标签:ges 根据 节点 开始 using jpg insert 表达 bbed
决策树学习是一种逼近离散值目标函数的方法,在这种学习到的函数被表示为一棵决策树。
决策树通过把实例从根节点排列到某个叶子结点来分类实例,叶子结点即为实例所属的分类。树上的每一个结点指定了对实例的某个属性的测试,并且该结点的每一个后续分支对应于该属性的一个可能值。
分类实例的方法是从这棵树的根节点开始,测试这个结点指定的属性,然后按照给定实例的该属性值对应的树枝向下移动。然后这个过程在以新结点为根的子树上重复。
画出了一棵典型的学习到的决策树。
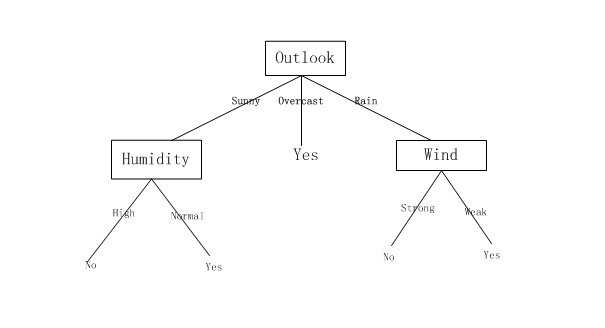
图1
这棵决策树根据天气情况分类“星期六上午是否适合打网球”。例如,下面的实例:
< Outlook=Sunny,Temperature= Hot,Humidity = High ,Wind= Strong >
将被沿着这棵决策树的最左分支向下排列,因而被评定为反例(也就是这棵树预测这个实例Play Tennis = No)。
这棵树以及表 3-2 中用来演示 ID3 学习算法的例子摘自(Quinlan 1986)。
通常决策树代表实例属性值约束的合取(conjunction )的析取式(disjunction)。 从树根到树叶的每一条路径对应一组属性测试的合取,树本身对应这些合取的析取。
例如,图1 表示的决策树对应于以下表达式:
(Outlook=Sunny ? Humidity= Normal) ?(Outlook=Overcast) ?(Outlook=Rain ? Wind=Weak)
基本的ID3 算法通过自顶向下构造决策树来进行学习。
构造过程是从“哪一个属性将在树的根结点被测试?”这个问题开始的。
为了回答这个问题,使用统计测试来确定每一个实例属性单独分类训练样例的能力。
(1)分类能力最好的属性被选作树的根结点的测试。
(2)然后为根结点属性的每个可能值产生一个分支,并把训练样例排列到适当的分支(也就是,样例的该属性值对应的分支)之下。
(3)然后重复整个过程,用每个分支结点关联的训练样例来选取在该点被测试的最佳属性。
这形成了对合格决策树的贪婪搜索(greedy search ),也就是算法从不回溯重新考虑以前的选择。
伪代码

ID3 算法的核心问题是选取在树的每个结点要测试的属性。
我们希望选择的是最有助于分类实例的属性。那么衡量属性价值的一个好的定量标准是什么呢?
这里将定义一个统计属性,称为“信息增益(information gain )”,用来衡量给定的属性区分训练样例的能力。
ID3 算法在增长树的每一步使用这个信息增益标准从候选属性中选择属性。
为了精确地定义信息增益,我们先定义信息论中广泛使用的一个度量标准,称为熵(entropy),它刻画了任意样例集的纯度( purity)。
给定包含关于某个目标概念的正反样例的样例集S ,那么S 相对这个布尔型分类的熵为:
Entropy(S ) =-P⊕log2P⊕-PΘlog2PΘ
其中P⊕ 是在S 中正例的比例,PΘ是在S 中负例的比例。在有关熵的所有计算中我们定义0 log0 为0 。
举例说明,假设S 是一个关于某布尔概念的有 14 个样例的集合,它包括 9 个正例和5 个反例(我们采用记号[9+ ,5 -]来概括这样的数据样例)。
那么S 相对于这个布尔分类的熵(Entropy)为:
Entropy([9+,5-]) =-(9/14)log2(9/14) - (5/14)log2(5/14)
至此我们讨论了目标分类是布尔型的情况下的熵。更一般的,如果目标属性具有 c个不同的值,那么S 相对于 c 个状态(c-wise )的分类的熵定义为:
Entropy(S )=Σ -Pi*log2Pi(1 ≤ i≤ c)
已经有了熵作为衡量训练样例集合纯度的标准,现在可以定义属性分类训练数据的效力的度量标准。这个标准被称为“信息增益(information gain )”。
简单的说,一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低。更精确地讲,一个属性A 相对样例集合 S 的信息增益Gain(S, A)被定义为:
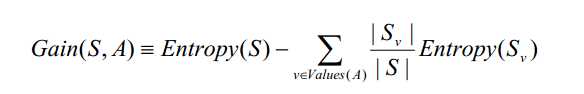
其中 Values (A)是属性A所有可能值的集合,SV 是S 中属性A的值为v 的子集(也就是,Sv ={s∈ S |A(s )=v } )。
请注意,等式的第一项就是原来集合S 的熵,第二项是用A分类S 后熵的期望值。
这个第二项描述的期望熵就是每个子集的熵的加权和,权值|Sv|/|S|为属于S的样例占原始样例S 的比例 。
所以Gain(S , A)是由于知道属性A的值而导致的期望熵减少。换句话来讲,Gain (S , A)是由于给定属性A的值而得到的关于目标函数值的信息。
例如,假定 S 是一套有关天气的训练样例,描述它的属性包括可能是具有 Weak和Strong 两个值的 Wind。像前面一样,假定 S 包含14 个样例,[9+ ,5 -]。在这 14 个样例中,假定正例中的 6 个和反例中的2 个有Wind =Weak,其他的有Wind =Strong。由于按照属性Wind 分类14 个样例得到的信息增益可以计算如下
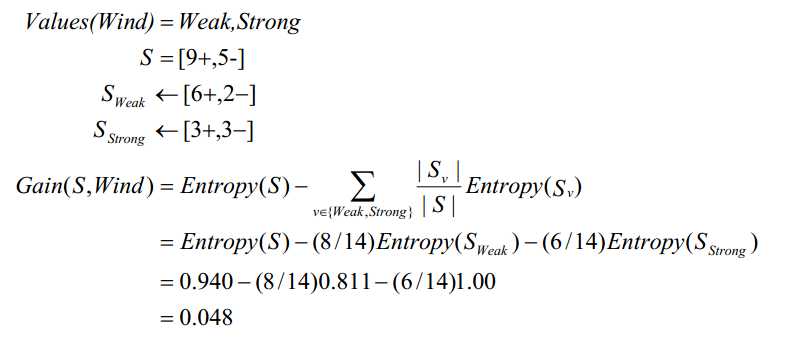
实验举例:
训练样本:

