标签:virtual 日志 bsp black 打开 特殊情况 print jdk7 工程
前言
String字符串在Java应用中使用非常频繁,只有理解了它在虚拟机中的实现机制,才能写出健壮的应用,本文使用的JDK版本为1.8.0_111。

Java代码被编译成class文件时,会生成一个常量池(Constant pool)的数据结构,用以保存字面常量和符号引用(类名、方法名、接口名和字段名等)。

很简单的一段代码,通过命令 javap -verbose 查看class文件中 Constant pool 实现:
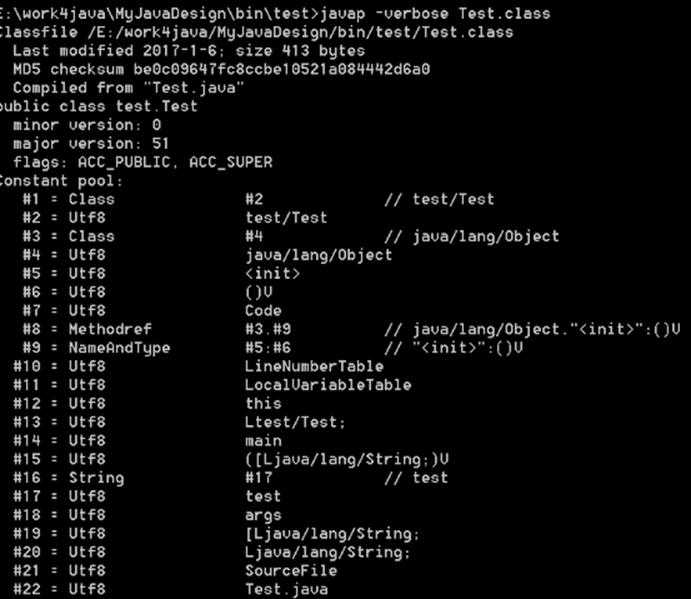
通过反编译出来的字节码可以看出字符串 "test" 在常量池中的定义方式:

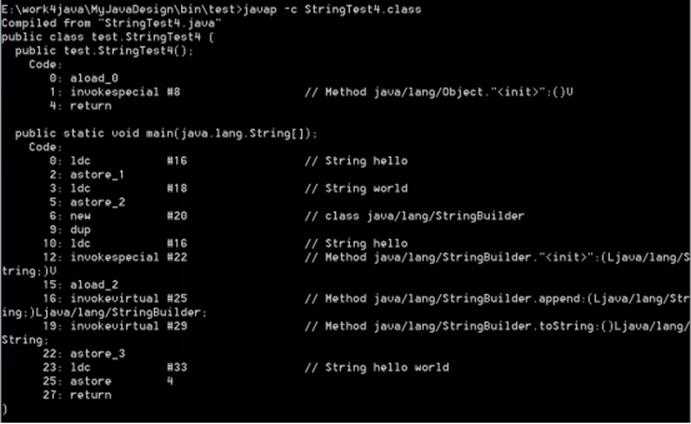
在main方法字节码指令中,0 ~ 2行对应代码 String test = "test"; 由两部分组成:ldc #16和 astore_1。
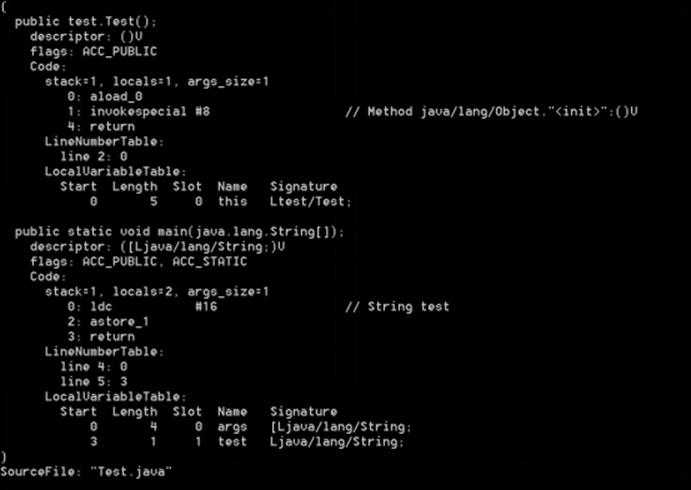
2、astore_1指令将"test"字符串的引用保存在局部变量表中。
1、JDK6及之前版本中,常量池的内存在永久代PermGen进行分配,所以常量池会受到PermGen内存大小的限制。
2、JDK7中,常量池的内存在Java堆上进行分配,意味着常量池不受固定大小的限制了。
字符串可以通过两种方式进行初始化:字面常量和String对象。

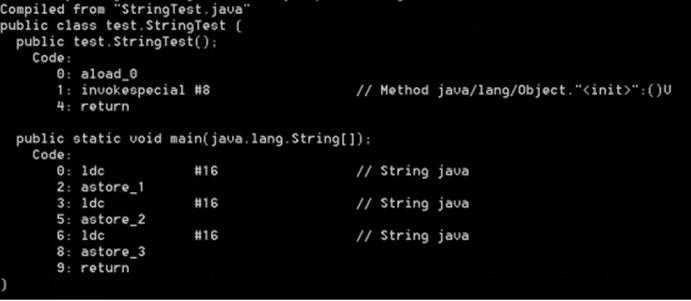
