标签:字符 自己的 mozilla catch activex 遍历 download 简单 选择器
为什么写这篇文章
授人以鱼不如授人以渔,工作和技术中总会有这样或者那样的新鲜事务出现在我们面前.我们总是希望寻求别的帮助来减少自己的时间成本而忽略了学习才是最根本的解决问题的方案.但是人人并非圣人,哪怕出发点是为了完成工作我们也不要忘了自己的初心.
希望这篇文章能够给予你帮助.有分享我们一起成长.2017-07-07 凌晨3点钟
什么是爬虫
度娘的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
维基百科:网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
我的理解:有时候我们处于特殊目的需要从网上获取某些特定的数据而编写的程序,这些数据的来源可能是静态页面内容,也可能是异步加载的内容.我们需要程序收集并格式化成我们想要的内容.这个程序就是我们所谓的爬虫
那么,作为一个Java程序员,我们有哪些现成的工具呢或者我们如何使用他们呢?
不要忘了,百分之八十以上的Java都是web方向的,我们每时每刻都在和网络打交到
打开你的IDE,或者去翻一下Java API,你找到java.net包或者直接百度他,凡是在工作业务中调用过他人接口的小伙伴,肯定会眼前一亮,对,就是他;
现在我们写下一段代码:
@Test//使用get请求 public void test1() throws IOException { URL realUrl = new URL("http://www.baidu.com"); // 打开和URL之间的连接 URLConnection conn = realUrl.openConnection(); // 设置通用的请求属性 请求头 关于http协议请求头内容可以查看我的另一篇博客:http://www.cnblogs.com/dougest/p/7130147.html conn.setRequestProperty("accept", "*/*"); conn.setRequestProperty("connection", "Keep-Alive"); conn.setRequestProperty("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)"); // 建立实际的连接 conn.connect(); // 定义BufferedReader输入流来读取URL的响应 BufferedReader in = new BufferedReader( new InputStreamReader(conn.getInputStream())); String line; String result = ""; while ((line = in.readLine()) != null) { result += "\n" + line; } System.out.println(result);//打印出百度的html }
在java.net包下封装实现网络应用程序,包括我们常说的socket(套接字),Proxy(代理)等等
有了这些东西,我们就能获取简单的数据或者是开发者暴露出来的接口数据,如果按照上面度娘和维基百科的定义来讲,上面的代码就是我们实现的一个相当简单的爬虫了
现在来讲数据爬取到了,但这并不是我想要的,我想要某个字或者某些内容
这个时候我就要介绍一下Java的两个工具了
