标签:dom wak methods except 英文名 应用程序 hang files into
上课第10天,打卡:
感谢Egon老师细致入微的讲解,的确有学到东西!
线程:就是一条流水线的执行过程,一条流水线必须属于一个车间; 那这个车间的运行过程就是一个进程; 即一个进程内,至少有一个线程; 进程是一个资源单位,真正干活的是进程里面的线程; 线程是一个执行单位; 多线程:一个车间内有多条流水线,多个流水线共享该车间的资源; 一个进程内有多个线程,多线程共享一个进程的资源; 线程创建的开销要远远小于创建进程的开销; 进程之间更多的是一种竞争关系; 线程之间更多的是一种协作关系; 为何要创建多线程? 即从线程的优点考虑 1.共享资源 2.创建开销比较小 > 就是为了要实现并发的效果
- 1.创建线程的第一种方式-示例1
from threading import Thread
import os
def work():
print(‘线程:%s‘ % os.getpid())
if __name__ == ‘__main__‘:
t = Thread(target=work)
t.start()
print(‘主线程:%s‘ % os.getpid())
---
线程:8028
主线程:8028
- 示例2:子线程id等于主线程id,并且统一个进程下的多个子线程id都一样;
import threading
from threading import Thread
import os
def work():
print(‘线程名字:%s,PID:%s‘ % (threading.current_thread().getName(),os.getpid()))
def work2():
print(‘线程名字:%s,PID:%s‘ % (threading.current_thread().getName(),os.getpid()))
if __name__ == ‘__main__‘:
t = Thread(target=work)
t2 = Thread(target=work)
t.start()
t2.start()
print(‘主线程名字:%s,PID:%s‘ % (threading.current_thread().getName(),os.getpid()))
---
线程名字:Thread-1,PID:7188
线程名字:Thread-2,PID:7188
主线程名字:MainThread,PID:7188
- 2.创建子线程的第二种方式
# 继承 Thread类
import os
from threading import Thread
class Work(Thread):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print(‘子线线程, PID: %s, PPID: %s‘ % (os.getpid(),os.getppid()))
if __name__ == ‘__main__‘:
t = Work(‘standby‘)
t.start()
print(‘我是主线程,PID:%s, PPID: %s‘ % (os.getpid(),os.getppid()))
---
子线线程, PID: 5424, PPID: 6076
我是主线程,PID:5424, PPID: 6076
# threading的一些常用属性
from threading import Thread
import threading
import os,time
def work():
# time.sleep(0.5)
print(‘子线程,PID:%s, PPID: %s‘ % (os.getpid(), os.getppid()))
if __name__ == ‘__main__‘:
t = Thread(target=work)
t.start()
t.join()
print(threading.enumerate()) # 查看当前活跃的线程对象,是一个列表形式,有时候包含子线程,有的时候不包含子线程
print(threading.active_count()) # 当前活跃的线程数目
print(‘主线程,PID:%s, PPID: %s\t我的本质:%s‘ % (os.getpid(), os.getppid(),threading.current_thread().getName()))
‘‘‘
1.没有加t.join() 并且work函数里没有time.sleep(0.5) 这个的情况下:
情况1:
子线程,PID:6048, PPID: 3216
[<_MainThread(MainThread, started 5280)>, <Thread(Thread-1, started 7112)>]
2
主线程,PID:6048, PPID: 3216 我的本质:MainThread
情况2:
子线程,PID:7096, PPID: 3216
[<_MainThread(MainThread, started 4444)>]
1
主线程,PID:7096, PPID: 3216 我的本质:MainThread
2.没写join,但work函数里加上time.sleep(0.5)这一行的情况下:
[<Thread(Thread-1, started 7008)>, <_MainThread(MainThread, started 6604)>]
2
主线程,PID:6592, PPID: 3216 我的本质:MainThread
子线程,PID:6592, PPID: 3216
3.main里加上 join,但是work里没有 sleep的情况下:
子线程,PID:3988, PPID: 3216
[<_MainThread(MainThread, started 6516)>]
1
主线程,PID:3988, PPID: 3216 我的本质:MainThread
‘‘‘
- setDaemon() 和 join()
# 没有设置 setDaemon(True) 和 join() 的情况
from threading import Thread
import time
def say(name):
time.sleep(2)
print(‘%s say hello‘ %name)
if __name__ == ‘__main__‘:
t=Thread(target=say,args=(‘standby‘,))
t.start()
print(‘主线程‘)
print(t.is_alive())
---执行结果---
主线程
True
standby say hello
# 设置 setDaemon(True) , 没有join()的情况
from threading import Thread
import time
def say(name):
time.sleep(2)
print(‘%s say hello‘ %name)
if __name__ == ‘__main__‘:
t=Thread(target=say,args=(‘standby‘,))
t.setDaemon(True)
t.start()
print(‘主线程‘)
print(t.is_alive())
---执行结果:子线程里的print操作并未执行,子线程跟随主线程的退出而被动结束了---
主线程
True
# 设置 join() 但没设置 setDaemon(True) 的情况
from threading import Thread
import time
def say(name):
time.sleep(2)
print(‘%s say hello‘ %name)
if __name__ == ‘__main__‘:
t=Thread(target=say,args=(‘standby‘,))
# t.setDaemon(True)
t.start()
t.join()
print(‘主线程‘)
print(t.is_alive())
---执行结果:主线程等待子线程执行完再往下执行---
standby say hello
主线程
False
# join() 和 setDaemon(True) 都设置的情况
from threading import Thread
import time
def say(name):
time.sleep(2)
print(‘%s say hello‘ %name)
if __name__ == ‘__main__‘:
t=Thread(target=say,args=(‘standby‘,))
t.setDaemon(True)
t.start()
t.join()
print(‘主线程‘)
print(t.is_alive())
---执行结果:join操作使得主线程阻塞了,即等待子线程执行完毕再执行主线程---
standby say hello
主线程
False
- 同一进程下的多个线程共享该进程的资源;
- 1.多线程和多进程开销对比示例
# 创建 500 个线程
import time
from threading import Thread
def work():
a = 99999
b = 101001010010101010
str1 = ‘axaxxchaxchnahxalx‘
str2 = ‘axaxxcedw2312haxchnahxalx‘
str3 = ‘121212axaxxchaxchnahxalx‘
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
if __name__ == ‘__main__‘:
start_time = time.time()
t_l = []
for i in range(500):
t=Thread(target=work)
t_l.append(t)
t.start()
for t in t_l:
t.join()
stop_time = time.time()
print(‘Run time is %s‘ % (stop_time-start_time))
# Run time is 0.05900001525878906
# ++++++++++++++++++++++++++++++++++
# 创建 500 个进程
import time
from multiprocessing import Process
def work():
a = 99999
b = 101001010010101010
str1 = ‘axaxxchaxchnahxalx‘
str2 = ‘axaxxcedw2312haxchnahxalx‘
str3 = ‘121212axaxxchaxchnahxalx‘
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
if __name__ == ‘__main__‘:
start_time = time.time()
p_l = []
for i in range(500):
p=Process(target=work)
p_l.append(p)
p.start()
for p in p_l:
p.join()
stop_time = time.time()
print(‘Run time is %s‘ % (stop_time-start_time))
# Run time is 19.552000045776367
- 2.多线程实现socket,改写之前多进程的方式;
# 通过线程Thread实现socket并发
# 服务端
from threading import Thread
from socket import *
def talk(conn,addr):
try:
while True: #通讯循环
msg=conn.recv(1024)
if not msg:break
print(‘client %s:%s msg:%s‘ % (addr[0], addr[1], msg))
conn.send(msg.upper())
except Exception as e:
print(‘与 ‘,addr,‘ 的通信循环发生的异常:%s‘ % e)
finally:
conn.close()
def server(ip,port):
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind((ip,port))
server.listen(5)
while True: #链接循环
conn,addr=server.accept()
print(‘client: ‘,addr)
t=Thread(target=talk,args=(conn,addr))
t.start()
if __name__ == ‘__main__‘:
server(‘127.0.0.1‘, 8090)
# 客户端
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect((‘127.0.0.1‘,8090))
while True:
msg=input(‘>>: ‘).strip()
if not msg:continue