其中ldc指令将int、float和String类型的常量值从常量池中推送到栈顶,所以a和b都指向常量池的"java"字符串。通过指令实现可以发现:变量a、b和c都指向常量池的 "java" 字符串,表达式 "ja" + "va" 在编译期间会把结果值"java"直接赋值给c(编译后指向常量)。

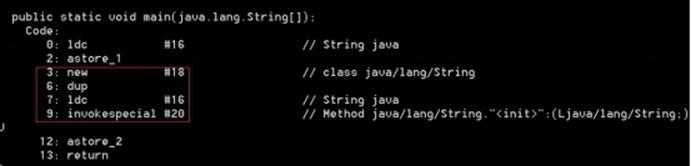
其中3 ~ 9行指令对应代码 String c = new String("java"); 实现:
1、第3行new指令,在Java堆上为String对象申请内存;
2、第7行ldc指令,尝试从常量池中获取"java"字符串,如果常量池中不存在,则在常量池中新建"java"字符串,并返回;
3、第9行invokespecial指令,调用构造方法,初始化String对象。
其中String对象中使用char数组存储字符串,变量a指向常量池的"java"字符串,变量c指向Java堆的String对象,且该对象的char数组指向常量池的"java"字符串,所以很显然 a != c,如下图所示:
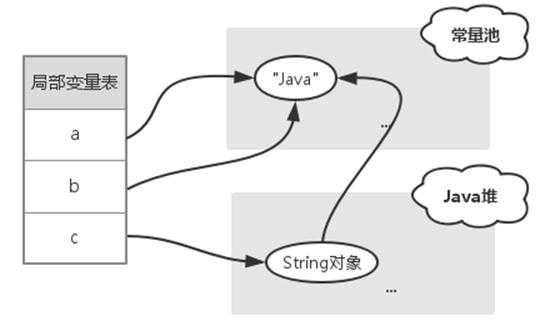
通过 "字面量 + String对象" 进行赋值会发生什么?
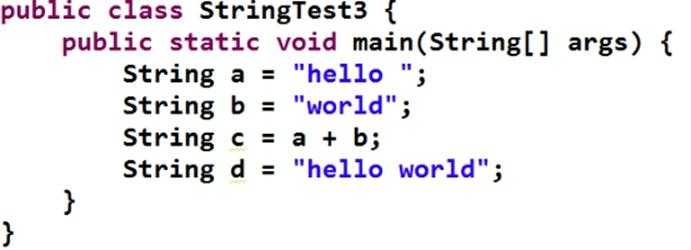
其中6 ~ 21行指令对应代码 String c = a + b; 实现:
1、第6行new指令,在Java堆上为StringBuilder对象申请内存;
2、第10~14行aload_1指令,装载a字符串hello,调用构造方法,初始化StringBuilder对象;(这里本应是两次append,是不是在init时做了优化?)