我们先看官方的解释
Jsoup官网:https://jsoup.org/
jsoup官方介绍(直接谷歌翻译):
jsoup:Java HTML解析器
jsoup是一个用于处理真实HTML的Java库。它提供了一个非常方便的API来提取和操作数据,使用最好的DOM,CSS和类似jquery的方法。
jsoup实现WHATWG HTML5规范,并将HTML解析为与现代浏览器相同的DOM。
从URL,文件或字符串中刮取并解析 HTML
查找和提取数据,使用DOM遍历或CSS选择器
操纵 HTML元素,属性和文本
根据安全的白名单清理用户提交的内容,以防止XSS攻击
输出整洁的HTML
jsoup旨在处理在野外发现的所有品种的HTML; 从原始和验证,到无效的标签汤; jsoup将创建一个明智的解析树。
httpclient官网:http://hc.apache.org/httpclient-3.x/
httpclient官方介绍(直接谷歌翻译):
HTTP 协议可能是现在 Internet 上使用得最多、最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源。虽然在 JDK 的 java net包中已经提供了访问 HTTP 协议的基本功能,但是对于大部分应用程序来说,JDK 库本身提供的功能还不够丰富和灵活。HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。HttpClient 已经应用在很多的项目中,比如 Apache Jakarta 上很著名的另外两个开源项目 Cactus 和 HTMLUnit 都使用了 HttpClient。
看完这两段官方的介绍,我想这两个工具的异同点是仁者见仁,智者见智了
现在我们的出发点是为了实现一个简单爬虫,仅仅抓取网页还是不够的,我们还要把我们想要的数据格式化,格式化数据相比较而言我还是喜欢用jsoup,因为他太强太神奇了.他可以让我们像使用JavaScript或者css选择器一样去遍历节点,
直接筛出我们想要的东西(异步加载的数据还是有点难度,当然我们后面会提到),关于Jsoup是如何筛选如何使用的,可以参考我的另外一篇博客:可做爬虫的jsoup常用方法,附异步请求实现
@Test public void test2() throws IOException { //Jsoup内部封装了url请求/参数请求等,这里我们直接调用 Document doc = Jsoup.connect("http://news.baidu.com/").get(); System.out.println(doc.text()); }
直接打印你会发现这些都是页面的文本内容,现在我们来筛选出文章标题和链接
在这里说下心得(我对爬虫只是感兴趣属于个人研究,工作中几乎设计不到):爬数据,或者扒数据就是找规律,写代码也是找规律,有点面向规律的问道咯
@Test public void test2() throws IOException { //Jsoup内部封装了http.net的一些方法,使用起来更简单 //获取博客园首页文章信息 Document doc = Jsoup.connect("https://www.cnblogs.com/").get(); Elements elements = doc.getElementsByClass("titlelnk"); for(Element e : elements) { System.out.println("标题==>"+e.text().trim());//获取标题 System.out.println("超链接==>"+e.attr("href"));//获取超链接 } }
