标签:线程 hashset 映射关系 泛型 对象 多个 exception 数组 效率
集合框架
概述:
集合框架是java的容器类,专门用来装载对象,基本数据类型会转变成包装类。
数组的特点:长度是固定的。
集合框架的特点:长度是不固定的。
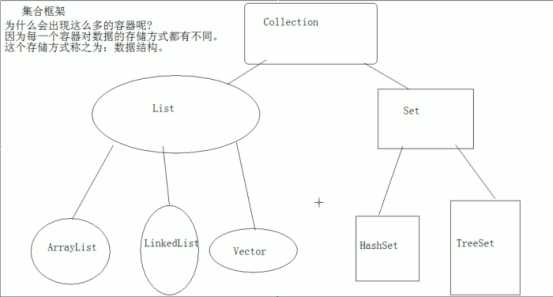
分类:
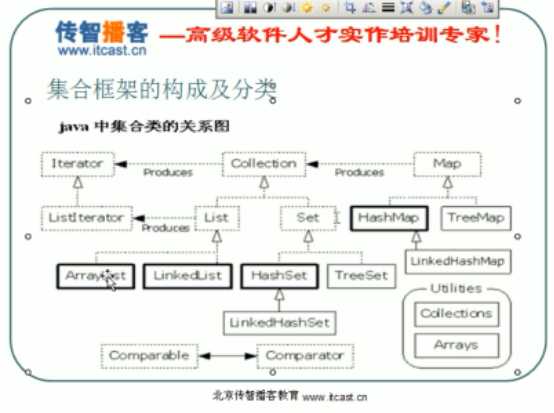
三大接口:
Collection:(基类)
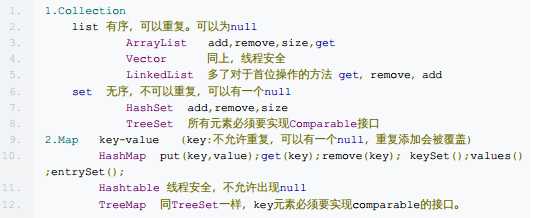
|--List:元素是有序的,元素可以重复。因为该集合体系有索引。
|--ArrayList:底层的数据结构使用的是数组结构。特点:增删快,查找慢。线程不同步。
|--LinkedList:底层使用的链表数据结构。特点:增删慢,查找快。线程不同步。
|--Vector:底层是数组数据结构。线程同步。被ArrayList替代了。因为效率低。(安全)
&& 枚举就是Vector特有的取出方式。发现枚举和迭代器很像。其实枚举和迭代是一样的。因为枚举的名称以及方法的名称都过长。所以被迭代器取代了。
&& Vector --> JDK1.0版本之前,还没有出现ArrayList(JDK1.2版本,取代Vector)
|--Set:元素是无序(存入和取出的顺序不一定一致),元素不可以重复。
|--HashSet:底层数据结构是哈希表()。是线程不安全的。不同步。
保证元素唯一性的原理:判断元素的hashCode值是否相同。如果相同,还会继续判断元素的equals方法,是否为true。
|--TreeSet:
变成了一个有序的 没有重复元素的集合,每一个TreeSet的元素,必须实现一个排序的接口。Comparable,同时 set以排序的字段为标准,如果为0,判断重复,不会添加第二个元素。
底层TreeMap实现 。
底层数据结构是二叉树。保证元素唯一性的依据:compareTo方法return 0.
TreeSet排序的第一种方式:让元素自身具备比较性。元素需要实现Comparable接口,覆盖compareTo方法。也种方式也成为元素的自然顺序,或者叫做默认顺序。
TreeSet的第二种排序方式。当元素自身不具备比较性时,或者具备的比较性不是所需要的。这时就需要让集合自身具备比较性。在集合初始化时,就有了比较方式。
Set集合的功能和Collection是一致的。
List:
特有方法。凡是可以操作角标的方法都是该体系特有的方法。