3、第18行invokevirtual指令,调用append方法,添加b字符串;
4、第21行invokevirtual指令,调用toString方法,生成String对象。
通过指令实现可以发现,字符串变量的连接动作,在编译阶段会被转化成StringBuilder的append操作,变量c最终指向Java堆上新建String对象,变量d指向常量池的"hello world"字符串,所以 c != d。
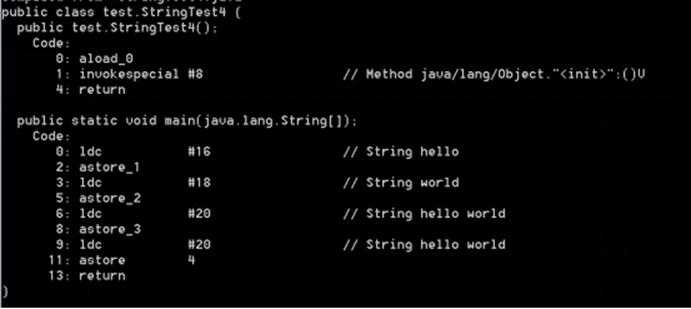
不过有种特殊情况,当final修饰的变量发生连接动作时,虚拟机会进行优化,将表达式结果直接赋值给目标变量:

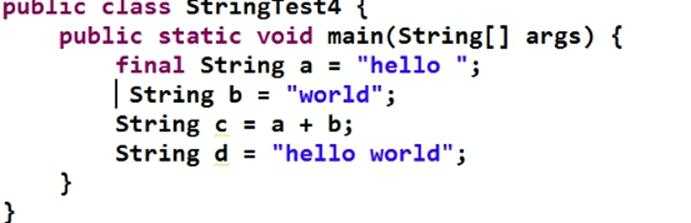

2、JDK7的执行结果:true false
对于这个结果就有点懵了。在JDK7中,常量池已经在Java堆上分配内存,执行intern方法时,如果常量池已经存在该字符串,则直接返回字符串引用,否则复制该字符串对象的引用到常量池中并返回,所以在JDK7中,可以重新考虑使用intern方法,减少String对象所占的内存空间。
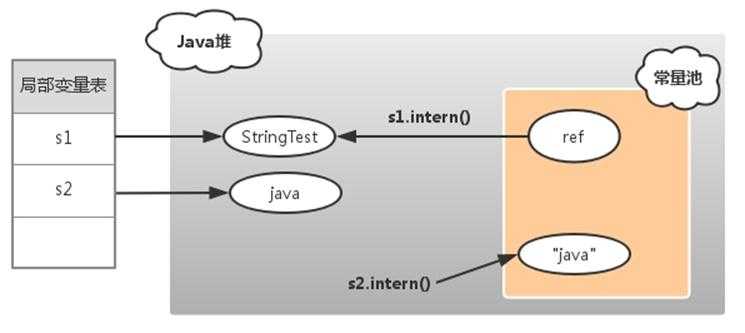
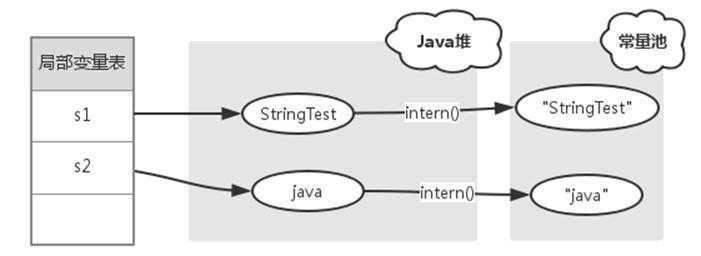
对于变量s1,常量池中没有 "StringTest" 字符串,s1.intern() 和 s1都是指向Java对象上的String对象。
对于变量s2,常量池中一开始就已经存在 "java" 字符串,所以 s2.intern() 返回常量池中 "java" 字符串的引用。
Attila Szegedis 在他讲述 JVM 知识的文档中一直强调,清楚知道内存中存储的数据量是非常重要的。我一开始感到十分惊讶,因为一般情况下,在企业开发中并不是经常需要关注对象的大小。他对此给出了 Twitter 的一个例子。
先思考一个内存占用的问题:字符串 "Hello World" 会占用多少字节内存?