client.send(msg.encode(‘utf-8‘))
msg=client.recv(1024)
print(msg.decode(‘utf-8‘))
- 3.多线程示例:多线程模拟实现文件编辑器的功能
from threading import Thread
user_input_list = []
formated_list = []
def talk(): # 接收用户输入
while True:
user_input = input(‘>>>\t‘).strip()
if not user_input:
continue
user_input_list.append(user_input)
def format(): # 格式化用户输入,这里只是简单的做了下 upper操作
while True:
if user_input_list:
res = user_input_list.pop()
res = res.upper()
formated_list.append(res)
def save(): # 保存到磁盘中
while True:
if formated_list:
msg = formated_list.pop()
with open(‘db.txt‘,‘a‘) as wf:
wf.write("\n%s" % msg)
if __name__ == ‘__main__‘:
t1 = Thread(target=talk)
t2 = Thread(target=format)
t3 = Thread(target=save)
t1.start()
t2.start()
t3.start()
参考:http://www.dabeaz.com/python/UnderstandingGIL.pdf
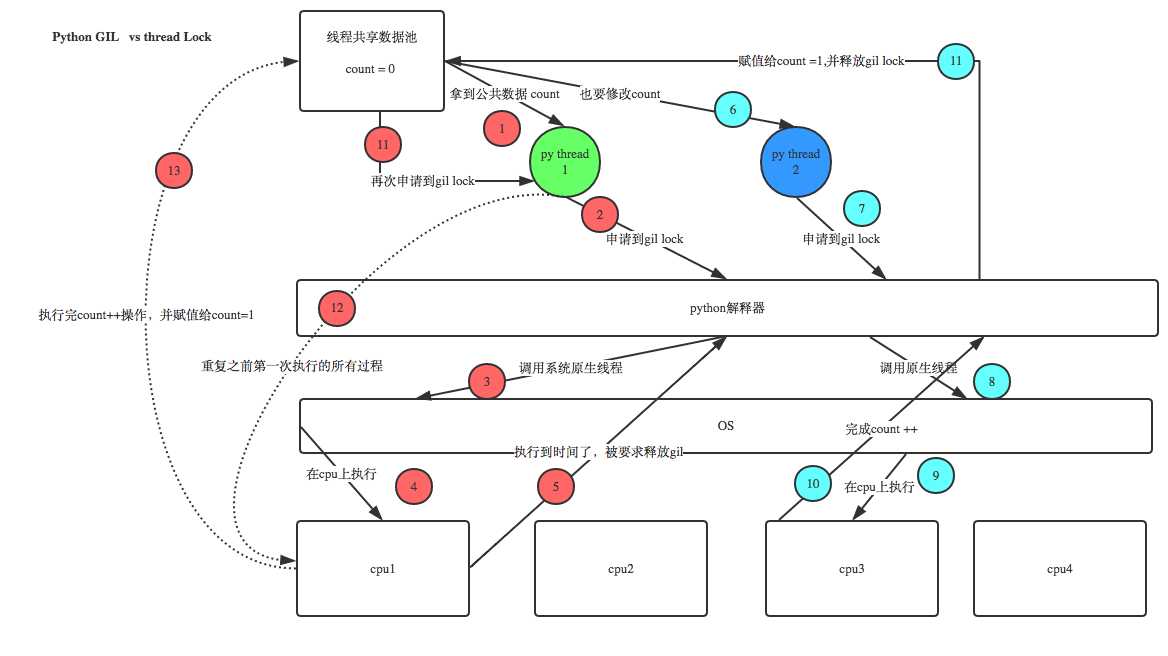
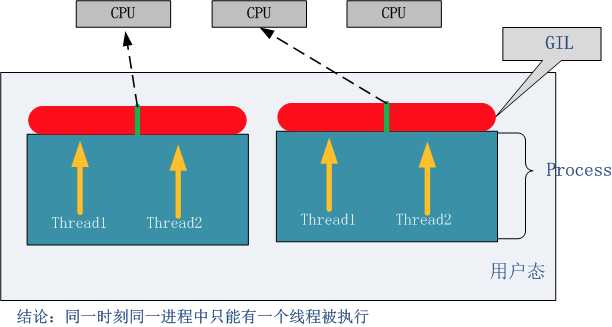
定义: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.) 结论: 在Cpython解释器中: 同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势;
- 首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念;
- GIL使得同一时刻统一进程中只有一个线程被执行;
- 进程可以利用多核,但是开销大,而python的多线程开销小,但却无法利用多核优势;
- GIL 保护的是解释器级别的数据,而Lock保护的是代码级别的数据;(Python的垃圾回收机制)
1. cpu到底是用来做计算的,还是用来做I/O的? 计算 2. 多cpu,意味着可以有多个核并行完成计算,所以多核提升的是计算性能 3. 每个cpu一旦遇到I/O阻塞,仍然需要等待,所以多核对I/O操作没什么用处 结论: 1.对计算来说,cpu越多越好,但是对于I/O来说,再多的cpu也没用 2.当然对于一个程序来说,不会是纯计算或者纯I/O; 我们只能相对的去看一个程序到底是计算密集型还是I/O密集型, 从而进一步分析python的多线程有无用武之地
分析:
我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,越快完成越好;
解决方案可以是:
方案一:开启四个进程
方案二:一个进程下,开启四个线程
- 1.单核情况下
如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜; 如果四个任务是I/O密集型,方案一创建进程的开销大,且进程的切换速度远不如线程,方案二胜;
- 2.多核情况下
如果四个任务是计算密集型,多核意味着并行计算,所以方案一可以实现并行计算; 在Cpython中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜 如果四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜
- 3.结论
现在的计算机基本上都是多核, python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换); 但是,对于IO密集型的任务效率还是有显著提升的;
- 4.实验验证(4核的机器)
# 1.在计算密集型 - 多进程测试
# run time is :34.567999839782715
from multiprocessing import Process
import time
def f1():
res=0
for i in range(100000000):
res += i
if __name__ == ‘__main__‘:
p_l=[]
start_time=time.time()
for i in range(10):
p=Process(target=f1)
p_l.append(p)
p.start()
for p in p_l:
p.join()
stop_time=time.time()
print(‘run time is :%s‘ %(stop_time-start_time))
===
# 1.在计算密集型 - 多线程测试
# run time is :66.21500015258789
from threading import Thread
import time
def f1():
res=0
for i in range(100000000):
res += i
if __name__ == ‘__main__‘:
p_l=[]
start_time=time.time()
for i in range(10):
p=Thread(target=f1)
p_l.append(p)
p.start()
for p in p_l:
p.join()
stop_time=time.time()
print(‘run time is :%s‘ %(stop_time-start_time))
# 2.I/O密集型 - 多进程
# run time is 3.6579999923706055
from multiprocessing import Process
import time
import os
def work():
with open(‘db.txt‘,mode=‘r‘,encoding=‘utf-8‘) as rf:
res = rf.read()
print(‘%s --> %s‘ % (os.getpid(),res))
if __name__ == ‘__main__‘:
t_l=[]
start_time=time.time()
for i in range(100):
t=Process(target=work)
t_l.append(t)
t.start()
for t in t_l:
t.join()
stop_time=time.time()
print(‘run time is %s‘ %(stop_time-start_time))
===
# 2.I/O密集型 - 多线程
# run time is 0.02200007438659668
from threading import Thread
import time
import os
def work():
with open(‘db.txt‘,mode=‘r‘,encoding=‘utf-8‘) as rf:
res = rf.read()
print(‘%s --> %s‘ % (os.getpid(),res))
if __name__ == ‘__main__‘:
t_l=[]
start_time=time.time()
for i in range(100):
t=Thread(target=work)
t_l.append(t)
t.start()
for t in t_l:
t.join()
stop_time=time.time()
print(‘run time is %s‘ %(stop_time-start_time))
- 5.应用场景
多线程用于IO密集型,如socket,爬虫,web; 多进程用于计算密集型,如金融分析;
GIL vs Lock 锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据 保护不同的数据就应该加不同的锁。 GIL 与Lock是两把锁,保护的数据不一样: GIL是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据); Lock是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理; 因为Python解释器帮你自动定期进行内存回收, 你可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的; 此时你自己的程序里的线程和py解释器自己的线程是并发运行的, 假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻, 可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了, 结果就有可能新赋值的数据被删除了!!! 为了解决类似的问题,python解释器简单粗暴的加了锁: 即当一个线程运行时,其它线程都不能动; 这样就解决了上述的问题,这可以说是Python早期版本的遗留问题;
锁通常被用来实现对共享资源的同步访问。 为每一个共享资源创建一个Lock对象, 当你需要访问该资源时,调用acquire方法来获取锁对象 (如果其它线程已经获得了该锁,则当前线程需等待其被释放), 待资源访问完后,再调用release方法释放锁;
- 1.先模拟下没有锁的情况
from threading import Thread
import time
n=100
def work():
global n #在每个线程中都获取这个全局变量
temp=n
time.sleep(0.1)
n=temp-1 # 对此公共变量进行-1操作
if __name__ == ‘__main__‘:
t_l=[]
for i in range(100):
t=Thread(target=work)
t_l.append(t)
t.start()
for t in t_l:
t.join()
print(n)
---
结果是 99 而不是 0
- 2.加互斥锁的情况
from threading import Thread,Lock
import time
n=100
def work():
with mutex: # 或者使用acquire()与release()
global n
temp=n
time.sleep(0.1)
n=temp-1
if __name__ == ‘__main__‘:
mutex = Lock()
t_l=[]
for i in range(100):
t=Thread(target=work)
t_l.append(t)
t.start()
for t in t_l:
t.join()
print(n)
---
结果是 0
死锁是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象; 若无外力作用,它们都将无法推进下去。 此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程;
- 线程共享进程的数据,所以不用把锁当做参数传到子线程中;
- 示例代码:
- 线程1拿到A,然后拿到B,然后释放B,然后释放A,然后再去拿B,此时被释放的A被线程2抢到;
- 线程2想要线程1占据的B锁,线程1想要线程2占据的A锁,并且双方都不释放,最终死锁;
from threading import Thread,Lock
import time
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
mutexA.acquire()
print(‘\033[45m%s 拿到A锁\033[0m‘ %self.name)
mutexB.acquire()
print(‘\033[43m%s 拿到B锁\033[0m‘ % self.name)
mutexB.release()
mutexA.release()
def f2(self):
mutexB.acquire()
time.sleep(1)
print(‘\033[43m%s 拿到B锁\033[0m‘ % self.name)
mutexA.acquire()
print(‘\033[45m%s 拿到A锁\033[0m‘ % self.name)
mutexA.release()
mutexB.release()
if __name__ == ‘__main__‘:
mutexA=Lock()
mutexB=Lock()
for i in range(20):
t=MyThread()
t.start()
---
Thread-1 拿到A锁
Thread-1 拿到B锁
Thread-2 拿到A锁
Thread-1 拿到B锁
然后就卡主了...
