标签:length private 自己的 res 建议 需要 demo 推荐 输入
前言:俗话说“金三银四铜五”,不知道我要在这段时间找工作会不会很艰难。不管了,工作三年之后就当给自己放个暑假。
面试当中Collection(集合)是基础重点.我在网上看了几篇讲Collection的文章,大多都是以罗列记忆点的形式书写的,没有谈论实现细节和逻辑原理。作为个人笔记无可厚非,但是并不利于他人学习。希望能通过这种比较“费劲”的讲解,帮助我自己、也帮助读者们更好地学习Java、掌握Java.
无论你跟我一样需要应聘,还是说在校学生学习Java基础,都对入门和进一步启发学习有所帮助。(关于Collection已经写过一篇文章,可以在本文最后点击链接阅读)。
1.3 拒绝重复内容的Set
Set,跟数学中的概念“集合”是一样的,就是没有重复的元素。在JavaSE的Cellection框架里,Set是三大阵营之一。根据“核心框架图”,我们可以看到它的位置。
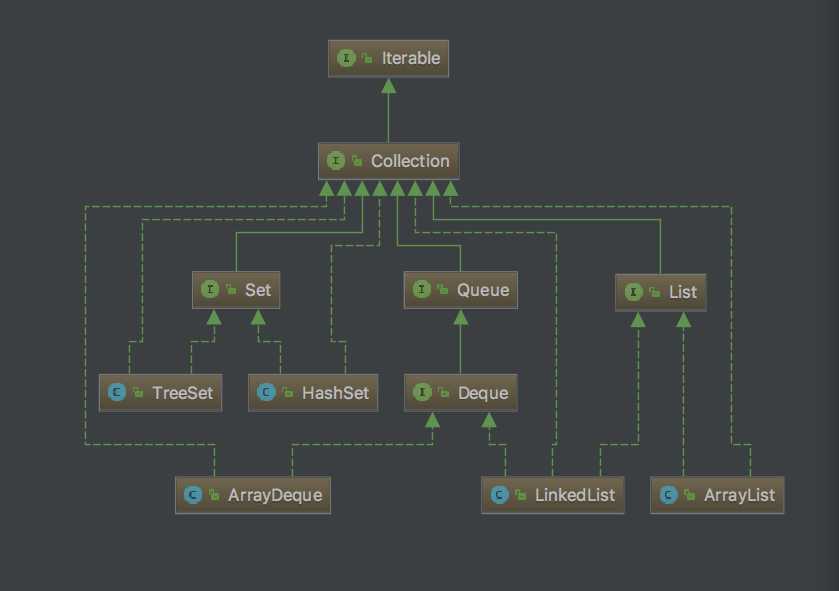
同样一张订单,已经支付过一次就不能再次支付,否则就是重复支付。反映在系统当中,就是收集对象时,如果有相同的对象,则不再重复收集。如果有这类需求,我们可以用使用实现Set接口的类。之前讲过的List和之后会谈到的Queue,都对是否重复没有要求,这是Set的特性。
1.3.1 如何使用HashSet
除非已经是大小牛级别的人能做到触类旁通,否则最好在学习API的时候做几个简单的实验,不仅可以更实际地帮助理解,还可以加深印象有助于长期记忆。
输入一段英文,经过处理后需要输出所有不重复的单词。HashSet实现了Set接口,我们不妨就用它来写一段demo。
1 import java.util.*;
2
3 /**
4 * HashSet的实验用例
5 */
6 public class Words {
7 public static void main(String[] args) {
8 Scanner scanner = new Scanner(System.in);
9 System.out.print("请输入一段话:");
10 String line = scanner.nextLine();
11 String[] tokens = line.split(" ");//根据空格划分单词
12 Set words = new HashSet();
13 for(String token : tokens) {
14 words.add(token);//使用HashSet收集单词
15 }
16 System.out.printf("不重复的单词有:%d 个: %s%n", words.size(), words);
17 }
18 }
英语中分词没有中文分词那么困难,基本上可以按照空格来划分单词。很明显,输出的结果是正确的。

这时候不知道你是否也有这么一个疑问:HashSet是如何判断哪些单词重复的呢?如果让你来做,你会怎么做?
1.3.2 Java中判断重复对象的规范
如果对象是字符串,我们可以采用逐一比较的方式,比较即将收集的字符串和已有的字符串是否相同;如果对象是数值,那就更简单了。可是,除此之外的对象怎么办?我们先来看一个没那么复杂的例子。
1 import java.util.*;
2
3 /**
4 * Set测试用例
5 */
6 class Student {
7 private String name;
8 private String number;
9
10 Student(String name, String number) {
11 this.name = name;
12 this.number = number;
13 }
14
15
16 @Override
17 public String toString() {
18 return String.format("(%s, %s)", name, number);
19 }
20 }
21
22 public class Students {
23 public static void main(String[] args) {
24 Set set = new HashSet();
25 set.add(new Student("Tom", "001"));
26 set.add(new Student("Sam", "002"));
27 set.add(new Student("Tom", "001"));
28 System.out.println(set);
29 }
30 }
上面这段demo是在模拟一个学生注册系统,录入姓名和学号,最后输出已经注册了的学生。由于同一个学生不能注册两次,所以使用了HashSet来收集对象。

