nsz]; 29 System.arraycopy(buffer, 0, nbuf, 0, pos); 30 if (!bufUpdater.compareAndSet(this, buffer, nbuf)) { 31 // Can‘t replace buf if there was an async close. 32 // Note: This would need to be changed if fill() 33 // is ever made accessible to multiple threads. 34 // But for now, the only way CAS can fail is via close. 35 // assert buf == null; 36 throw new IOException("Stream closed"); 37 } 38 buffer = nbuf; 39 } 40 count = pos; 41 int n = getInIfOpen().read(buffer, pos, buffer.length - pos); 42 if (n > 0) 43 count = n + pos; 44 }
/** * See the general contract of the <code>mark</code> * method of <code>InputStream</code>. * * @param readlimit the maximum limit of bytes that can be read before * the mark position becomes invalid. * @see java.io.BufferedInputStream#reset() */ public synchronized void mark(int readlimit) { marklimit = readlimit; markpos = pos; } /** * See the general contract of the <code>reset</code> * method of <code>InputStream</code>. * <p> * If <code>markpos</code> is <code>-1</code> * (no mark has been set or the mark has been * invalidated), an <code>IOException</code> * is thrown. Otherwise, <code>pos</code> is * set equal to <code>markpos</code>. * * @exception IOException if this stream has not been marked or, * if the mark has been invalidated, or the stream * has been closed by invoking its {@link #close()} * method, or an I/O error occurs. * @see java.io.BufferedInputStream#mark(int) */ public synchronized void reset() throws IOException { getBufIfOpen(); // Cause exception if closed if (markpos < 0) throw new IOException("Resetting to invalid mark"); pos = markpos; }
当pos>=count的时候也就是表示当前的byte中的数据为空或已经被读完,他调用了一个fill()方法,从字面理解就是填充的意思,实际上是从真正的输入流中读取一些新数据放入缓冲内存中,之后直到缓冲内存中的数据读完前都不会再从真正的流中读取数据。
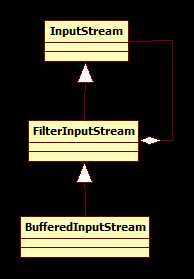
看源码中的fill()方法有很大一段是关于markpos的处理,其处理过程大致如下图:
a.没有markpos的情况很简单:

b.有mark的情况比较复杂:
3.read()方法返回值
以上即为内存缓冲管理的完全过程,再回过头看read()方法,当缓冲byte数组中有数据可以读时,直接从数组中读取一个字节,但最后的read方法返回的却是int,而且还和0xff做了与运算。
1 return getBufIfOpen()[pos++] & 0xff;
为什么不直接返回一个byte,而是一个与运算后的int。首先宏观的看InputStream和Reader两个输入流的抽象类都定义了read接口而且都返回int,一个是字节流,一个是字符流。我们知道字节用byte表示,字符用char表示。首先看java中基本类型的取值范围:
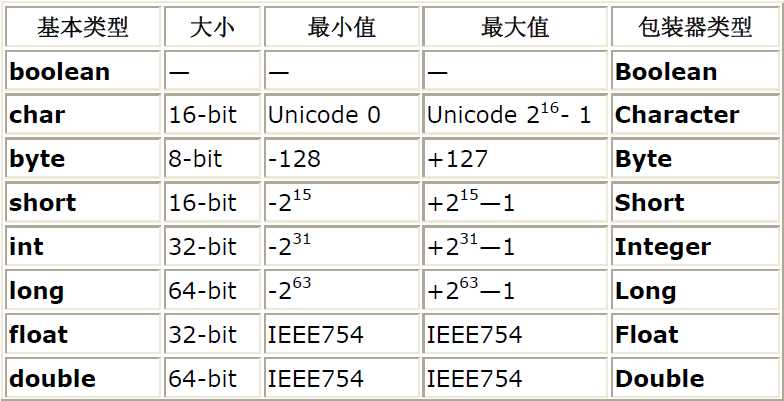
从取值范围来看int包含了char和byte,这为使用int作为返回值类型提供了可能。
在应用中我们一般用read()接口的返回值是-1则表示已经读到文件尾(EOF)。
char的取值范围本身不包含负数,所有用int的-1表示文件读完没问题,但byte的取值范围-128 ~ 127,包含了-1,读取的有效数据范围就是-128~127,没办法用这个取值范围中的任何一个数字表示异常或者数据已经读完,所以接口如果直接使用byte作为返回值不可行,直接将byte强制类型转换成int也不行,因为如果读到一个byte的-1,转为int了也是-1,会被理解为文件已经读完。所以这里做了一个特殊处理return getBufIfOpen()[pos++] & 0xff。
0xff是int类型,二进制为0000 0000 0000 0000 0000 0000 1111 1111。
上述的与运算实际上读取的byte先被强制转换成了int,例如byte的-1(最高位表示符号位,以补码的形式表示负数为:1111 1111)