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。 这个RLock内部维护着一个Lock和一个counter变量: counter记录了acquire的次数,从而使得资源可以被多次require。 直到一个线程所有的acquire都被release,其他的线程才能获得资源。 上面的例子如果使用RLock代替Lock,则不会发生死锁: mutexA=mutexB=threading.RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1; 这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止;
from threading import Thread,RLock
import time
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
mutexA.acquire()
print(‘\033[45m%s 拿到A锁\033[0m‘ %self.name)
mutexB.acquire()
print(‘\033[43m%s 拿到B锁\033[0m‘ % self.name)
mutexB.release()
mutexA.release()
def f2(self):
mutexB.acquire()
time.sleep(1)
print(‘\033[43m%s 拿到B锁\033[0m‘ % self.name)
mutexA.acquire()
print(‘\033[45m%s 拿到A锁\033[0m‘ % self.name)
mutexA.release()
mutexB.release()
if __name__ == ‘__main__‘:
mutexA=mutexB=RLock() # 递归锁
for i in range(20):
t=MyThread()
t.start()
---
Thread-1 拿到A锁
Thread-1 拿到B锁
Thread-1 拿到B锁
Thread-1 拿到A锁
Thread-2 拿到A锁
Thread-2 拿到B锁
Thread-2 拿到B锁
Thread-2 拿到A锁
Thread-4 拿到A锁
Thread-4 拿到B锁
Thread-4 拿到B锁
Thread-4 拿到A锁
Thread-6 拿到A锁
Thread-6 拿到B锁
Thread-6 拿到B锁
Thread-6 拿到A锁
Thread-8 拿到A锁
Thread-8 拿到B锁
Thread-8 拿到B锁
Thread-8 拿到A锁
Thread-10 拿到A锁
Thread-10 拿到B锁
Thread-10 拿到B锁
Thread-10 拿到A锁
Thread-12 拿到A锁
Thread-12 拿到B锁
Thread-12 拿到B锁
Thread-12 拿到A锁
Thread-14 拿到A锁
Thread-14 拿到B锁
Thread-14 拿到B锁
Thread-14 拿到A锁
Thread-16 拿到A锁
Thread-16 拿到B锁
Thread-16 拿到B锁
Thread-16 拿到A锁
Thread-18 拿到A锁
Thread-18 拿到B锁
Thread-18 拿到B锁
Thread-18 拿到A锁
Thread-20 拿到A锁
Thread-20 拿到B锁
Thread-20 拿到B锁
Thread-20 拿到A锁
Thread-5 拿到A锁
Thread-5 拿到B锁
Thread-5 拿到B锁
Thread-5 拿到A锁
Thread-9 拿到A锁
Thread-9 拿到B锁
Thread-9 拿到B锁
Thread-9 拿到A锁
Thread-13 拿到A锁
Thread-13 拿到B锁
Thread-13 拿到B锁
Thread-13 拿到A锁
Thread-17 拿到A锁
Thread-17 拿到B锁
Thread-17 拿到B锁
Thread-17 拿到A锁
Thread-3 拿到A锁
Thread-3 拿到B锁
Thread-3 拿到B锁
Thread-3 拿到A锁
Thread-11 拿到A锁
Thread-11 拿到B锁
Thread-11 拿到B锁
Thread-11 拿到A锁
Thread-19 拿到A锁
Thread-19 拿到B锁
Thread-19 拿到B锁
Thread-19 拿到A锁
Thread-15 拿到A锁
Thread-15 拿到B锁
Thread-15 拿到B锁
Thread-15 拿到A锁
Thread-7 拿到A锁
Thread-7 拿到B锁
Thread-7 拿到B锁
Thread-7 拿到A锁
Semaphore管理一个内置的计数器,初始化的时候有一个值; 每当调用acquire()时内置计数器-1; 调用release() 时内置计数器+1; 计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
与进程池是完全不同的概念:
进程池Pool(4),最大只能产生4个进程,而且从头到尾都只是这四个进程,不会产生新的;
而信号量是产生一堆线程/进程,但是同时只有n个线程可以获得semaphore并执行;
- 第一种写法
from threading import Semaphore,Thread
import time
def work(num):
with sem:
time.sleep(2)
print(‘%s say hello‘ % num)
if __name__ == ‘__main__‘:
sem = Semaphore(5)
for i in range(20):
t = Thread(target=work,args=(i,))
t.start()
- 第二种写法
import threading
import time
semaphore = threading.Semaphore(5)
def func():
if semaphore.acquire():
print (threading.currentThread().getName() + ‘ get semaphore‘)
time.sleep(2)
semaphore.release()
for i in range(20):
t1 = threading.Thread(target=func)
t1.start()
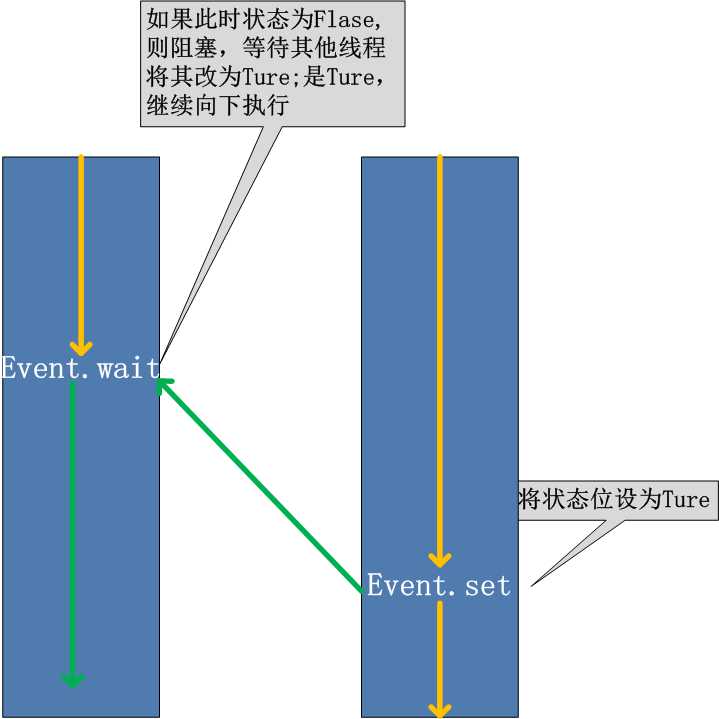
线程的一个关键特性是每个线程都是独立运行且状态不可预测。 如果程序中的其他线程需要通过判断某个线程的状态来确定自己下一步的操作, 这时线程同步问题就 会变得非常棘手。 为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。 在初始情况下,Event对象中的信号标志被设置为假。 如果有线程等待一个Event对象, 而这个Event对象的标志为假, 那么这个线程将会被一直阻塞直至该标志为真。 一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。 如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行;
event.isSet():返回event的状态值; event.wait() :如果 event.isSet()==False将阻塞线程; event.set() :设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
- 连接MySQL示例
import time
import threading
from threading import Event,Thread
def conn_mysql():
print(‘%s waiting...‘ % threading.current_thread().getName())
e.wait()
print(‘%s start to connect mysql...‘ % threading.current_thread().getName())
time.sleep(1)
def check_mysql():
print(‘%s checking...‘ % threading.current_thread().getName())
time.sleep(2)
e.set()
if __name__ == ‘__main__‘:
e = Event()
c1 = Thread(target=conn_mysql)
c2 = Thread(target=conn_mysql)
c3 = Thread(target=conn_mysql)
s = Thread(target=check_mysql)
c1.start()
c2.start()
c3.start()
s.start()
---
Thread-1 waiting...
Thread-2 waiting...
Thread-3 waiting...
Thread-4 checking...
Thread-3 start to connect mysql...
Thread-1 start to connect mysql...
Thread-2 start to connect mysql...
- 连接redis示例
例如,我们有多个线程从Redis队列中读取数据来处理,这些线程都要尝试去连接Redis的服务;
一般情况下,如果Redis连接不成功,在各个线程的代码中,都会去尝试重新连接。
如果我们想要在启动时确保Redis服务正常,才让那些工作线程去连接Redis服务器,
那么我们就可以采用threading.Event机制来协调各个工作线程的连接操作:
主线程中会去尝试连接Redis服务,如果正常的话,触发事件,各工作线程会尝试连接Redis服务。
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG, format=‘(%(threadName)-10s) %(message)s‘,)
def worker(event):
logging.debug(‘Waiting for redis ready...‘)
event.wait()
logging.debug(‘redis ready, and connect to redis server and do some work [%s]‘, time.ctime())
time.sleep(1)
def main():
readis_ready = threading.Event()
t1 = threading.Thread(target=worker, args=(readis_ready,), name=‘t1‘)
t1.start()
t2 = threading.Thread(target=worker, args=(readis_ready,), name=‘t2‘)
t2.start()
logging.debug(‘first of all, check redis server, make sure it is OK, and then trigger the redis ready event‘)
time.sleep(3) # simulate the check progress
readis_ready.set()
if __name__=="__main__":
main()
---
(t1 ) Waiting for redis ready...
(t2 ) Waiting for redis ready...
