标签:一个 一个个 打印 fill 字段 pre 匹配 under last
文本处理:
假设你存在一个目录,下面存在各种形式的文件,有txt,csv等等。如果你只想找到其中一种或多种格式的文件并打开该如何办呢。首先肯定是要找到满足条件的文件,然后进行路径合并在一一打开。
path=r‘D:\test_source‘
filenames=os.listdir(path)
print filenames
ret=[name for name in filenames if name.endswith(‘.txt‘)]
print ret
direct_path=[os.path.join(path,r) for r in ret]
print direct_path[0]
运行结果如下:
[‘1.csv‘, ‘info.txt‘, ‘pycharm2.jpg‘]
[‘info.txt‘]
D:\test_source\info.txt
这个代码中listdir是列出该目录下的所有文件名称。可以看到其中有txt,csv,jpg的文件
[name for name in filenames if name.endswith(‘.txt‘)] 这个是找出其中所有txt文件。其中使用到了name.endswith,endswith的功能就是找到所有满足后缀条件的文件。
找到满足的条件后最后用[os.path.join(path,r) for r in ret] 进行路径归并。最后得到完整的满足条件的文件路径。
那么既然有判断结尾的,有没有可以判断开头的呢。Startswith这个就是判断开头的。
[name for name in filenames if name.startswith(‘1‘)]
这样就把以1开头的文件找出来了。
那么继续发散一下,假如我有如下的文件:假如我只是想以数字开头的txt文件找出来。该如何找呢
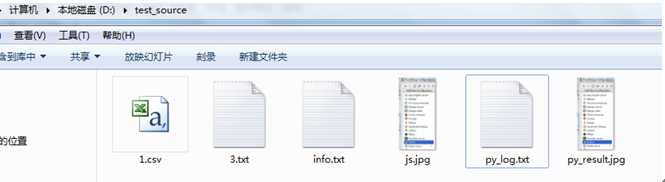
这种情况下需要用到正则表达式来进行匹配,但是endswith和startswith中并不能匹配正则表达式。下面介绍一种功能更强大的功能fnmatch.
方法如下:
可以看到fnmatch中我们用到了正则表达式的方法将以数字开头的txt文件给找出来
ret=[name for name in filenames if fnmatch(name,‘[0-9].txt‘)]
再看下面的方法:这个是匹配所有py开头的文件
ret=[name for name in filenames if fnmatch(name,‘py*‘)]
得到的结果如下:
[‘py_log.txt‘, ‘py_result.jpg‘]
如果我们有一段文本内容,在输出格式上希望改变一下。比如第一行开始空格两行,或者每行显示的字符个数。可以用textwrap来达到
如下面的例子:
textwrap.fill(s,110)是设置每行的字符个数为110个
textwrap.fill(s,80,initial_indent=‘ ‘)是设置每行个数为80个,其中首行以3个空格开头
textwrap.fill(s,80,subsequent_indent=‘ ‘) 是设置每行个数为80个,其中从第二行开始以一个空格开头
def text_wrap_try():
s = "Look into my eyes, look into my eyes, the eyes, the eyes, \
the eyes, not around the eyes, don‘t look around the eyes, \
look into my eyes, you‘re under."
print textwrap.fill(s,110)
print ‘\n‘
print textwrap.fill(s,80,initial_indent=‘ ‘)
print ‘\n‘
print textwrap.fill(s,80,subsequent_indent=‘ ‘)
结果如下:

字符串令牌解析:
在讲这个功能以前,首先介绍2个正则表达式的功能。第一是分组,第二个是带命名的组用法
首先看分组。下面是前面正则表达式中对于分组的定义。括号起来的表达式被一个个的分组
?
看下面的代码,字符串是<h1 class="h1user">crifan</h1>。然后(\S+)和(.+?)是其中2个分组匹配
def re_group():
s=‘<h1 class="h1user">crifan</h1>‘
pattern=re.compile(r‘<(\S+) class="h1user">(.+?)<\/h1>‘)
print pattern.search(s).group(0)
print pattern.search(s).group(1)
print pattern.search(s).group(2)
运行结果如下:可以看到group(0)输出的是整个匹配的字符串。group(1)输出的是h1也就是对应的(\S+),group(2)输出的是crifan,也就是对应的(.+?)