有序: 有排列顺序,有下标,用下标访问元素。
无序: 没有排列顺序,没有下标,不能直接访问元素



List接口
是一个有序的Collection接口。有下标,可以直接通过下标访问元素。可以添加重复的元素。可以添加多个null元素

三种遍历方法:
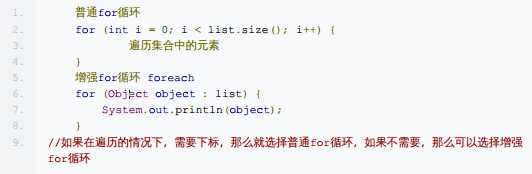

迭代器:
List集合特有的迭代器。ListIterator是Iterator的子接口。在迭代时,不可以通过集合对象的方法操作集合中的元素。
因为会发生ConcurrentModificationException异常。所以,在迭代器时,只能用迭代器的放过操作元素,可是Iterator方法是有限的,
只能对元素进行判断,取出,删除的操作,如果想要其他的操作如添加,修改等,就需要使用其子接口,ListIterator。
该接口只能通过List集合的listIterator方法获取。
Map:
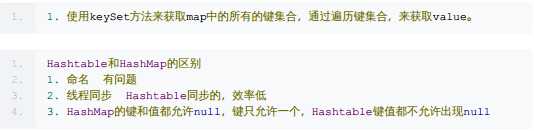
Map是一个key-value的形式存在的,key不能重复,并且只关联到一个value。

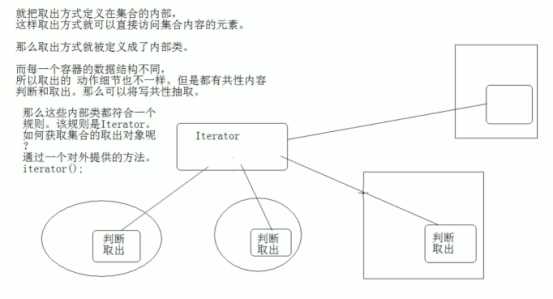
Map集合的两种取出方式:
1,Set<k> keySet:将map中所有的键存入到Set集合。因为set具备迭代器。
所有可以迭代方式取出所有的键,在根据get方法。获取每一个键对应的值。
Map集合的取出原理:将map集合转成set集合。在通过迭代器取出。
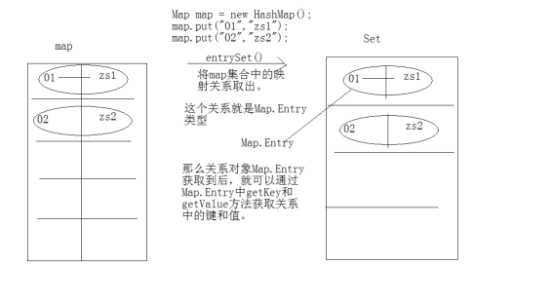
2,Set<Map.Entry<k,v>> entrySet:将map集合中的映射关系存入到了set集合中,
而这个关系的数据类型就是:Map.Entry
Entry其实就是Map中的一个static内部接口。
为什么要定义在内部呢?
因为只有有了Map集合,有了键值对,才会有键值的映射关系。
关系属于Map集合中的一个内部事物。
而且该事物在直接访问Map集合中的元素。
Map的遍历:
泛型:
Java 泛型的参数只可以代表类,不能代表个别对象。由于Java泛型的类型参数之实际类型在
编译时会被消除,所以无法在运行时得知其类型参数的类型。Java编译器在编译泛型时会自动
加入类型转换的编码,故运行速度不会因为使用泛型而加快。Java允许对个别泛型的类型参数
进行约束,包括以下两种形式(假设T是泛型的类型参数,C是一般类、泛类,或是泛型的类型
参数):T实现接口I。T是C,或继承自C。一个泛型类不能实现Throwable接口。
集合所有 的 类图
标签:线程 hashset 映射关系 泛型 对象 多个 exception 数组 效率
原文地址:http://www.cnblogs.com/tawny-tw/p/7097146.html