(MainThread) first of all, check redis server, make sure it is OK, and then trigger the redis ready event
(t2 ) redis ready, and connect to redis server and do some work [Tue Jul 4 00:33:41 2017]
(t1 ) redis ready, and connect to redis server and do some work [Tue Jul 4 00:33:41 2017]
threading.Event的wait方法还接受一个超时参数: 默认情况下如果事件一致没有发生,wait方法会一直阻塞下去; 而加入这个超时参数之后,如果阻塞时间超过这个参数设定的值之后,wait方法会返回; 对应于上面的应用场景,如果Redis服务器一致没有启动,我们希望子线程能够打印一些日志来不断地提醒我们当前没有一个可以连接的Redis服务; 我们就可以通过设置这个超时参数来达成这样的目的;
from threading import Thread,Event
import threading
import time,random
def conn_mysql():
while not event.is_set():
print(‘\033[44m%s 等待连接mysql。。。\033[0m‘ %threading.current_thread().getName())
event.wait(0.5)
print(‘\033[45mMysql初始化成功,%s开始连接。。。\033[0m‘ %threading.current_thread().getName())
def check_mysql():
print(‘\033[41m正在检查mysql。。。\033[0m‘)
time.sleep(random.randint(1,3))
event.set()
time.sleep(random.randint(1,3))
if __name__ == ‘__main__‘:
event=Event()
t1=Thread(target=conn_mysql)
t2=Thread(target=conn_mysql)
t3=Thread(target=check_mysql)
t1.start()
t2.start()
t3.start()
---
Thread-1 等待连接mysql。。。
Thread-2 等待连接mysql。。。
正在检查mysql。。。
Thread-2 等待连接mysql。。。
Thread-1 等待连接mysql。。。
Thread-1 等待连接mysql。。。
Thread-2 等待连接mysql。。。
Thread-2 等待连接mysql。。。
Thread-1 等待连接mysql。。。
Thread-1 等待连接mysql。。。
Thread-2 等待连接mysql。。。
Thread-1 等待连接mysql。。。
Thread-2 等待连接mysql。。。
Mysql初始化成功,Thread-2开始连接。。。
Mysql初始化成功,Thread-1开始连接。。。
from threading import Timer
def hello(name):
print(‘%s say hello‘ % name)
t = Timer(3,hello,args=(‘standby‘,))
t.start()
线程队列queue:使用import queue,用法与进程Queue一样 queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.

1 class Queue: 2 ‘‘‘Create a queue object with a given maximum size. 3 4 If maxsize is <= 0, the queue size is infinite. 5 ‘‘‘ 6 7 def __init__(self, maxsize=0): 8 self.maxsize = maxsize 9 self._init(maxsize) 10 11 # mutex must be held whenever the queue is mutating. All methods 12 # that acquire mutex must release it before returning. mutex 13 # is shared between the three conditions, so acquiring and 14 # releasing the conditions also acquires and releases mutex. 15 self.mutex = threading.Lock() 16 17 # Notify not_empty whenever an item is added to the queue; a 18 # thread waiting to get is notified then. 19 self.not_empty = threading.Condition(self.mutex) 20 21 # Notify not_full whenever an item is removed from the queue; 22 # a thread waiting to put is notified then. 23 self.not_full = threading.Condition(self.mutex) 24 25 # Notify all_tasks_done whenever the number of unfinished tasks 26 # drops to zero; thread waiting to join() is notified to resume 27 self.all_tasks_done = threading.Condition(self.mutex) 28 self.unfinished_tasks = 0 29 30 def task_done(self): 31 ‘‘‘Indicate that a formerly enqueued task is complete. 32 33 Used by Queue consumer threads. For each get() used to fetch a task, 34 a subsequent call to task_done() tells the queue that the processing 35 on the task is complete. 36 37 If a join() is currently blocking, it will resume when all items 38 have been processed (meaning that a task_done() call was received 39 for every item that had been put() into the queue). 40 41 Raises a ValueError if called more times than there were items 42 placed in the queue. 43 ‘‘‘ 44 with self.all_tasks_done: 45 unfinished = self.unfinished_tasks - 1 46 if unfinished <= 0: 47 if unfinished < 0: 48 raise ValueError(‘task_done() called too many times‘) 49 self.all_tasks_done.notify_all() 50 self.unfinished_tasks = unfinished 51 52 def join(self): 53 ‘‘‘Blocks until all items in the Queue have been gotten and processed. 54 55 The count of unfinished tasks goes up whenever an item is added to the 56 queue. The count goes down whenever a consumer thread calls task_done() 57 to indicate the item was retrieved and all work on it is complete. 58 59 When the count of unfinished tasks drops to zero, join() unblocks. 60 ‘‘‘ 61 with self.all_tasks_done: 62 while self.unfinished_tasks: 63 self.all_tasks_done.wait() 64 65 def qsize(self): 66 ‘‘‘Return the approximate size of the queue (not reliable!).‘‘‘ 67 with self.mutex: 68 return self._qsize() 69 70 def empty(self): 71 ‘‘‘Return True if the queue is empty, False otherwise (not reliable!). 72 73 This method is likely to be removed at some point. Use qsize() == 0 74 as a direct substitute, but be aware that either approach risks a race 75 condition where a queue can grow before the result of empty() or 76 qsize() can be used. 77 78 To create code that needs to wait for all queued tasks to be 79 completed, the preferred technique is to use the join() method. 80 ‘‘‘ 81 with self.mutex: 82 return not self._qsize() 83 84 def full(self): 85 ‘‘‘Return True if the queue is full, False otherwise (not reliable!). 86 87 This method is likely to be removed at some point. Use qsize() >= n 88 as a direct substitute, but be aware that either approach risks a race 89 condition where a queue can shrink before the result of full() or 90 qsize() can be used. 91 ‘‘‘ 92 with self.mutex: 93 return 0 < self.maxsize <= self._qsize() 94 95 def put(self, item, block=True, timeout=None): 96 ‘‘‘Put an item into the queue. 97 98 If optional args ‘block‘ is true and ‘timeout‘ is None (the default), 99 block if necessary until a free slot is available. If ‘timeout‘ is 100 a non-negative number, it blocks at most ‘timeout‘ seconds and raises 101 the Full exception if no free slot was available within that time. 102 Otherwise (‘block‘ is false), put an item on the queue if a free slot 103 is immediately available, else raise the Full exception (‘timeout‘ 104 is ignored in that case). 105 ‘‘‘ 106 with self.not_full: 107 if self.maxsize > 0: 108 if not block: 109 if self._qsize() >= self.maxsize: 110 raise Full 111 elif timeout is None: 112 while self._qsize() >= self.maxsize: 113 self.not_full.wait() 114 elif timeout < 0: 115 raise ValueError("‘timeout‘ must be a non-negative number") 116 else: 117 endtime = time() + timeout 118 while self._qsize() >= self.maxsize: 119 remaining = endtime - time() 120 if remaining <= 0.0: 121 raise Full 122 self.not_full.wait(remaining) 123 self._put(item) 124 self.unfinished_tasks += 1 125 self.not_empty.notify() 126 127 def get(self, block=True, timeout=None): 128 ‘‘‘Remove and return an item from the queue. 129 130 If optional args ‘block‘ is true and ‘timeout‘ is None (the default), 131 block if necessary until an item is available. If ‘timeout‘ is 132 a non-negative number, it blocks at most ‘timeout‘ seconds and raises 133 the Empty exception if no item was available within that time. 134 Otherwise (‘block‘ is false), return an item if one is immediately 135 available, else raise the Empty exception (‘timeout‘ is ignored 136 in that case). 137 ‘‘‘ 138 with self.not_empty: 139 if not block: 140 if not self._qsize(): 141 raise Empty 142 elif timeout is None: 143 while not self._qsize(): 144 self.not_empty.wait() 145 elif timeout < 0: 146 raise ValueError("‘timeout‘ must be a non-negative number") 147 else: 148 endtime = time() + timeout 149 while not self._qsize(): 150 remaining = endtime - time() 151 if remaining <= 0.0: 152 raise Empty 153 self.not_empty.wait(remaining) 154 item = self._get() 155 self.not_full.notify() 156 return item 157 158 def put_nowait(self, item): 159 ‘‘‘Put an item into the queue without blocking. 