转换为int之后的二进制1111 1111 1111 1111 1111 1111 1111 1111
& 0xff之后高位去0
最后返回的结果是0000 0000 0000 0000 0000 0000 1111 1111, 为int值为256
其-128~-1被转为int中128~256的正数表示。
这样解决了可以用-1表示文件已经读完。但关键是数据的值发生了变化,真正要用读取的数据时是否还能拿到原始的byte。还拿上面那个例子来看,当读取返回一个256时,将其强制类型转换为byte,(byte)256得到byte的-1,因为byte只有8位,当int的高位被丢弃后就只剩下1111 1111,在byte中高位的1表示符号位为负数,最终的结果即是byte的-1;同样byte的-128(1000 0000)被转为int的128(0000 0000 0000 0000 0000 0000 1000 0000),强制类型转换后还原byte的1000 0000。
4.线程安全
返回值中还有一个细节是getBufIfOpen()[pos++],直接将pos++来获取下一个未读取的数据,这里涉及到的两个元素:一个内存数组,一个当前读取的数据下标都是全局变量,pos++也不是线程安全。那么BufferedInputStream如何保证对内存缓冲数组的操作线程安全?源码中有操作的public方法除了close方法之外,其他方法上都加上了synchronized关键字,以保障上面描述的整个内存缓存数组的操作是线程安全的。但为什么close方法没有synchronized,我们看这个方法做了些什么事情:
byte[] buffer; while ( (buffer = buf) != null) { if (bufUpdater.compareAndSet(this, buffer, null)) { InputStream input = in; in = null; if (input != null) input.close(); return; } // Else retry in case a new buf was CASed in fill() }
简单来看做了两个操作:把内存数组置为null,将引用的inputStream置为null,同时将引用的inputStream.close();
这两个操作的核心都是关闭原始流,释放资源,如果加了synchronized关键字,会导致当前线程正在执行read方法,而且系统消耗很大时,想释放资源无法释放。此时read方法还没执行完,我们知道synchronized的锁是加在整个对象上的,所以close方法就必须等到read结束后才能执行,这样很明显不能满足close的需求,甚至会导致大量的io资源被阻塞不能关闭。
但该方法用一个while循环,而且只有当bufUpdater.compareAndSet(this, buffer, null)成功时,才执行上述的资源释放。
先看bufUpdater这个全局变量
protected volatile byte buf[]; private static final AtomicReferenceFieldUpdater<BufferedInputStream, byte[]> bufUpdater = AtomicReferenceFieldUpdater.newUpdater (BufferedInputStream.class, byte[].class, "buf");
AtomicReferenceFieldUpdater是一个抽象类,但该类的内部已经给出了包访问控制级别的一个实现AtomicReferenceFieldUpdaterImpl,原理是利用反射将一个 被声明成volatile 的属性通过JNI调用,使用cpu指令级的命令将一个变量进行更新,保障该操作是原子的。也就是通过上面定义的bufUpdater将buf这个byte数组的跟新变为原子操作,其作用是保障其原子更新。
BufferedInputStream源代码中总共有两个地方用到了这个bufUpdater,一个是我们上面看到的close方法中,另外一个是再前面说道的fill()方法中。既然BufferedInputStream的所有操作上都用了synchronized来做同步,那为什么这里还需要用这个原子更新器呢?带着问题上面提到过fill()方法中的最后一个步骤:当有mark,而且markLimit的长度又大于初始数组的长度时,需要对内存数组扩容,即创建一个尺寸更大的数组,将原来数组中的数据拷贝到新数组中,再将指向原数组的应用指向新的数组。bufUpdater正是用在了将原数组引用指向新数组的操作上,同样close的方法使用的bufUpdater也是用在对数组引用的改变上,这样看来就比较清晰了,主要是为了防止一个线程在执行close方法时,将buffer赋值为null这个时候另外一个线程正在执行fill()方法的最后一个步骤又将buffer赋值给了一个新的数组,从而导致资源没有释放掉。
下面看一下 bufferedOutputStream的源码,
相比之下缓冲输出流就简单很多,基本上write方法可以说明一切了:
在缓冲区(也是字节数组)写满之前调用write方法只是将数据复制到内部缓冲区;
在缓冲区写满之后,现将旧的数据写入到底层输出流,然后将新的数据暂存到缓冲区(新的数据并未同时写入)
于是flush方法也找到了存在的意义:将现有数据全部写入。