这样的输出结果是否出乎你的意料?显然,在执行过程中Set并没有把重复的学生数据排除。其实是我们太一厢情愿了,因为在写程序的时候并没有告诉Set,什么样的Student实例才算是重复。要判断对象是否重复,必须实现hashCode()和equals()方法。在之前的英文分词例子中,对象是String,我们可以在源代码中看到它已经实现了这两个方法。
1 /**
2 * Compares this string to the specified object. The result is {@code
3 * true} if and only if the argument is not {@code null} and is a {@code
4 * String} object that represents the same sequence of characters as this
5 * object.
6 *
7 * @param anObject
8 * The object to compare this {@code String} against
9 *
10 * @return {@code true} if the given object represents a {@code String}
11 * equivalent to this string, {@code false} otherwise
12 *
13 * @see #compareTo(String)
14 * @see #equalsIgnoreCase(String)
15 */
16 public boolean equals(Object anObject) {
17 if (this == anObject) {
18 return true;
19 }
20 if (anObject instanceof String) {
21 String anotherString = (String)anObject;
22 int n = value.length;
23 if (n == anotherString.value.length) {
24 char v1[] = value;
25 char v2[] = anotherString.value;
26 int i = 0;
27 while (n-- != 0) {
28 if (v1[i] != v2[i])
29 return false;
30 i++;
31 }
32 return true;
33 }
34 }
35 return false;
36 }
37
38 /**
39 * Returns a hash code for this string. The hash code for a
40 * {@code String} object is computed as
41 * <blockquote><pre>
42 * s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
43 * </pre></blockquote>
44 * using {@code int} arithmetic, where {@code s[i]} is the
45 * <i>i</i>th character of the string, {@code n} is the length of
46 * the string, and {@code ^} indicates exponentiation.
47 * (The hash value of the empty string is zero.)
48 *
49 * @return a hash code value for this object.
50 */
51 public int hashCode() {
52 int h = hash;
53 if (h == 0 && value.length > 0) {
54 char val[] = value;
55
56 for (int i = 0; i < value.length; i++) {
57 h = 31 * h + val[i];
58 }
59 hash = h;
60 }
61 return h;
62 }
事实上不只有HashSet,Java中许多要判断对象是否重复时,都要求调用hashCode()与equals()方法,因此官方规范中建议这两个方法必须同时实现。如果我们在之前学生注册的例子中添加hashCode()与equals()方法的实现,重复的数据就不会出现。
1 import java.util.*;
2
3 /**
4 * Set测试用例
5 */
6 class Student {
7 private String name;
8 private String number;
9
10 Student(String name, String number) {
11 this.name = name;
12 this.number = number;
13 }
14
15 /**
16 * 重载equals()和hashcode()
17 */
18 @Override
19 public boolean equals(Object obj) {
20 if(obj == null) {
21 return false;
22 }
23 if(getClass() != obj.getClass()) {
24 return false;
25 }
26 final Student other = (Student) obj;
27 return true;
28 }
29
30 @Override
31 public int hashCode() {
32 int hash = 5;
33 hash = 13 * hash + (this.name != null ? this.name.hashCode() : 0);
34 hash = 13 * hash + (this.number != null ? this.number.hashCode() : 0);
35 return hash;
36 }
37
38
39 @Override
40 public String toString() {
41 return String.format("(%s, %s)", name, number);
42 }
43 }
44
45 public class Students {
46 public static void main(String[] args) {
47 Set set = new HashSet();
48 set.add(new Student("Tom", "001"));
49 set.add(new Student("Sam", "002"));
50 set.add(new Student("Tom", "001"));
51 System.out.println(set);
52 }
53 }
重载的hashCode()和equals()方法定义了“如果学生的姓名与学号相同,那就是重复的对象”。当然,你也可以根据自己的理解,改写成“如果学号相同,即为重复”。