160 161 Only enqueue the item if a free slot is immediately available. 162 Otherwise raise the Full exception. 163 ‘‘‘ 164 return self.put(item, block=False) 165 166 def get_nowait(self): 167 ‘‘‘Remove and return an item from the queue without blocking. 168 169 Only get an item if one is immediately available. Otherwise 170 raise the Empty exception. 171 ‘‘‘ 172 return self.get(block=False) 173 174 # Override these methods to implement other queue organizations 175 # (e.g. stack or priority queue). 176 # These will only be called with appropriate locks held 177 178 # Initialize the queue representation 179 def _init(self, maxsize): 180 self.queue = deque() 181 182 def _qsize(self): 183 return len(self.queue) 184 185 # Put a new item in the queue 186 def _put(self, item): 187 self.queue.append(item) 188 189 # Get an item from the queue 190 def _get(self): 191 return self.queue.popleft()
1 class LifoQueue(Queue): 2 ‘‘‘Variant of Queue that retrieves most recently added entries first.‘‘‘ 3 4 def _init(self, maxsize): 5 self.queue = [] 6 7 def _qsize(self): 8 return len(self.queue) 9 10 def _put(self, item): 11 self.queue.append(item) 12 13 def _get(self): 14 return self.queue.pop()
1 class PriorityQueue(Queue): 2 ‘‘‘Variant of Queue that retrieves open entries in priority order (lowest first). 3 4 Entries are typically tuples of the form: (priority number, data). 5 ‘‘‘ 6 7 def _init(self, maxsize): 8 self.queue = [] 9 10 def _qsize(self): 11 return len(self.queue) 12 13 def _put(self, item): 14 heappush(self.queue, item) 15 16 def _get(self): 17 return heappop(self.queue)
- queue.PriorityQueue()示例
from queue import PriorityQueue
q = PriorityQueue()
#put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((20,‘beijing‘))
q.put((10,(‘hello‘,‘liu‘,)))
q.put((30,{‘k1‘:‘v1‘}))
print(q.get())
print(q.get())
print(q.get())
---结果---
(10, (‘hello‘, ‘liu‘))
(20, ‘beijing‘)
(30, {‘k1‘: ‘v1‘})
1 协程:单线程下的并发,又称微线程;用户态的轻量级线程; 2 > 类似 yield 3 在用户代码级别上实现保存状态,并切换到同线程其他任务去执行; 4 要实现协程,关键在于用户程序自己控制程序切换, 5 切换之前必须由用户程序自己保存协程上一次调用时的状态, 6 如此,每次重新调用时,能够从上次的位置继续执行
协程是单线程下的并发,又称微线程,纤程。英文名Coroutine; 即:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的; 需要强调的是: 1. python的线程属于内核级别的,即由操作系统控制调度(如单线程一旦遇到io就被迫交出cpu执行权限,切换其他线程运行) 2. 单线程内开启协程,一旦遇到io,从应用程序级别(而非操作系统)控制切换; 对比操作系统控制线程的切换,用户在单线程内控制协程的切换,优点如下: 1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级; 2. 单线程内就可以实现并发的效果,最大限度地利用cpu; 要实现协程,关键在于用户程序自己控制程序切换; 切换之前必须由用户程序自己保存协程上一次调用时的状态; 如此,每次重新调用时,能够从上次的位置继续执行 详细的: 协程拥有自己的寄存器上下文和栈。 协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈;
- 示例1:
# 不用yield:每次函数调用,都需要重复开辟内存空间,即重复创建名称空间,因而开销很大
import time
def consumer(item):
# print(item)
x=1212
b=12121212133435
c=999999999
str=‘xsxhaxhalxalxalxmalx‘
str2=‘zsxhaaaaaxhalx121alxalxmalx‘
str3=‘sxh1212axwqwqhalxalxalxmalx‘
str4=‘szzzzxhaxhalxalxsa111alxmalx‘
pass
def producer(target,seq):
for item in seq:
target(item) #每次调用函数,会临时产生名称空间,调用结束则释放,循环100000000次,则重复这么多次的创建和释放,开销非常大
start_time = time.time()
producer(consumer,range(100000000))
stop_time = time.time()
print(‘Run time is : %s‘ % (stop_time-start_time))
# Run time is : 17.020999908447266
- 示例2:
# 使用yield:无需重复开辟内存空间,即重复创建名称空间,因而开销小
import time
def consumer():
x=1212
b=12121212133435
c=999999999
str=‘xsxhaxhalxalxalxmalx‘
str2=‘zsxhaaaaaxhalx121alxalxmalx‘
str3=‘sxh1212axwqwqhalxalxalxmalx‘
str4=‘szzzzxhaxhalxalxsa111alxmalx‘
while True:
item = yield
# print(item)
pass
def producer(target,seq):
for item in seq:
target.send(item) # 无需重新创建名称空间,从上一次暂停的位置继续,相比上例,开销小
g = consumer()
next(g)
start_time = time.time()
producer(g,range(100000000))
stop_time = time.time()
print(‘Run time is : %s‘ % (stop_time-start_time))
# Run time is : 12.491999864578247
- 协程的缺点
缺点: 1.协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程 2.协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
- 协程的定义
协程的定义(满足1,2,3就可称为协程): 1.必须在只有一个单线程里实现并发 2.修改共享数据不需加锁 3.用户程序里自己保存多个控制流的上下文栈 4.附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制)) 另外: yield切换在没有io的情况下或者没有重复开辟内存空间的操作,对效率没有什么提升,甚至更慢;
- 1.greenlet介绍
greenlet是一个用C实现的协程模块; 相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator;
- 2.示例1:
from greenlet import greenlet
def glet1():
print(‘test1,first‘)
gr2.switch()
print(‘test1,sencod‘)
gr2.switch()
def glet2():
print(‘test2,111111111‘)
gr1.switch()
print(‘test2,222222222‘)
if __name__ == ‘__main__‘:
gr1=greenlet(glet1)
gr2=greenlet(glet2)
gr1.switch()
---结果---
test1,first
test2,111111111
test1,sencod
test2,222222222
- 2.示例:传参数
from greenlet import greenlet
def eat(name):
print(‘%s eat food 1‘ %name)
gr2.switch(‘liu‘)
print(‘%s eat food 2‘ %name)
gr2.switch()
def play_phone(name):
print(‘%s play 1‘ %name)
gr1.switch()
print(‘%s play 2‘ %name)
gr1=greenlet(eat)
gr2=greenlet(play_phone)
gr1.switch(name=‘standby‘) #可以在第一次switch时传入参数,以后都不需要
---结果---
standby eat food 1
liu play 1
standby eat food 2
liu play 2
- 3.greenlet只是提供了一种比generator更加便捷的切换方式,仍然是没有解决遇到IO自动切换的问题;
Python通过yield提供了对协程的基本支持,但是不完全。而第三方的gevent为Python提供了比较完善的协程支持。 gevent是第三方库,通过greenlet实现协程,其基本思想是: 1.当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。 2.由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。 3.由于切换是在IO操作时自动完成,所以gevent需要修改Python自带的一些标准库,这一过程在启动时通过monkey patch完成:
- 创建协程对象:g1=gevent.spawn();
- spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的;
- 示例1:没有IO阻塞的情况,可以看到两个协程对象是顺序执行,没有进行切换(因为没有I/O相关操作);
import gevent
import os,threading
def eat(name):
print(‘%s eat food first, pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
print(‘%s eat food second, pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
def play(name):
print(‘%s play phone 1 pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
print(‘%s play phone 2 pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
g1 = gevent.spawn(eat,‘standby‘) # 创建第一个协程对象,要执行的是eat函数,eat函数的参数是 ‘standby‘
g2 = gevent.spawn(play,‘liu‘) # 创建第二个协程对象...
g1.join()
g2.join()
print(‘主线程,PID:%s, Name: %s‘ % (os.getpid(),threading.current_thread().getName()))
---结果---
standby eat food first, pid: 7132, mem: <Greenlet at 0x1105d58: eat(‘standby‘)>
standby eat food second, pid: 7132, mem: <Greenlet at 0x1105d58: eat(‘standby‘)>
liu play phone 1 pid: 7132, mem: <Greenlet at 0x1105f20: play(‘liu‘)>
liu play phone 2 pid: 7132, mem: <Greenlet at 0x1105f20: play(‘liu‘)>
主线程,PID:7132, Name: MainThread
- 示例2:在eat函数和play函数里加入的 gevent.sleep() 模拟I/O操作,可以看到进行的切换;
import gevent
import os,threading
def eat(name):
print(‘%s eat food first, pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
gevent.sleep(1)
print(‘%s eat food second, pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
def play(name):
print(‘%s play phone 1 pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
gevent.sleep(3)
print(‘%s play phone 2 pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
g1 = gevent.spawn(eat,‘standby‘)
g2 = gevent.spawn(play,‘liu‘)
g1.join()
g2.join()
print(‘主线程,PID:%s, Name: %s‘ % (os.getpid(),threading.current_thread().getName()))