现在讲一下关于异步加载的问题,有时候js异步加载确实是个头疼的问题
如果有耐心,可以使用谷歌浏览器去扒接口,比如扒取某某点评的菜价
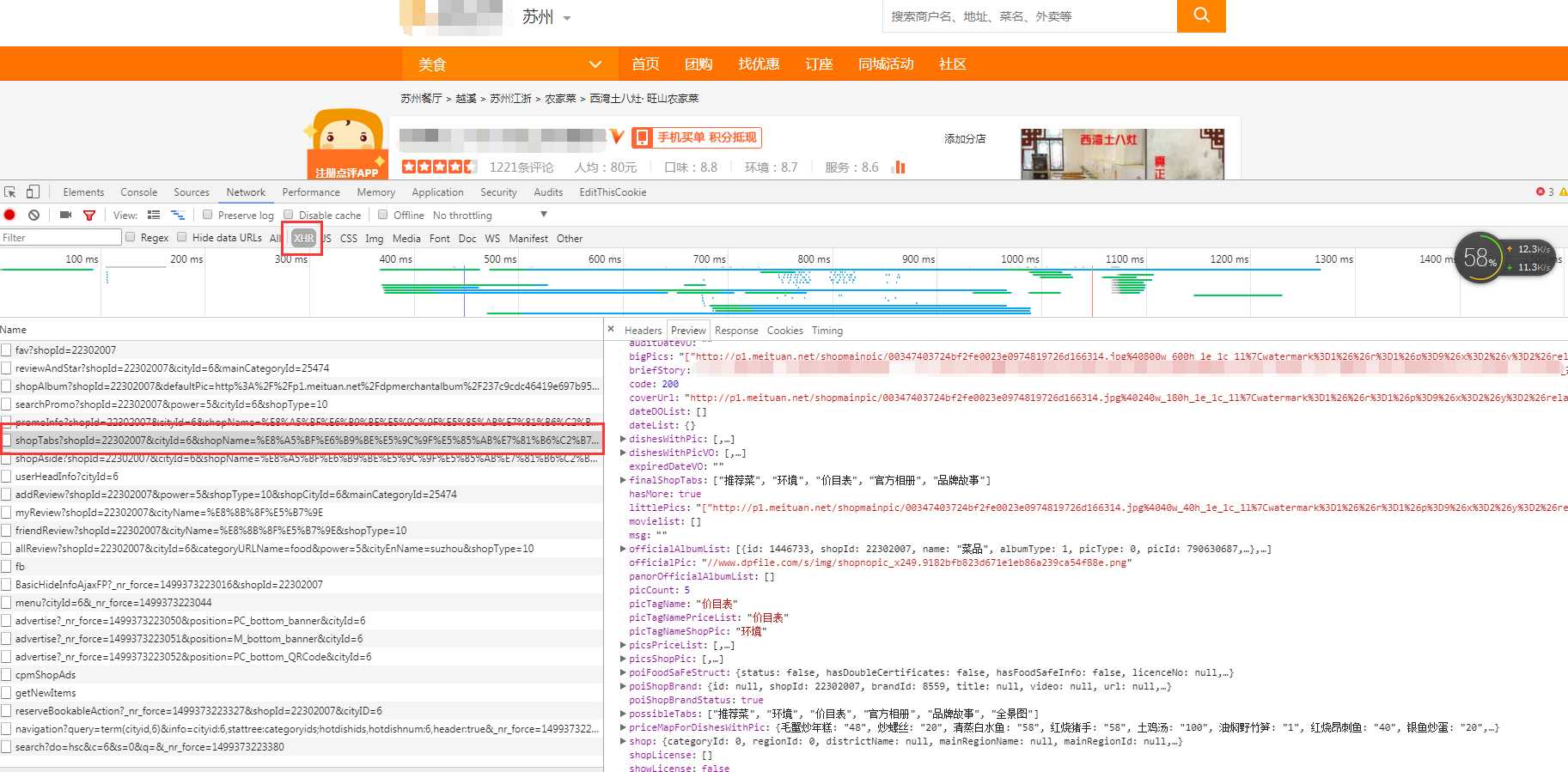
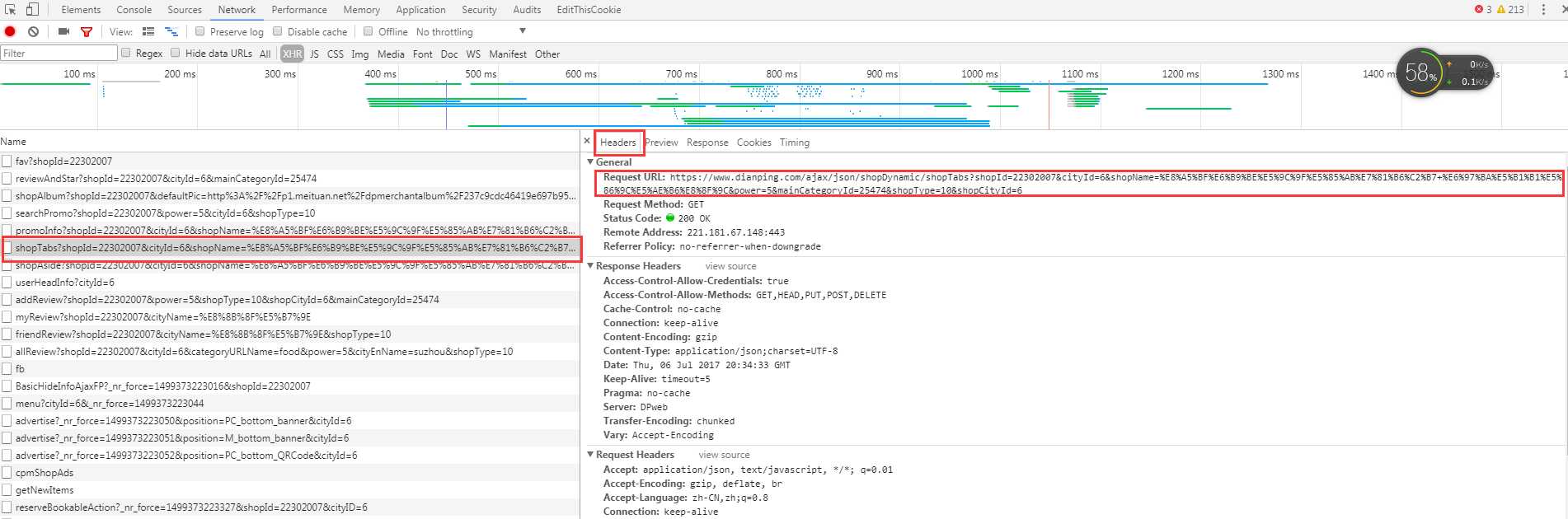
规律就然后就去查看请求的URL以及参数摸规律
有时候某些网站会限制请求频率或者封锁ip
针对请求频率可以设置定时器每隔一段时间访问一次,至于封锁ip手段时间关系你们还是自己百度吧
或者推荐使用htmlunit模仿浏览器执行js,等待js加载执行完毕再去解析html,比如
WebClient webClient = new WebClient(BrowserVersion.CHROME); //支持JavaScript webClient.getOptions().setJavaScriptEnabled(true);//启用JS解释器,默认为true webClient.getOptions().setCssEnabled(false);//禁用css支持 webClient.getOptions().setActiveXNative(false); webClient.getOptions().setCssEnabled(false); webClient.getOptions().setThrowExceptionOnScriptError(false); webClient.getOptions().setThrowExceptionOnFailingStatusCode(false); webClient.getOptions().setTimeout(1*1000); webClient.getOptions().setUseInsecureSSL(true); HtmlPage rootPage = null; try { rootPage = webClient.getPage("https://www.*****.com"); } catch (FailingHttpStatusCodeException e) { e.printStackTrace(); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } //设置一个运行JavaScript的时间 webClient.waitForBackgroundJavaScript(1*1000); String html = rootPage.asXml(); Document doc = Jsoup.parse(html);
或者有精力可以研究一下Selenium
这篇博客现在就先到这里,总之还是那句话,授人以鱼不如授人以渔,简单的介绍之后你肯定会对爬虫有了那么点了解
如果能帮你开启一扇新的大门,我将荣幸之至
但是学习的这条路是没有尽头的
路漫漫其修远兮,吾将上下而求索
路,还很长
Dougest
2017/0707 凌晨4:50
标签:字符 自己的 mozilla catch activex 遍历 download 简单 选择器
原文地址:http://www.cnblogs.com/dougest/p/7130152.html