Group1其实对应的是网页代码的tag,group2其实对应的是网页代码的内容。通过索引值来查找对应的值不是很直观。我们能给每个分组起一个名字吗?这样通过名字来找到对应值,就好比字典的功能一样。有的,我们用如下的正则表达式。

代码改成如下:
def re_group():
s=‘<h1 class="h1user">crifan</h1>‘
pattern=re.compile(r‘<(?P<tag>\S+) class="h1user">(?P<text>.+?)<\/h1>‘)
print pattern.search(s).group(0)
print pattern.search(s).group(‘tag‘)
print pattern.search(s).group(‘text‘)
(\S+)和(.+?)被改成了(?P<tag>\S+)以及(?P<text>.+?)。这里解释下?P<tagname>的意义,其实意义上面的说明一目了然,就是给这个分组起了个别名,那么在查找这个分组的时候可以不用索引,直接用这个别名就可以了。上面2个分组分别用了tag和text作为别名。那么在打印分组内容就可以直接使用别名,而不是索引,这样就方便多了。这里引申一下,我们再来看一个这类的高级用法。看下面的字符串,其中我们如果想匹配python study的话,后面内容中也有python study的字段。我们是否可以直接引用前面的匹配分组呢
s1=‘<a href="/tag/python study/">python study</a>‘
代码如下:可以使用(?P=tagname) 就直接使用了之前的tag
pattern1=re.compile(r‘<a href="/tag/(?P<tagname>.+?)/">(?P=tagname)<\/a>‘)
介绍完这2个功能后,我们在来看令牌的功能:
假设我们有一个如下字符串:
text = ‘foo = 23 + 42 * 10‘
我们想得到如下的结果,也就是将各个表达式分解出来,比如等号,加号以及数值
tokens = [(‘NAME‘, ‘foo‘), (‘EQ‘,‘=‘), (‘NUM‘, ‘23‘), (‘PLUS‘,‘+‘),
(‘NUM‘, ‘42‘), (‘TIMES‘, ‘*‘), (‘NUM‘, 10‘)]
我们尝试的代码如下
def pattern_try():
/*首先定义各个匹配模式*/
NAME = r‘(?P<NAME>[a-zA-Z_][a-zA-Z_0-9]*)‘
NUM = r‘(?P<NUM>\d+)‘
PLUS = r‘(?P<PLUS>\+)‘
TIMES = r‘(?P<TIMES>\*)‘
EQ = r‘(?P<EQ>=)‘
WS = r‘(?P<WS>\s+)‘
/*然后汇总所有的正则表达式*/
master_pat = re.compile(‘|‘.join([NAME, NUM, PLUS, TIMES, EQ, WS]))
/*使用scanner进行字符串扫描*/
scanner = master_pat.scanner(‘foo = 23 + 42 * 10‘)
first=scanner.match()
print first.lastgroup,first.group()
first=scanner.match()
print first.lastgroup,first.group()
first=scanner.match()
print first.lastgroup,first.group()
first=scanner.match()
print first.lastgroup,first.group()
得到结果如下:可以看到每次match执行后,都能找到对应的匹配。Lastgroup输出了匹配到的字符别名,group()则是匹配到的具体字符。从上面可以看到scanner是一个可迭代的对象
E:\python2.7.11\python.exe E:/py_prj/python_cookbook.py
NAME foo
WS
EQ =
WS
可以优化下代码:
for m in iter(scanner.match,None):
print m.lastgroup,m.group()
得到的输出如下:
E:\python2.7.11\python.exe E:/py_prj/python_cookbook.py
NAME foo
WS
EQ =
WS
NUM 23
WS
PLUS +
WS
NUM 42
WS
TIMES *
WS
NUM 10
python cookbook第三版学习笔记四:文本以及字符串令牌解析
标签:一个 一个个 打印 fill 字段 pre 匹配 under last
原文地址:http://www.cnblogs.com/zhanghongfeng/p/7106031.html