---结果---
standby eat food first, pid: 1216, mem: <Greenlet at 0x10f3d58: eat(‘standby‘)>
liu play phone 1 pid: 1216, mem: <Greenlet at 0x10f3f20: play(‘liu‘)>
standby eat food second, pid: 1216, mem: <Greenlet at 0x10f3d58: eat(‘standby‘)>
liu play phone 2 pid: 1216, mem: <Greenlet at 0x10f3f20: play(‘liu‘)>
主线程,PID:1216, Name: MainThread
- 示例3:给gevent模块之外的IO操作打补丁
# 不打补丁的情况
import gevent
import os,threading,time
def eat(name):
print(‘%s eat food first, pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
time.sleep(1)
print(‘%s eat food second, pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
def play(name):
print(‘%s play phone 1 pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
time.sleep(2)
print(‘%s play phone 2 pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
g1 = gevent.spawn(eat,‘standby‘)
g2 = gevent.spawn(play,‘liu‘)
g1.join()
g2.join()
print(‘主线程,PID:%s, Name: %s‘ % (os.getpid(),threading.current_thread().getName()))
---结果---
standby eat food first, pid: 6292, mem: <Greenlet at 0x1134d58: eat(‘standby‘)>
standby eat food second, pid: 6292, mem: <Greenlet at 0x1134d58: eat(‘standby‘)>
liu play phone 1 pid: 6292, mem: <Greenlet at 0x1134f20: play(‘liu‘)>
liu play phone 2 pid: 6292, mem: <Greenlet at 0x1134f20: play(‘liu‘)>
主线程,PID:6292, Name: MainThread
# 打补丁的之后
import gevent
from gevent import monkey;monkey.patch_all() # 给gevent模块之外的IO操作打补丁
import os,threading,time
def eat(name):
print(‘%s eat food first, pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
time.sleep(1)
print(‘%s eat food second, pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
def play(name):
print(‘%s play phone 1 pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
time.sleep(2)
print(‘%s play phone 2 pid: %s, mem: %s‘ % (name,os.getpid(),gevent.getcurrent()))
g1 = gevent.spawn(eat,‘standby‘)
g2 = gevent.spawn(play,‘liu‘)
g1.join()
g2.join()
print(‘主线程,PID:%s, Name: %s‘ % (os.getpid(),threading.current_thread().getName()))
---结果---
standby eat food first, pid: 6804, mem: <Greenlet at 0x2c215a0: eat(‘standby‘)>
liu play phone 1 pid: 6804, mem: <Greenlet at 0x2c21768: play(‘liu‘)>
standby eat food second, pid: 6804, mem: <Greenlet at 0x2c215a0: eat(‘standby‘)>
liu play phone 2 pid: 6804, mem: <Greenlet at 0x2c21768: play(‘liu‘)>
主线程,PID:6804, Name: MainThread
- 应用1:单线程爬去网页内容
- 示例1:没有使用gevent的情况
import requests
import time
def get_page(url):
print(‘Get page: %s‘ % url)
response = requests.get(url)
if 200 == response.status_code:
print(response.text)
start_time = time.time()
get_page(‘https://www.python.org‘)
get_page(‘https://www.yahoo.com‘)
get_page(‘https://www.github.com‘)
get_page(‘https://www.baidu.com/‘)
get_page(‘https://www.stanford.edu/‘)
get_page(‘http://www.hitwh.edu.cn/‘)
stop_time = time.time()
print(‘Run time is : %s‘ % (stop_time-start_time))
# Run time is : 6.61899995803833
- 示例2:使用gevent实现的协程并发
from gevent import monkey;monkey.patch_all()
import gevent
import requests
import time
def get_page(url):
print(‘Get page: %s‘ % url)
response = requests.get(url)
if 200 == response.status_code:
print(response.text)
start_time = time.time()
g1 = gevent.spawn(get_page,url=‘https://www.python.org‘)
g2 = gevent.spawn(get_page,url=‘https://www.yahoo.com‘)
g3 = gevent.spawn(get_page,url=‘https://www.github.com‘)
g4 = gevent.spawn(get_page,url=‘https://www.baidu.com/‘)
g5 = gevent.spawn(get_page,url=‘https://www.stanford.edu/‘)
g6 = gevent.spawn(get_page,url=‘http://www.hitwh.edu.cn/‘)
gevent.joinall([g1,g2,g3,g4,g5,g6])
stop_time = time.time()
print(‘Run time is : %s‘ % (stop_time-start_time))
# Run time is : 3.629999876022339
from gevent import monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前; 或者我们干脆记忆成:要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头;
- 应用2:通过gevent实现单线程下(多协程)的socket并发;
# server端
from gevent import monkey;monkey.patch_all()
from socket import *
import gevent
def server(ip,port):
s = socket(AF_INET, SOCK_STREAM)
s.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
s.bind((ip,port))
s.listen(5)
while True: #连接循环
conn, addr = s.accept()
print(‘client‘,addr)
gevent.spawn(talk,conn,addr)
def talk(conn,addr):
try:
while True: #通信循环
res=conn.recv(1024)
if not res:
break
print(‘client %s:%s msg:%s‘ %(addr[0],addr[1],res))
conn.send(res.upper())
except Exception as e:
print(‘与 ‘, addr, ‘ 的通信循环发生的异常:%s‘ % e)
finally:
conn.close()
if __name__ == ‘__main__‘:
server(‘127.0.0.1‘, 8090)
# client端
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect((‘127.0.0.1‘,8090))
while True:
msg=input(‘>>: ‘).strip()
if not msg:continue
client.send(msg.encode(‘utf-8‘))
msg=client.recv(1024)
print(msg.decode(‘utf-8‘))
- 模拟500个client同时请求,单线程下开启gevent协程实现并发完全可以支撑;
from threading import Thread
from socket import *
import threading
def client(server_ip,port):
c=socket(AF_INET,SOCK_STREAM)
c.connect((server_ip,port))
count=0
while True:
c.send((‘%s say hello %s‘ %(threading.current_thread().getName(),count)).encode(‘utf-8‘))
msg=c.recv(1024)
print(msg.decode(‘utf-8‘))
count+=1
if __name__ == ‘__main__‘:
for i in range(500):
t=Thread(target=client,args=(‘127.0.0.1‘,8090))
t.start()
基于tcp的套接字,关键就是两个循环,一个链接循环,一个通信循环
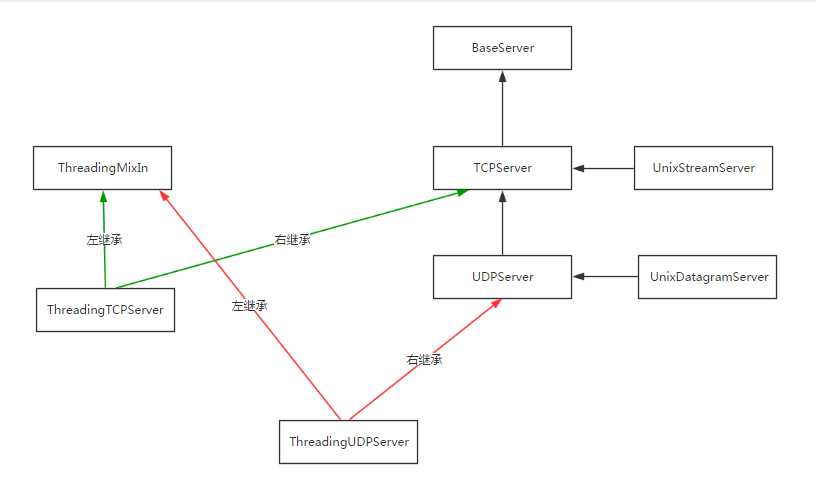
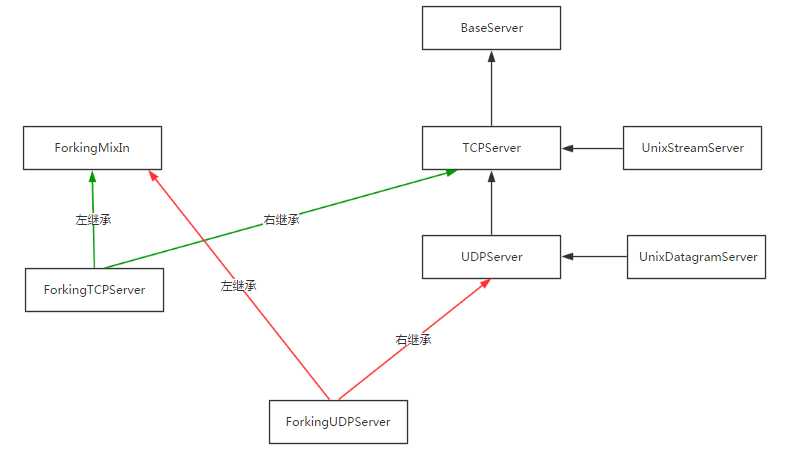
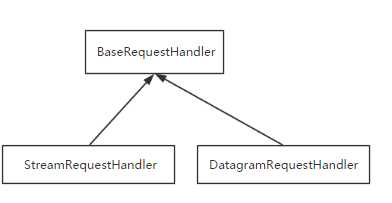
socketserver模块中分两大类:server类(解决链接问题)和request类(解决通信问题)
server类:
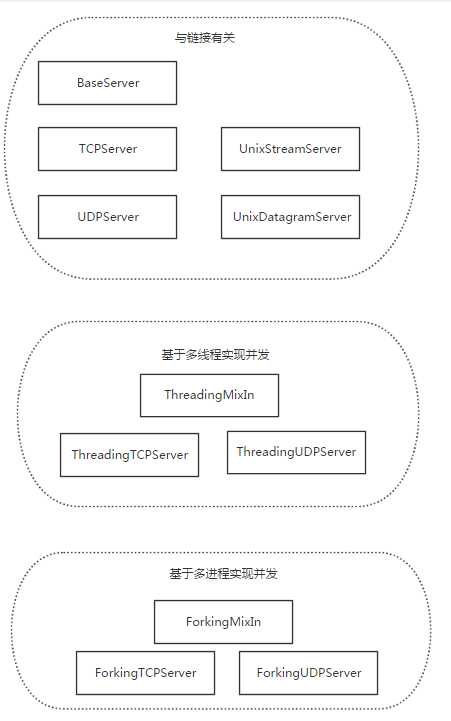
request类:
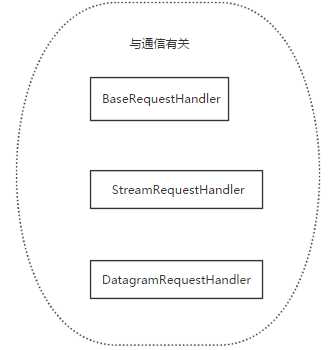
继承关系:
- 简单的代码示:基于TCP的多线程socketserver
# server端
import socketserver
class MyHandler(socketserver.BaseRequestHandler): #通讯循环
def handle(self):
while True:
try:
res=self.request.recv(1024)
print(‘client %s msg:%s‘ %(self.client_address,res))
self.request.send(res.upper())
except Exception as e:
print(‘与 ‘, self.client_address, ‘ 的通信循环发生的异常:%s‘ % e)
break
if __name__ == ‘__main__‘:
s=socketserver.ThreadingTCPServer((‘127.0.0.1‘,8090),MyHandler)
s.serve_forever() #链接循环
# client端
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect((‘127.0.0.1‘,8090))
while True:
msg=input(‘>>: ‘).strip()
if not msg:continue
client.send(msg.encode(‘utf-8‘))
msg=client.recv(1024)
print(msg.decode(‘utf-8‘))
- 详细关系请参照源码;
- 参考:http://www.cnblogs.com/linhaifeng/articles/6129246.html#_label8
- 由于udp无连接,所以可以同时多个客户端去跟服务端通信;
# Part1 发消息,都是将数据发送到己端的发送缓冲中,收消息都是从己端的缓冲区中收; 只有TCP有粘包现象,UDP永远不会粘包; 1. tcp:send发消息,recv收消息 2. udp:sendto发消息,recvfrom收消息 # Part2 send与sendinto tcp是基于数据流的,而udp是基于数据报的: send(bytes_data) 发送数据流,数据流bytes_data若为空,自己这段的缓冲区也为空,操作系统不会控制tcp协议发空包; sendinto(bytes_data,ip_port) 发送数据报,bytes_data为空,还有ip_port, 所有即便是发送空的bytes_data,数据报其实也不是空的,自己这端的缓冲区收到内容,操作系统就会控制udp协议发包; # Part3


单独udp的客户端,发现并不会报错,相反tcp却会报错; 因为udp协议只负责把包发出去,对方收不收,我根本不管; 而tcp是基于链接的,必须有一个服务端先运行着, 客户端去跟服务端建立链接然后依托于链接才能传递消息,任何一方试图把链接摧毁都会导致对方程序的崩溃; udp程序:服务端有几个recvfrom就要对应几个sendinto; TCP 可靠: 有连接,发完消息,对方回一个ack之后,才会清空本地的缓存区; UDP 不可靠: 无连接,发送消息,不需要对方回一个ack;
- 基于UDP的socket,使用 recvfrom 和 sendto来收发消息;
# server端
from socket import *
s=socket(AF_INET,SOCK_DGRAM)
s.bind((‘127.0.0.1‘,8090))
while True:
client_msg,client_addr=s.recvfrom(1024)
print(‘Client: %s‘ % client_msg.decode(‘utf-8‘))
s.sendto(client_msg.upper(),client_addr)
# client端
from socket import *