1.3.3 Set小结
Set收集对象时,如果发现有重复的数据,会不再收集该对象。如果要实现这一点,必须告知符合什么样的条件才算是“重复”。
Java规范中通过重载hashCode()和equals()方法来判断是否重复。如果你要收集的对象不属于String或Integet之类API已经提供好的类,务必要记得实现这两个方法。
通过学习Set和阅读源代码,不仅可能更好地掌握常用API的用法,同时也会Java规范有了意料之外情理之中的深入了解。无论是对Java的学习,还是日常的开发维护工作,都有不小的帮助。
1.4 支持队列操作的Queue
什么是队列?它是最常用的数据结构之一,只允许在队列的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。
顾名思义,只要是需要“排队”的应用场景,都可以考虑使用队列,例如餐厅的排队系统,医院的器官轮候系统等。
1.4.1 Queue的实现规范
在介绍完List、Set之后,我们来看看Collection的最后一大块Queue.
Queue定义了自己特有的offer()、poll()和peek()等方法。建议优先使用offer()方法,而不是add()方法来收集对象。同样地,pool()和peek()方法建议优先于remove()、element()方法使用。他们最主要的区别在于,add()、remove()、element()方法出错时会抛出异常,offer()、poll()、peek()方法则会返回特定值。
前一篇介绍List的文章就介绍过LinkedList。从反复提及的核心架构图中可以看出,其实它不仅实现了List,同时也是一种Queue。我们不妨就用LinkedList来写一段demo,试着使用队列。
1 import java.util.*;
2
3 /**
4 * Queue实验用例
5 */
6 interface Request {
7 void execute();
8 }
9
10 public class RequestQueue {
11
12 public static void main(String[] args) {
13 Queue requests = new LinkedList();
14 // 模拟将请求加入队列
15 for (int i = 1; i < 6; i++) {
16 requests.offer(new Request() {
17 public void execute() {
18 System.out.printf("处理数据 %f%n", Math.random());
19 }
20 });
21 }
22 process(requests);
23 }
24
25 // 处理队列中的请求
26 private static void process(Queue requests) {
27 while(requests.peek() != null) {
28 Request request = (Request) requests.poll();
29 request.execute();
30 }
31 }
32 }
由于是随机产生的数字,所以几乎每一次实验结果都会不一样,不过这并不重要。

1.4.2 既是队列又是栈的Deque
有的时候,我们会想对队列的前端与尾端进行操作,能在前端加入对象、取出对象,也能在尾端加入对象和取出对象。Queue的子接口Deque可以满足这个需求,我们在核心框架图上可以很容易找到它的位置。
Queue的行为和Deque的行为有所重复,有几个方法是等义的,例如前者的add()等于后者的addLast()方法,建议感兴趣的朋友自行查看源代码或API说明文档。
java.util.ArrayDeque实现了Deque接口,我们可以通过写一段操作容量有限的堆栈的demo来看看如何使用它。
1 import java.util.*;
2
3 /**
4 * Deque实验用例
5 */
6 public class Stack {
7 private Deque deque = new ArrayDeque();
8 private int capacity;
9
10 public Stack(int capacity) {
11 this.capacity = capacity;
12 }
13
14 public boolean push(Object o) {
15 if(deque.size() + 1 > capacity) {
16 return false;
17 }
18 return deque.offerLast(o);
19 }
20
21 public Object pop() {
22 return deque.pollLast();
23 }
24
25 public Object peek() {
26 return deque.peekLast();
27 }
28
29 public int size() {
30 return deque.size();
31 }
32
33 public static void main(String[] args) {
34 Stack stack = new Stack(5);
35 stack.push("小明");
36 stack.push("小花");
37 stack.push("小光");
38 System.out.println(stack.pop());
39 System.out.println(stack.pop());
40 System.out.println(stack.pop());
41 }
42 }
堆栈结构的特性是先进后出,所以运行结果是先显示小光,最后显示小明。

一道思考题:从核心框架图中可以看出LinkedList也实现了Deque接口,不过在这个demo里面,使用ArrayDeque速度上要比LinkedList快。这是为什么?
1.4.3 Quque小结
队列是一种常见而且重要的数据结构,JavaSE中Collection的三大分支之一Quque提供了相应的实现。
Deque是一种双向队列,同时也是Queue的一个子接口。它们之间既有等义的方法,也有不同的实现,具体情况需要阅读API说明文档或直接查看源代码。
我们在学习之前,不妨可以先试着用Java基本语法实现队列、堆栈等数据结构和标准操作方法。在此基础上再阅读相应的源代码(例如LinkedList),会格外发现代码的逻辑之美和整洁之美。
相关文章推荐:
JavaSE中Collection集合框架学习笔记(1)——具有索引的List
如果你喜欢我的文章,可以扫描关注我的个人公众号“李文业的思考笔记”。
不定期地会推送我的原创思考文章。

JavaSE中Collection集合框架学习笔记(2)——拒绝重复内容的Set和支持队列操作的Queue
标签:length private 自己的 res 建议 需要 demo 推荐 输入
原文地址:http://www.cnblogs.com/levenyes/p/7120267.html