D1 Sunny Hot High Weak No D2 Sunny Hot High Strong No D3 Overcast Hot High Weak Yes D4 Rain Mild High Weak Yes D5 Rain Cool Normal Weak Yes D6 Rain Cool Normal Strong No D7 Overcast Cool Normal Strong Yes D8 Sunny Mild High Weak No D9 Sunny Cool Normal Weak Yes D10 Rain Mild Normal Weak Yes D11 Sunny Mild Normal Strong Yes D12 Overcast Mild High Strong Yes D13 Overcast Hot Normal Weak Yes D14 Rain Mild High Strong No
测试样本:
D1 Sunny Hot High Weak D2 Sunny Hot High Strong D3 Overcast Hot High Weak D4 Rain Mild High Weak D5 Rain Cool Normal Weak D6 Rain Cool Normal Strong D7 Overcast Cool Normal Strong D8 Sunny Mild High Weak D9 Sunny Cool Normal Weak D10 Rain Mild Normal Weak D11 Sunny Mild Normal Strong D12 Overcast Mild High Strong D13 Overcast Hot Normal Weak D14 Rain Mild High Strong
头文件
head.h #ifndef ID3_H_INCLUDED #define ID3_H_INCLUDED #include <map> #include <fstream> #include <vector> #include <set> #include <iostream> #include <cmath> using namespace std; const int DataRow=14; const int DataColumn=6; const int testRow=14; const int testColumn=5; struct Node{ double value; // 标签值,1为YES 0为No int attrid; //属性标号 int attrvalue; //属性值 vector<Node*> childNode; }; #endif // ID3_H_INCLUDED
C++代码
#include "id3.h"
string DataTable[DataRow][DataColumn]; //保存训练样例
string TestTable[testRow][DataColumn]; //保存测试样例
map<string ,int> string2int;
set<int> S;
set<int> Attributes;
string attrName[DataColumn]=
{"Day","OutLook","Temperature","Humidity","Wind","PlayTennis"};
string attrValue[DataColumn][DataColumn]=
{
{},
{"Sunny","Overcast","Rain"},// sunny 1,overcast 2,rain3
{"Hot","Mild","Cool"},//hot 1,mild 2, cool 3
{"High","Normal"},//High 1,normal 2
{"Weak","Strong"}, // weak 1,strong 2
{"Yes","No"} //yes 1,no 2
};
int attrCount[DataColumn]={14,3,3,2,2,2};
double lg2(double n)
{
return log(n)/log(2);
}
void Init() //初始化
{
ifstream fin("dataset.txt");
for(int i=0;i<DataRow;++i)
{
for(int j=0;j<DataColumn;++j)
{
fin>>DataTable[i][j];
}
}
fin.close();
for(int i=1;i<=DataColumn-1;++i)
{
string2int[attrName[i]]=i;
for(int j=0;j<attrCount[i];++j)
string2int[attrValue[i][j]]=j;
}
for(int i=0;i<DataRow;i++)
S.insert(i);
for(int i=1;i<=DataColumn-2;i++)
Attributes.insert(i);
}
double Entropy(const set<int> &s) //计算熵值
{
double yes=0,no=0;
for(set<int>::size_type i=1;i<s.size();i++)
{
if(string2int[DataTable[i][DataColumn-1]]==0)
yes++;
else
no++;
}
if(no==0||yes==0)
return 0;
double Py=yes/s.size();
double Pn=no/s.size();
double ans=-1*Py*lg2(Py)+-1*Pn*lg2(Pn);
return ans;
}
double Gain(const set<int> &s,int attrid) //计算信息增益值
{
double ans=0;