c=socket(AF_INET,SOCK_DGRAM)
while True:
msg=input(‘>>: ‘).strip()
c.sendto(msg.encode(‘utf-8‘),(‘127.0.0.1‘,8090))
server_msg,server_addr=c.recvfrom(1024)
print(‘Server:%s, Response: %s‘ %(server_addr,server_msg.decode(‘utf-8‘)))
- 基于UDP的socketserver
# server端
import socketserver
class MyUDPhandler(socketserver.BaseRequestHandler):
def handle(self):
client_msg,s=self.request
print(‘Client addr: %s, Msg: %s‘ % (self.client_address,client_msg.decode(‘utf-8‘)))
s.sendto(client_msg.upper(),self.client_address)
if __name__ == ‘__main__‘:
s=socketserver.ThreadingUDPServer((‘127.0.0.1‘,8090),MyUDPhandler)
s.serve_forever()
# client端
from socket import *
c=socket(AF_INET,SOCK_DGRAM)
while True:
msg=input(‘>>: ‘).strip()
c.sendto(msg.encode(‘utf-8‘),(‘127.0.0.1‘,8090))
server_msg,server_addr=c.recvfrom(1024)
print(‘Server:%s, Response: %s‘ %(server_addr,server_msg.decode(‘utf-8‘)))
了解即可
基于socketserver的ftp程序,支持多并发;
1 ftp 2 ├─bin 3 │ │_ run.py 4 │ 5 ├─conf 6 │ │_ config.py 7 │ 8 ├─db 9 │ ├─accounts 10 │ │ ├─alex 11 │ │ │ .pwd 12 │ │ │ 1.txt 13 │ │ │ 123.txt 14 │ │ │ a.txt 15 │ │ │ b.txt 16 │ │ │ haha.py 17 │ │ │ 18 │ │ ├─liu 19 │ │ │ .pwd 20 │ │ │ 1.txt 21 │ │ │ 123.txt 22 │ │ │ a.txt 23 │ │ │ b.txt 24 │ │ │ coding02.py 25 │ │ │ 26 │ │ └─xin 27 │ │ .pwd 28 │ │ 1.txt 29 │ │ a.txt 30 │ │ b.txt 31 │ │ 32 │ └─public 33 │ 1.txt 34 │ 123.txt 35 │ 666.txt 36 │ a.txt 37 │ b.txt 38 │ coding02.py 39 │ haha.py 40 │ 本节内容 41 │ 课前回顾 42 │ 43 └─src 44 │ common.py 45 │ ftp_server.py 46 │_ user.py
具体代码:
#!/usr/bin/python3 # -*- coding:utf-8 -*- # config.py PWD_FILE = ‘.pwd‘ BASE_DIR = r"D:\soft\work\Python_17\day10\hoemwork\db\accounts" PUBLIC_DIR = r"D:\soft\work\Python_17\day10\hoemwork\db\public" DONE = b‘file_send_done‘ PUT_OK = b‘PUT_OK‘ PUT_ERR = b‘PUT_ERR‘ TOTAL_AVAILABLE_SIZE = 1000000 INFO = """ ======================= Welcome to ftp system 1.Login. 2.Register new account. ======================= """ FTP_INFO = """ 1.List all the file you possessed. 2.Show available space. 3.List all public file. 4.Get/Put one file. 5.Increse your capacity. """
#!/usr/bin/python3
# -*- coding:utf-8 -*-
# run.py
import os,sys,time,pickle,getpass,json,struct,socket,hashlib
parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(parent_dir)
from conf.config import *
from src.common import *
from src.user import User
def ftp_run(user_obj):
while True:
cmd_dict = {
‘Q‘:bye,
‘1‘:show_my_files,
‘2‘:show_my_available_space,
‘3‘:show_all_files,
‘4‘:ftp_option,
‘5‘:increse_my_capacity,
}
print(FTP_INFO)
option = input(‘Input your choice, q/Q to exit>>>\t‘).strip().upper()
if option not in cmd_dict:
print(‘Input invalid, bye...‘)
else:
cmd_dict[option](user_obj)
# start here...
print(INFO)
option = input(‘Input option number>>>\t‘).strip()
if option.isdigit() and 1 == int(option):
user_name = input(‘Input your name>>>\t‘).strip()
user_list = os.listdir(BASE_DIR)
if user_name not in user_list:
print(‘No user: %s exist.‘ % user_name)
exit(2)
user_obj_file = r"%s%s%s%s%s" % (BASE_DIR,os.sep,user_name,os.sep,PWD_FILE)
user_obj = pickle.load(open(user_obj_file,‘rb‘))
user_pwd = getpass.getpass(‘Input your passwd>>>\t‘).strip()
if user_pwd == user_obj.passwd:
print(‘\nWelcome %s‘ % user_obj.name)
print(‘Your leave space is %sbytes.‘ % user_obj.available_space)
ftp_run(user_obj)
else:
print(‘Password is incorrect‘)
exit(2)
elif option.isdigit() and 2 == int(option):
name = input(‘Input your name>>>\t‘).strip()
pwd = getpass.getpass(‘Input your passwd>>>\t‘).strip()
capacity = input(‘Input your capacity, unit is Byte(default:1000000)>>>\t‘).strip()
if not capacity:
capacity = TOTAL_AVAILABLE_SIZE
elif not capacity.isdigit():
print(‘Capacity input invalid.‘)
exit(2)
user_list = os.listdir(BASE_DIR)
user = User(name, pwd, capacity)
if user.name not in user_list:
user.save()
print(‘%s created successfully‘ % user.name)
else:
print(‘%s already exist...‘ % user.name)
else:
print(‘Input invalid.‘)
#!/usr/bin/python3
# -*- coding:utf-8 -*-
# ftp_server.py
‘‘‘
1.server run and listen...
2.client conn
3.client send cmd
4.server recv and analyse
5.start to transmission
‘‘‘
import os,sys,time,json,struct,hashlib
import socketserver
parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(parent_dir)
from conf.config import *
class Ftp_Server:
def __init__(self,ip,port):
self.ip = ip
self.port = port
@staticmethod
def get(conn,filename):
print(‘Start to download the %s‘ % filename)
public_file_list = Ftp_Server.get_all_public_file()
# 判断文件是否存在
if filename not in public_file_list:
print("%s does‘t exist, exit." % filename)
file_dict = {
‘flag‘: False,
‘filename‘: filename,
‘hash_value‘: None,
‘file_total_size‘: None
}
file_json = json.dumps(file_dict)
file_byte = file_json.encode(‘utf-8‘)
conn.send(struct.pack(‘i‘, len(file_byte)))
conn.send(file_byte)
return
# 先传输文件的属性:文件大小、文件hash值;
file_total_size = os.path.getsize(r‘%s%s%s‘ % (PUBLIC_DIR,os.sep,filename))
with open(r‘%s%s%s‘ % (PUBLIC_DIR,os.sep,filename),mode=‘rb‘) as rf:
md5_obj = hashlib.md5()
md5_obj.update(rf.read())
file_hash = md5_obj.hexdigest()
file_dict = {
‘flag‘: True,
‘filename‘: filename,
‘hash_value‘: file_hash,
‘file_total_size‘: file_total_size
}
file_json = json.dumps(file_dict)
file_byte = file_json.encode(‘utf-8‘)
conn.send(struct.pack(‘i‘, len(file_byte)))
conn.send(file_byte)
# 开始传输真正的文件内容
with open(r‘%s%s%s‘ % (PUBLIC_DIR,os.sep,filename),mode=‘rb‘) as rf:
while True:
data = rf.read(100)
if not data:
time.sleep(0.1)
conn.send(DONE)
break
else:
conn.send(data)
# print(‘>>>>>>>>>>>>>>>>>>>>>>>>>>>‘)
print(‘%s download done‘ % filename)
conn.close()
@staticmethod
def put(conn,filename):
print(‘Start to upload the %s‘ % filename)
# 接收 file_struct + file_dict
file_struct = conn.recv(4)
file_len = struct.unpack(‘i‘, file_struct)[0]
file_byte = conn.recv(file_len)
file_json = file_byte.decode(‘utf-8‘)
file_dict = json.loads(file_json)
# 循环接收 file_byte 并写入到文件
with open(r‘%s%s%s‘ % (PUBLIC_DIR,os.sep,filename), mode=‘wb‘) as wf:
data = conn.recv(100)
while True:
# print(data)
if DONE == data:
break
wf.write(data)
data = conn.recv(100)
# 获取并比较文件大小和md5值
recv_file_total_size = os.path.getsize(r‘%s%s%s‘ % (PUBLIC_DIR,os.sep,filename))
with open(r‘%s%s%s‘ % (PUBLIC_DIR,os.sep,filename), mode=‘rb‘) as rf:
md5_obj = hashlib.md5()
md5_obj.update(rf.read())
recv_file_hash = md5_obj.hexdigest()
if recv_file_hash == file_dict[‘hash_value‘] and recv_file_total_size == file_dict[‘file_total_size‘]:
conn.send(PUT_OK)
else:
conn.send(PUT_ERR)
print(‘%s upload done.‘ % filename)
conn.close()
@classmethod
def get_all_public_file(cla):
return os.listdir(PUBLIC_DIR)
def start(self):
server = socketserver.ThreadingTCPServer((self.ip, self.port), MyHandler)
server.serve_forever() # 链接循环
class MyHandler(socketserver.BaseRequestHandler): #通讯循环
def handle(self):
while True:
try:
print(‘Client: ‘, self.client_address)
print(self.request)
cmd_struct = self.request.recv(4)
cmd_len = struct.unpack(‘i‘, cmd_struct)[0]
cmd_byte = self.request.recv(cmd_len)
cmd_json = cmd_byte.decode(‘utf-8‘)
cmd_dict = json.loads(cmd_json)
t = time.strftime(‘%Y-%m-%d %X‘)