答案:在 32 位虚拟机上是 62 字节,在 64 位虚拟机上是 86 字节。
分别为 8/16 (字符串的对象头) + 11 * 2 (字符) + [8/16 (字符数组的对象头) + 4 (数组长度),加上字节对齐所需的填充,共为 16/24 字节] + 4 (偏移) + 4 (偏移长度) + 4 (哈希码) + 4/8 (指向字符数组的引用)【在 64 位虚拟机上,String 对象的内存占用会因为字节对齐而填充为 40 字节】
intern 的目的在于复用字符串对象以节省内存。
在明确知道一个字符串会出现多次时才使用 intern(),并且只用它来节省内存。
最好的方法是对整个堆执行一次堆转储。堆转储也会在发生 OutOfMemoryError 时执行。
在 MAT (内存分析工具,译者注)中打开转储文件,然后选择 java.lang.String,依次点击"Java Basics"、"Group By Value"。
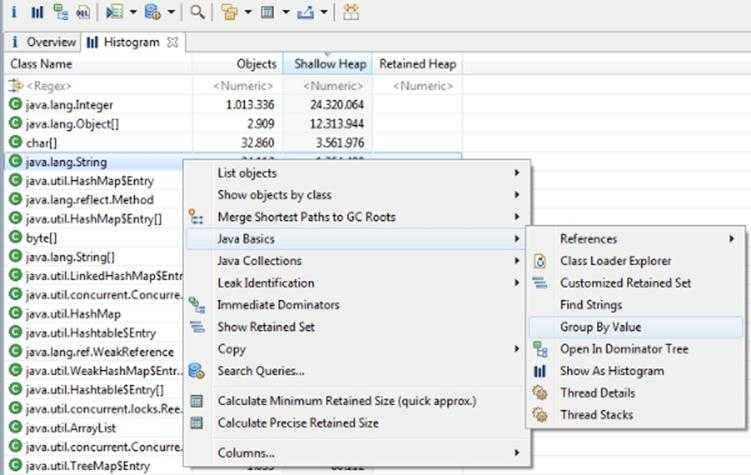
根据堆的大小,上面的操作可能耗费比较长的时间。最后可以看到类型这样的结果。按 "Retained Heap" 或者是 "Objects" 列进行排序,可以发现一些有趣的东西:
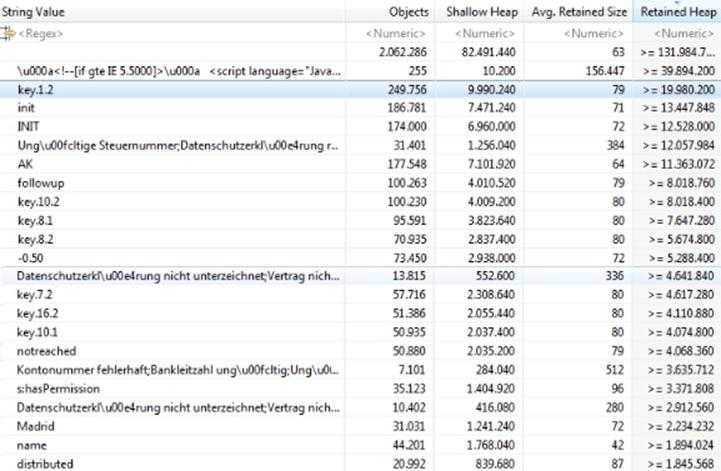
从这快照中我们可以看到,空的字符串占用了大量的内存!两百万个空字符串对象占用了总共 130 MB 的空间。另外可以看到一部分被加载的 JavaScript 脚本,一些作为键的字符串,它们被用于定位。另外,还有一些与业务逻辑相关的字符串。
这些与业务逻辑相关的字符串是最容易进行 intern 操作的,因为我们清楚地知道它们是在什么地方被加载进内存的。对于其他字符串,可以通过 "Merge shortest Path to GC Root" 选项来找到它们被存储的位置,这个信息也许能够帮助我们找到该使用 intern 的地方。
intern 的利弊
既然 intern() 方法有这些好处,为什么不经常使用呢?原因在于它会降低代码效率。下面给出一个例子:
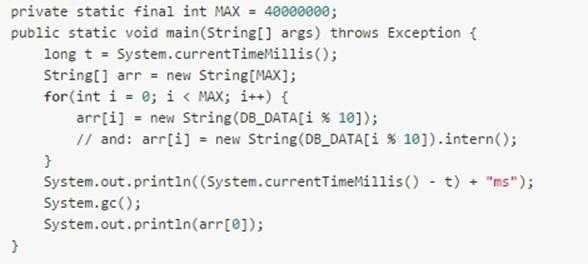
代码中使用了字符串数组来维护到字符串对象的强引用,另外我们还打印了数组的第一个元素来避免数组由于代码优化而将数组给销毁了。接着从数据库加载 10 个不同的字符串,但在这里我使用了 new String() 来创建一个临时的字符串,这和从数据库里读是一样的。最后我们调用了系统的 GC() 方法,这样就能排除其他不相关对象的影响,保证结果的正确。 在 64 位,8 G 内存,i5-2520M 处理器的 Windows 系统上运行上面的代码, 环境为 JDK 1.6.0_27,指定虚拟机参数 -XX:+PrintGCDetails -Xmx6G -Xmn3G 记录垃圾回收日志。结果如下:
没有使用 intern() 方法的结果:
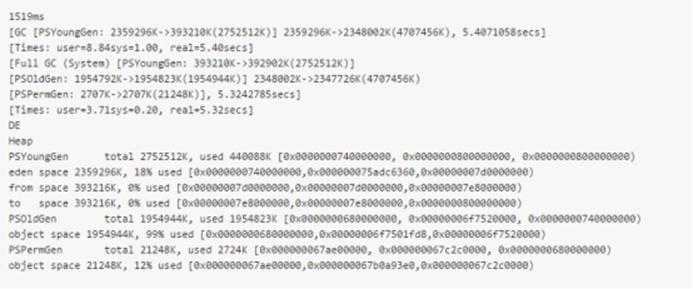 使用了 intern() 方法的结果:
使用了 intern() 方法的结果:
