标签:判断 lin 设计 base profiling 运行环境 iat 影响 空间
这一章节的内容实用性不强 所以不再手打笔记 转载了一篇 原文地址是http://blog.csdn.net/qq_27350929/article/details/54837595
在部分的商用虚拟机中,Java程序最初是通过解释器(Interpreter)进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为"热点代码"(Hot Spot Code)。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个过程的编译器称为即时编译器(Just In Time Compiler)
java虚拟机规范中没有规定即时编译器应该如何实现,也没有规定虚拟机必需拥有即时编译器,这部分功能完全是虚拟机具体实现相关的内容。本文中提及的编译器、即时编译器都是指HotSpot虚拟机内的即时编译器
HotSpot虚拟机采用解释器与编译器并存的架构,解释器与编译器两者各有优势:
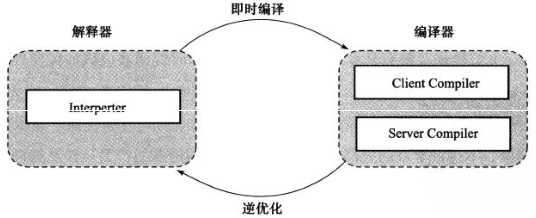
HotSpot虚拟机中内置了两个即时编译器,分别称为Client Compiler和Server Compiler,或者简称为C1编译器和C2编译器,虚拟机默认采用解释器与其中一个编译器直接配合的方式工作
由于即时编译器编译本地代码需要占用程序运行时间,要编译出优化程度更高的代码,所花费的时间可能更长;而且想要编译出优化程度更高的代码,解释器可能还要替编译器收集性能监控信息,这对解释执行的速度也有影响。HotSpot虚拟机采用分层编译(Tiered Compilation)的策略,其中包括:
在这两种情况下,都是以整个方法作为编译对象,这种编译方式被称为栈上替换(On Stack Replacement,简称OSR编译,即方法栈帧还在栈上,方法就被替换了)
判断一段代码是不是热点代码,是不是需要触发即时编译,这样的行为称为热点探测(Hot Spot Detection),目前主要的热点探测判定方式有两种:
Server Compiler和Client Compiler两个编译器的编译过程是不一样的
Client Compiler是一个简单快速的三段式编译器,主要的关注点在于局部性的优化,而放弃了许多耗时较长的全局优化手段
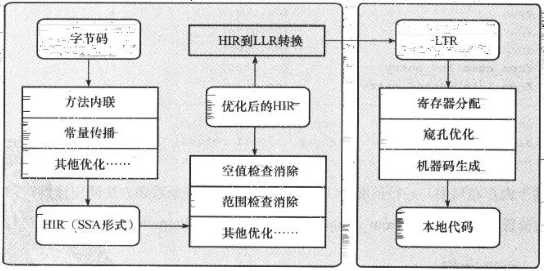
在即时编译器中采用的优化技术有很多,本节主要针对以下四种优化技术:
公共子表达式消除是一个普遍应用与各种编译器的经典优化技术,它的含义是:
如果能证明一个对象不会逃逸到方法或线程之外,则可能为这个变量进行一些高效的优化:
java与C/C++的编译器对比实际上代表了最经典的即时编译器与静态编译器的对比。java虚拟机的即时编译器与C/C++的静态优化编译器相比,可能会由于下列原因而导致输出的本地代码有一些劣势:
标签:判断 lin 设计 base profiling 运行环境 iat 影响 空间
原文地址:http://www.cnblogs.com/xiaolang8762400/p/7107371.html