标签:包括 换行 url app .com detail blank 字符串替换 转义
一、前言
1.1正则表达式简述
正则表达式是一种查找以及字符串替换操作。正则表达式在文本编辑器中广泛使用,比如正则表达式被用于:
1.检查文本中是否含有指定的特征词
2.找出文中匹配特征词的位置
3.从文本中提取信息,比如:字符串的子串
4.修改文本
与文本编辑器相似,几乎所有的高级编程语言都支持正则表达式。在这样的语境下,“文本”也就是一个字符串,可以执行的操作都是类似的。一些编程语言(比如Perl,JavaScript)会检查正则表达式的语法。
1.2 常用的正则匹配工具
在线匹配工具:
1. http://www.regexpal.com/
2. http://rubular.com/
正则匹配软件:
用过几个之后还是觉得这个是最好用的,支持将正则导成对应的语言如java C# js等还帮你转义了,Copy直接用就行了很方便,另外支持把正则表达式用法解释,如哪一段是捕获分组,哪段是贪婪匹配等等,总之用起来 So Happy .
1.3正则表达式语法
\w匹配字母数字及下划线
\W匹配非字母数字及下划线
\s匹配任意空白字符,等价于 [\t\n\r\f].
\S匹配任意非空字符
\d匹配任意数字,等价于 [0-9]
\D匹配任意非数字
\A匹配字符串开始
\Z匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串
\z匹配字符串结束
\G匹配最后匹配完成的位置
\n匹配一个换行符
\t匹配一个制表符
^匹配字符串的开头
$匹配字符串的末尾。
.匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。
[...]用来表示一组字符,单独列出:[amk] 匹配 ‘a‘,‘m‘或‘k‘
[^...]不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。
*匹配0个或多个的表达式。
+匹配1个或多个的表达式。
?匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
{n}精确匹配n个前面表达式。
{n, m}匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式
a|b匹配a或b
( )匹配括号内的表达式,也表示一个组
可能完了之后就有点晕晕的了把,不用担心,下面我们会详细讲解下一些常见的规则的用法。怎么用它来从网页中提取我们想要的信息。
1.4Python中使用
其实正则表达式不是Python独有的,它在其他编程语言中也可以使用,但是Python的re库提供了整个正则表达式的实现,利用re库我们就可以在Python中使用正则表达式来,在Python中写正则表达式几乎都是用的这个库。
下面我们就来了解下它的用法。
match()
在这里首先介绍第一个常用的匹配方法,match()方法,我们向这个方法传入要匹配的字符串以及正则表达式,就可以来检测这个正则表达式是否匹配字符串了。
match()方法会尝试从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果,如果不匹配,那就返回None。
我们用一个实例来感受一下:
import re content =‘Hello 123 4567 World_This a Regex Demo‘ print (len(content)) result = re.match(‘^Hello\s\d\d\d\s\d{4}\s\w{10}‘,content) print result print result.group() print result.span()
输出结果:
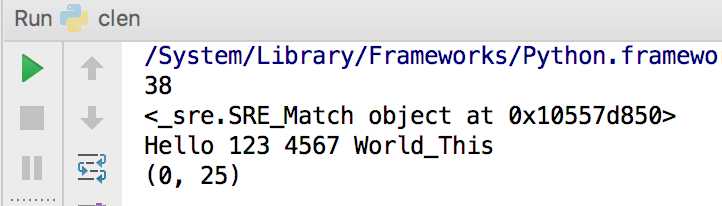
在这里我们首先声明了一个字符串,包含英文字母、空白字符、数字等等内容,接下来我们写了一个正则表达式^Hello\s\d\d\d\s\d{4}\s\w{10}来匹配这个长字符串。
开头的^是匹配字符串的开头,也就是以Hello开头,然后\s匹配空白字符,用来匹配目标字符串的空格,\d匹配数字,三个\d匹配123,然后再写一个\s匹配空格,后面还有4567,我们其实可以依然用四个\d来匹配,但是这么写起来比较繁琐,所以在后面可以跟{4}代表匹配前面的字符四次,也就是匹配四个数字,这样也可以完成匹配,然后后面再紧接一个空白字符,然后\w{10}匹配10个字母及下划线,正则表达式到此为止就结束了,我们注意到其实并没有把目标字符串匹配完,不过这样依然可以进行匹配,只不过匹配结果短一点而已。
我们调用match()方法,第一个参数传入了正则表达式,第二个参数传入了要匹配的字符串。
打印输出一下结果,可以看到结果是SRE_Match对象,证明成功匹配,它有两个方法,group()方法可以输出匹配到的内容,结果是Hello 123 4567 World_This,这恰好是我们正则表达式规则所匹配的内容,span()方法可以输出匹配的范围,结果是(0, 25),这个就是匹配到的结果字符串在原字符串中的位置范围。
通过上面的例子我们可以基本了解怎样在Python中怎样使用正则表达式来匹配一段文字。
二、正则表达式练习
1、求非负整数 : ^\d+$
Tips:需要注意的是这个匹配模式为多行模式下进行的
2、匹配正整数: ^[1-9]*[1-9][0-9]*$ 在网上也有这种写法的 ^[0-9]*[1-9][0-9]*$
这里截图我也不贴了,前者指能匹配123012这种整数,而后者可以匹配001230。
取舍就看实际的需要了
3、非正整数:^(-\d+|(0+))$
4、负整数:^-[0-9]*[1-9][0-9]*$
5、整数 :^-?\d+$
6、非负浮点数 :^\d+(\.\d+)?$
7、正浮点数 :^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
8、非正浮点数 :^((-\d+(\.\d+)?)|(0+(\.0+)?))$
9、负浮点数:^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
10、浮点数:^(-?\d+)(\.\d+)?$
11、有数字、26个英文字母组成的字符串:^[A-Za-z0-9]+$
1、长度为8-10的用户密码(以字母开头、数字、下划线)
^[a-zA-Z]\w{7,10}$
2、验证输入只能是汉字 : ^[\u4e00-\u9fa5]{0,}$
3、电子邮箱验证:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
4、URL地址验证:^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
5、电话号码的验证:请参考:http://blog.csdn.net/kiritor/article/details/8733469
6、简单的身份证号验证:\d{15}|\d{18}$
..............................
1、提取并捕获html标签内容:
<a(?: [^>]*)+href=([^ >]*)(?: [^>]*)*>
<OPTION\s.*?>
以上练习是参考网上的。写的不好之处,请大家多多指教。
标签:包括 换行 url app .com detail blank 字符串替换 转义
原文地址:http://www.cnblogs.com/rain007/p/7131107.html