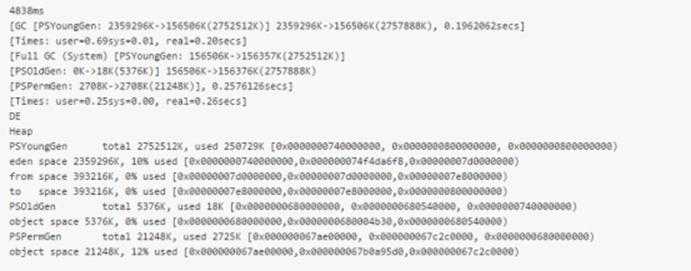 可以看到结果差别十分的大。在使用 intern() 方法的时候,程序耗时多了 3 秒,但节省了很大一块内存。使用 intern() 方法的程序占用了 253472K(250M) 内存,而不使用的占用了 2397635K (2.4G)。从这些可以看出使用 intern 的利弊。
可以看到结果差别十分的大。在使用 intern() 方法的时候,程序耗时多了 3 秒,但节省了很大一块内存。使用 intern() 方法的程序占用了 253472K(250M) 内存,而不使用的占用了 2397635K (2.4G)。从这些可以看出使用 intern 的利弊。
String.intern() in Java 6
在JAVA6中字符串池最大的问题是他的位置-永久代.永久代具有固定尺寸并且在运行时不能被扩展.它能使用参数 -XX:MaxPermSize=96m。 据我所知, 永久代默认的大小位于32M至96M间依赖平台.你能增大尺寸.但是字符串池的尺寸依然是固定的.这个限制需要我我们小心的使用String.intern-你最好对不能控制的字符不要使用intern这方法. 这是为什么在JAVA6中大部分使用手动管理map来实现字符串池
String.intern() in Java 7
Oracle 工程师在java7中对字符串池作了一个极其重要的决定-把字符串池移动到堆中.意
字符串池是使用一个拥有固定容量的hashmap, 默认的池大小是1009.(出现在上面提及的bug 报告的源码中).是一个常量在JAVA6早期版本中,随后在java6_30至java6_41中开始为可配置的.而在java 7中一开始就是可以配置的(至少在java7_02中是可以配置的).你需要指定参数 -XX:StringTableSize=N, N是字符串池map的大小. 确宝他是一个为更好的性能预先准备的数字.(不要使用1,000,000 作为-XX:StringTaleSize 的值 - 它不是质数;使用1,000,003代替)
String.intern() in Java 8
java8依然接受 -XX:StringTableSize. 提供可以与JAVA7媲美的性能. 唯一不同的是默认的池大小增加到25-50K
使用-XX:StringTableSize 参数在JAVA7和8中设置字符串池的大小.它是固定的.因为他的实现是一个由桶带链表组成的hashmap.靠近这个数并且设置池的大小等于靠近这个数的质数.他会使String.intern运行在一个常量时间里并且只需要消耗相当小的内存(同样的任务,使用java WeakHashMap将消耗4-5倍的内存)
intern 原理
intern() 方法需要传入一个字符串对象(已存在于堆上),然后检查 StringTable 里是不是已经有一个相同的拷贝。StringTable 可以看作是一个 HashSet,它将字符串分配在永久代上。StringTable 存在的唯一目的就是维护所有存活的字符串的一个对象。如果在 StringTable 里找到了能够找到所传入的字符串对象,那就直接返回它,否则,把它加入 StringTable :

标签:virtual 日志 bsp black 打开 特殊情况 print jdk7 工程
原文地址:http://www.cnblogs.com/jiumao/p/7136609.html