print(‘User: %s\tTime: %s\tCMD: %s‘ % (cmd_dict[‘user‘], t, cmd_dict[‘cmd‘] + " " + cmd_dict[‘filename‘]))
# 反射到Ftp_Server的get/put方法
func = getattr(Ftp_Server, cmd_dict[‘cmd‘])
func(self.request, cmd_dict[‘filename‘])
except Exception as e:
print(‘与 ‘, self.client_address, ‘ 的通信循环发生的异常:%s‘ % e)
finally:
# 客户端完成一次传输,关闭连接
self.request.close()
break
if __name__ == ‘__main__‘:
ftp_server = Ftp_Server(‘127.0.0.1‘, 8090)
ftp_server.start() # 连接循环
#!/usr/bin/python3
# -*- coding:utf-8 -*-
# user.py
import os,pickle
from conf.config import *
class User():
def __init__(self,name,passwd,capacity):
self.name = name
self.passwd = passwd
self.capacity = capacity
def save(self):
user_path = r"%s%s%s" % (BASE_DIR,os.sep,self.name)
if not os.path.exists(user_path):
os.mkdir(user_path,700)
pwd_file = r"%s%s%s" % (user_path, os.sep, PWD_FILE)
pickle.dump(self, open(pwd_file, ‘wb‘))
def show_all_file(self):
file_list = os.listdir(r"%s%s%s" % (BASE_DIR, os.sep, self.name))
print(‘\n%s have files below:‘ % self.name)
for file in file_list:
if file.startswith(‘.‘):
continue
print(file)
# 获取用户家目录可用空间大小(单位是字节 byte)
@property
def available_space(self):
used_size = 0
path = r"%s%s%s%s" % (BASE_DIR,os.sep,self.name,os.sep)
try:
filename = os.walk(path)
for root, dirs, files in filename:
for fle in files:
size = os.path.getsize(path + fle)
used_size += size
return int(self.capacity) - used_size
except Exception as err:
print(err)
#!/usr/bin/python3
# -*- coding:utf-8 -*-
# common.py
import os,sys,json,hashlib,struct,socket,time
from conf.config import *
from src.ftp_server import Ftp_Server
# 字节bytes转化kb\m\g
def format_size(bytes):
try:
bytes = float(bytes)
kb = bytes / 1024
except:
print("传入的字节格式不对")
return "Error"
if kb >= 1024:
M = kb / 1024
if M >= 1024:
G = M / 1024
return "%fG" % (G)
else:
return "%fM" % (M)
else:
return "%fkb" % (kb)
def bye(user_obj = None):
print(‘See you, %s‘ % user_obj.name)
exit(0)
def show_my_files(user_obj = None):
user_obj.show_all_file()
def show_my_available_space(user_obj = None):
available_space = format_size(user_obj.available_space)
print(available_space)
def show_all_files(user_obj = None):
public_file_list = os.listdir(PUBLIC_DIR)
print(‘==========Public file===========‘)
for file in public_file_list:
print(file)
print(‘================================‘)
def ftp_option(user_obj = None):
input_cmd = input(‘[get/put] filename>>>\t‘).strip()
input_list = input_cmd.split()
if 2 != len(input_list):
print(‘Input invalid, input like this:\nget file\nput file\n‘)
else:
if hasattr(Ftp_Server, input_list[0]):
client_to_run(user_obj, input_list)
else:
print(‘No %s option.‘ % input_list[0])
def increse_my_capacity(user_obj = None):
print(‘Hello %s, your capacity information: %s/%s‘ % (user_obj.name,format_size(user_obj.available_space),format_size(user_obj.capacity)))
increse_space = input(‘How much do you wanna increse(byte) >>>\t‘).strip()
if increse_space.isdigit():
new_capacity = int(user_obj.capacity) + int(increse_space)
user_obj.capacity = new_capacity
user_obj.save()
print(‘Increased successfully\nYour capacity information: %s/%s‘ % (format_size(user_obj.available_space),format_size(user_obj.capacity)))
else:
print(‘Invalid input, must be a number.‘)
def client_to_run(user_obj, input_list):
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((‘127.0.0.1‘, 8090))
cmd_dict = {
‘user‘:user_obj.name,
‘cmd‘:input_list[0],
‘filename‘:input_list[1]
}
cmd_json = json.dumps(cmd_dict)
cmd_byte = cmd_json.encode(‘utf-8‘)
client.send(struct.pack(‘i‘, len(cmd_byte)))
client.send(cmd_byte)
# 从公共目录下载文件到自己的家目录
if ‘get‘ == input_list[0].lower():
# 接收 file_struct + file_dict
file_struct = client.recv(4)
file_len = struct.unpack(‘i‘, file_struct)[0]
file_byte = client.recv(file_len)
file_json = file_byte.decode(‘utf-8‘)
file_dict = json.loads(file_json)
# 判断文件是否存在
if not file_dict[‘flag‘]:
print("%s does‘t exist, exit." % file_dict[‘filename‘])
return
# 判断用户家目录可用空间是否大于要下载的文件大小
if user_obj.available_space < file_dict[‘file_total_size‘]:
print(‘You are have %s byte available only\n%s is %s, download failed.‘ % (user_obj.available_space,input_list[1],file_dict[‘file_total_size‘]))
return
recv_size = 0
# 循环接收 file_real_byte 并写入到文件
with open(r‘%s%s%s%s%s‘ % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]),mode=‘wb‘) as wf:
data = client.recv(100)
f = sys.stdout
while True:
if DONE == data:
break
# print(data)
wf.write(data)
recv_size += len(data)
# 设置下载进度条
pervent = recv_size / file_dict[‘file_total_size‘]
percent_str = "%.2f%%" % (pervent * 100)
n = round(pervent * 60)
s = (‘#‘ * n).ljust(60, ‘-‘)
f.write(percent_str.ljust(8, ‘ ‘) + ‘[‘ + s + ‘]‘)
f.flush()
# time.sleep(0.1)
f.write(‘\r‘)
data = client.recv(100)
f.write(‘\n‘)
recv_file_total_size = os.path.getsize(r‘%s%s%s%s%s‘ % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]))
with open(r‘%s%s%s%s%s‘ % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]),mode=‘rb‘) as rf:
md5_obj = hashlib.md5()
md5_obj.update(rf.read())
recv_file_hash = md5_obj.hexdigest()
print(‘%s %s done.‘ %(input_list[0],input_list[1]))
if recv_file_total_size == file_dict[‘file_total_size‘] and recv_file_hash == file_dict[‘hash_value‘]:
print(‘%s md5 is ok.‘ % input_list[1])
else:
print(‘%s md5 err.‘ % input_list[1])
# print(file_dict[‘filename‘],file_dict[‘hash_value‘],file_dict[‘file_total_size‘])
# 把自己家目录的文件上传到公共目录
elif ‘put‘ == input_list[0].lower():
# 先判断是否存在要上传的文件
if not os.path.exists(r‘%s%s%s%s%s‘ % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1])):
print(‘%s not exist, please check.‘ % input_list[1])
return
# 先传输文件的属性:文件大小、文件hash值;
file_total_size = os.path.getsize(r‘%s%s%s%s%s‘ % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]))
with open(r‘%s%s%s%s%s‘ % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]), mode=‘rb‘) as rf:
md5_obj = hashlib.md5()
md5_obj.update(rf.read())
file_hash = md5_obj.hexdigest()
file_dict = {
‘flag‘: True,
‘filename‘: input_list[1],
‘hash_value‘: file_hash,
‘file_total_size‘: file_total_size
}
file_json = json.dumps(file_dict)
file_byte = file_json.encode(‘utf-8‘)
client.send(struct.pack(‘i‘, len(file_byte)))
client.send(file_byte)
send_size = 0
# 开始传输真正的文件内容
with open(r‘%s%s%s%s%s‘ % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]),mode=‘rb‘) as rf:
while True:
data = rf.read(100)
if not data:
time.sleep(0.1)
client.send(DONE)
break
client.send(data)
# print(‘上传 +1 次‘)
send_size += len(data)
# 设置上传进度条
f = sys.stdout
pervent = send_size / file_dict[‘file_total_size‘]
percent_str = "%.2f%%" % (pervent * 100)
n = round(pervent * 60)
s = (‘#‘ * n).ljust(60, ‘-‘)
f.write(percent_str.ljust(8, ‘ ‘) + ‘[‘ + s + ‘]‘)
f.flush()
# time.sleep(0.1)
f.write(‘\r‘)
f.write(‘\n‘)
print(‘File upload done‘)
upload_res = client.recv(1024)
if upload_res == PUT_OK:
print(‘%s upload ok.‘ % input_list[1])
elif upload_res == PUT_ERR:
print(‘%s upload err.‘ % input_list[1])
else:
print(‘ERROR: %s‘ % upload_res)
client.close()
__all__ = [‘format_size‘,‘bye‘,‘show_my_files‘,‘show_my_available_space‘, ‘show_all_files‘,‘ftp_option‘,‘increse_my_capacity‘]
标签:dom wak methods except 英文名 应用程序 hang files into
原文地址:http://www.cnblogs.com/standby/p/7107519.html