int attrcount = attrCount[attrid];
double sumEntropy = Entropy(s);
set<int> *pset = new set<int>[attrcount];
for(set<int>::const_iterator iter=s.begin();iter!=s.end();iter++)
{
pset[string2int[DataTable[*iter][attrid]]].insert(*iter);
}
for(int i=0;i<attrcount;i++)
{
ans-=(double)pset[i].size()/(double)s.size()*Entropy(pset[i]);
}
return sumEntropy-ans;
}
int FinderBestAttribute(const set<int> &s,const set<int> &attr) //找到最佳分类属性
{
double maxg=0;
int k=-1;
for(set<int>::const_iterator iter=attr.begin();iter!=attr.end();++iter)
{
double tem=Gain(s,*iter);
if(tem>maxg)
{
maxg=tem;
k=*iter;
}
}
int sum=s.size();
sum=attr.size();
if(k==-1)
cout<<"FinderBestAttribute Error!"<<endl;
return k;
}
Node * Id3_solution(set<int> s,set<int> attr)
{
Node * now = new Node();
now->value=-1;
if(attr.empty())
return NULL;
int yes=0,no=0,sum=s.size();
for(set<int>::iterator iter=s.begin();iter!=s.end();iter++)
{
if(DataTable[*iter][DataColumn-1]=="Yes")
yes++;
else
no++;
}
if(yes==sum||no==sum)
{
now->value=yes/sum;
return now;
}
int bestattrid = FinderBestAttribute(s,attr); //找到最佳的分类属性
now->attrid=bestattrid;
attr.erase(attr.find(bestattrid));
vector<set<int> > child=vector<set<int> >(attrCount[bestattrid]);
for(set<int>::iterator iter=s.begin();iter!=s.end();iter++) //插入孩子结点
{
int id = string2int[DataTable[*iter][bestattrid]];
child[id].insert(*iter);
}
for(int i=0;i<child.size();i++) //对孩子结点进行递归调用
{
Node *rel = Id3_solution(child[i],attr);
rel->attrvalue=i;
now->childNode.push_back(rel);
}
return now;
}
void test(Node * Root) //用测试样例进行测试
{
Node* pnow=Root;
ifstream fin("test.txt");
for(int i=0;i<testRow;i++)
{
for(int j=0;j<testColumn;j++)
fin>>TestTable[i][j];
}
fin.close();
for(int i=0;i<testRow;i++)
{
pnow=Root;
while(true)
{
if(pnow->value==1)
{TestTable[i][DataColumn-1]="yes";break;}
else if(pnow->value==0)
{TestTable[i][DataColumn-1]="no";break;}
for(vector<Node*>::iterator iter=pnow->childNode.begin();iter!=pnow->childNode.end();++iter)
{
if((*iter)->attrvalue==string2int[TestTable[i][pnow->attrid]])
{pnow=*iter;
break;}
}
}
}
}
int main()
{
Init();
Node * Root = Id3_solution(S,Attributes);
test(Root);
for(int i=0;i<testRow;i++)
{
for(int j=0;j<DataColumn;j++)
cout<<TestTable[i][j]<<" ";
cout<<endl;
}
return 0;
}
结果:
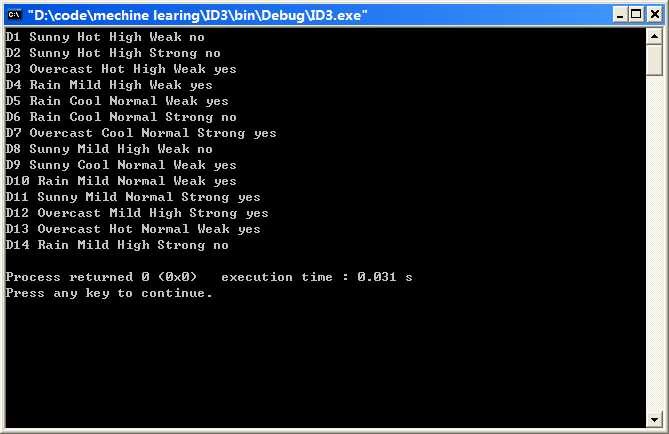
数据挖掘 - 算法 - ID3 - 转自 http://www.cnblogs.com/dztgc/archive/2013/04/22/3036529.html
标签:ges 根据 节点 开始 using jpg insert 表达 bbed
原文地址:http://www.cnblogs.com/pangy/p/7111141.html