1 package java.io; 2 3 public class BufferedOutputStream extends FilterOutputStream { 4 // 保存“缓冲输出流”数据的字节数组 5 protected byte buf[]; 6 7 // 缓冲中数据的大小 8 protected int count; 9 10 // 构造函数:新建字节数组大小为8192的“缓冲输出流” 11 public BufferedOutputStream(OutputStream out) { 12 this(out, 8192); 13 } 14 15 // 构造函数:新建字节数组大小为size的“缓冲输出流” 16 public BufferedOutputStream(OutputStream out, int size) { 17 super(out); 18 if (size <= 0) { 19 throw new IllegalArgumentException("Buffer size <= 0"); 20 } 21 buf = new byte[size]; 22 } 23 24 // 将缓冲数据都写入到输出流中 25 private void flushBuffer() throws IOException { 26 if (count > 0) { 27 out.write(buf, 0, count); 28 count = 0; 29 } 30 } 31 32 // 将“数据b(转换成字节类型)”写入到输出流中 33 public synchronized void write(int b) throws IOException { 34 // 若缓冲已满,则先将缓冲数据写入到输出流中。 35 if (count >= buf.length) { 36 flushBuffer(); 37 } 38 // 将“数据b”写入到缓冲中 39 buf[count++] = (byte)b; 40 } 41 42 public synchronized void write(byte b[], int off, int len) throws IOException { 43 // 若“写入长度”大于“缓冲区大小”,则先将缓冲中的数据写入到输出流,然后直接将数组b写入到输出流中 44 if (len >= buf.length) { 45 flushBuffer(); 46 out.write(b, off, len); 47 return; 48 } 49 // 若“剩余的缓冲空间 不足以 存储即将写入的数据”,则先将缓冲中的数据写入到输出流中 50 if (len > buf.length - count) { 51 flushBuffer(); 52 } 53 System.arraycopy(b, off, buf, count, len); 54 count += len; 55 } 56 57 // 将“缓冲数据”写入到输出流中 58 public synchronized void flush() throws IOException { 59 flushBuffer(); 60 out.flush(); 61 } 62 }
以文件为输入输出目标的类,其实也可以想象得到,读写本地文件的类追溯上去肯定是本地方法。所以当然它的一系列read(write)方法都是native的。这个以后如果以机会的话再研究。
目前能看到的辅助功能有:
读写文件的这一溜方法大都在sun.nio.ch和sun.misc包里,有兴趣的可以去看openjdk提供的源码,不过Java里面也是调用native方法,而且考虑到跨平台特性估计设计上也会更加复杂,所以推荐先去了解C的文件读写。
这两个类在很多地方被翻译成内存输入(输出)流,当时俺就被这高大上的名字深深的折服了。
其实它们的功能、实现都非常简单,先把所有的数据全存到它内部的字节数组里,然后用这个数组来继续读写,这个时候底层流你就可以不用管了,爱关就关没有影响。
经常会有人把这两个类混在一起,于是特地在此比划一番。说到它们的区别,但实际上从类的组织结构上可以看出来,这两个类其实没有什么联系:一个是以内存中的字节数组为输入目标的类,一个是为了更好的操作字节输入流而提供的带有缓冲区的装饰器类。它们的使用目的本就不一样,只不过由于名字似曾相识,打扮得(实现方式)也差不多,所以经常被误认为两兄弟。这两兄弟的差距还是蛮大的:
ByteArrayInputStream需要在内部的保存流的所有数据,所以需要一个足够大的字节数组,但数组的容量是受JVM中堆空间大小限制的,更极端的情况,即使你为JVM分配了一个很大的空间,由于Java数组使用的是int型索引,所以你也猜到了,它还是会被限制在INT_MAX范围以内。在底层流数据全部保存到ByteArrayInputStream后,你就可以不用再管流,转而去从ByteArrayInputStream读取数据了。
而BufferedInputStream只会用一个有限大小的缓存数组保存底层流的一小部分数据,你在读取数据的时候其实还是在和底层流打交道,只不过BufferedInputStream为了满足你变幻莫测的读取要求提供了缓冲区,让你的读取操作更加犀利流畅。
所以总结起来,它们除了同样从InputStream派生而来,同样使用了字节数组(这是个经常发生的巧合)以外,没有任何联系。
这两个类允许我们以基本类型的形式操作字节流,可以理解为一个基本数据类型到字节之间的映射转换。
例如我想要从输入流中读取一个int类型数据(4字节),那么就需要先读4个字节,然后按照每个字节在int中的位置作相应移位处理,就得到这4个字节所代表的int型数据了。
这个类的功能其实比较隐晦(至少我一开始是理解错了)。按照字面意思理解,它应该是为了在读取一定量字节之后,允许我们调用unread方法,重读这部分字节。实现上,它的内部也有一个字节数组作缓冲,恩,看起来一切正常。
可是测试它的unread(byte[])方法的时候发现被坑了,调用unread(byte[])之后再读取,读到的其实是你push进去的这个字节数组。它其实没有想象的那么聪明,在调用unread(byte[])方法的时候,只是很萌的把你传给它的这个字节数组当成你之前读取的数据,把它直接复制到内部缓冲区里。
也就是说,完全是 push what, get what…
ObjectInputStream(ObjectOutputStream)与Serializable接口等一起构成了Java的序列化机制,其中牵涉到对象数据的描述、保存与恢复,在此暂不讨论。
标签:机制 file 多个 基本类型 数组使用 hba ready 本地 imu
原文地址:http://www.cnblogs.com/nsxqf/p/7103692.html