标签:sdfs xxxxx 输出 url should 路径 oca 内容 nbsp
import flask from flask import request,jsonify server = flask.Flask(__name__) #把当前文件当作一个服务 server.config[‘JSON_AS_ASCII‘] = False #不以ASCII码传 @server.route(‘/reg‘,methods=[‘post‘,‘get‘]) #接口方法前的修饰 methods有两个值:post和get jsonify({"msg":"ok"}) #接口返回值时用到,将字典转化json串,json串为字符串 request模块获取普通元素值,json值,cooies值,session,header,文件 req=request.values.get(‘username‘) #获取值 req=request.json #获取json值 token = request.cookies.get(‘token‘) #获取cookie值 req = request.session.get(‘session‘) #获取session值 req = request.headers.get(‘header‘)#获取header值 f = request.files.get(‘file_name‘,None) #获取file server.run(debug=True) #运行接口,port默认是5000,也可以自己指定,debug模式修改接口后会自动重启 server.run(port=8989,host=‘0.0.0.0‘) #host写成0.0.0.0的话,其他人都可以访问,代表监听多块网卡上面所有的ip
举例说明: (1)直接赋值, 传递对象的引用, 原始对象改变,被赋值的b也会做相同的改变 lis =[2,4,5,["A",1,2]] b = lis print(b) lis.append(6) print(b) print(lis) 结果: [2, 4, 5, [‘A‘, 1, 2]] [2, 4, 5, [‘A‘, 1, 2], 6] [2, 4, 5, [‘A‘, 1, 2], 6] (2)copy浅拷贝,没有拷贝子对象,所以原始对象中元素改变,拷贝后对象中元素不变,原始对象子对象元素改变,拷贝后子对象中元素也跟着改变 import copy lis =[2,4,5,["A",1,2]] b = copy.copy(lis) print("b的初始值",b) lis.append(6) print("lis添加元素后的值:",lis) print("lis添加元素后b的值:",b) lis[3].append(‘sss‘) print("lis元素添加子元素后的值:",lis) print("lis元素添加子元素后b的值:",b) 结果: b的初始值 [2, 4, 5, [‘A‘, 1, 2]] lis添加元素后的值: [2, 4, 5, [‘A‘, 1, 2], 6] lis添加元素后b的值: [2, 4, 5, [‘A‘, 1, 2]] #lis添加元素,b的值未变 lis元素添加子元素后的值: [2, 4, 5, [‘A‘, 1, 2, ‘sss‘], 6] lis元素添加子元素后b的值: [2, 4, 5, [‘A‘, 1, 2, ‘sss‘]]#lis中元素添加子元素后,b中的值也变了 (3)深拷贝,拷贝对象所有元素,原始对象的改变不会造成深拷贝里任何子元素的改变 import copy lis =[2,4,5,["A",1,2]] b = copy.deepcopy(lis) print("b的初始值",b) lis.append(6) print("lis添加元素后的值:",lis) print("lisi添加元素后b的值:",b) lis[3].append(‘sss‘) print("lis元素添加子元素后的值:",lis) print("lis元素添加子元素后b的值:",b) 结果: b的初始值 [2, 4, 5, [‘A‘, 1, 2]] lis添加元素后的值: [2, 4, 5, [‘A‘, 1, 2], 6] lisi添加元素后b的值: [2, 4, 5, [‘A‘, 1, 2]] lis元素添加子元素后的值: [2, 4, 5, [‘A‘, 1, 2, ‘sss‘], 6] lis元素添加子元素后b的值: [2, 4, 5, [‘A‘, 1, 2]]
import xlrd book = xlrd.open_workbook(r‘students.xlsx‘) # #也可以写绝对路径,读excel的时候,xls,xlsx都可以 print(book.sheet_names()) #获取所有sheet页的名字 sheet = book.sheet_by_index(0) #根据sheet页的位置去取sheet sheet2 = book.sheet_by_name(‘Sheet2‘) #根据sheet页的名字获取sheet页 print(sheet.nrows)#获取sheet页里面的所有行数 print(sheet.ncols)#获取sheet页里面的所有列数 print(sheet.row_values(0))#根据行号获取整行的数据 print(sheet.col_values(0))#根据列获取整列的数据 print(sheet.cell(1,1))#获取第2行第2列的数 #cell 方法是获取指定单元格数据,前面是行,后面是列 #结果:text:‘小明‘ print(sheet.cell(1,1).value) #结果:小明
代码如下:
import xlrd book = xlrd.open_workbook(r‘students.xlsx‘) sheet = book.sheet_by_index(0) lis=[] for i in range(1,sheet.nrows): #i代表的是每一行,因为第一行是表头,所以直接从第二行开始循环 dic ={} id = sheet.cell(i,0).value#行是不固定的,列是固定的 name = sheet.cell(i,1).value sex = sheet.cell(i,2).value dic[‘id‘]=id dic[‘name‘]=name dic[‘sex‘]=sex res.append(dic) print(res)
import xlwt book = xlwt.Workbook()#新建一个excel对象 sheet = book.add_sheet(‘stu‘)#添加一个sheet页 sheet.write(0,0,‘编号‘) #将内容写到excel book.save(‘stu.xls‘)#写excel的时候,你保存的文件名必须是xls
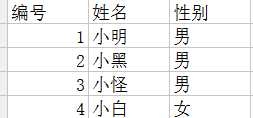
练习:将lis与title的内容写到Excel中
import xlwt lis = [{‘id‘: 1, ‘name‘: ‘小明‘, ‘sex‘: ‘男‘}, {‘id‘: 2, ‘name‘: ‘小黑‘, ‘sex‘: ‘男‘}, {‘id‘: 3, ‘name‘: ‘小怪‘, ‘sex‘: ‘男‘}, {‘id‘: 4, ‘name‘: ‘小白‘, ‘sex‘: ‘女‘}] title = [‘编号‘,‘姓名‘,‘性别‘] book = xlwt.Workbook()#新建一个excel对象 sheet = book.add_sheet(‘stu‘)#添加一个sheet页 for i in range(len(title)): #title多长,循环几次 sheet.write(0,i,title[i]) #i既是lis的下标,也代表每一列#处理表头 for row in range(len(lis)): id=lis[row][‘id‘] #因为lis里面存的是一个字典,lis[row]就代表字典里面的每一个元素,然后 #字典取固定的key就可以了 name=lis[row][‘name‘] sex=lis[row][‘sex‘] new_row =row+1#因为循环的时候 是从0开始循环的,第0行是表头,不能写 #要从第二行开始写,所以这里行数要加1 sheet.write(new_row,0,id) sheet.write(new_row,1,name) sheet.write(new_row,2,sex) book.save(‘stu.xls‘)
from xlutils.copy import copy import xlrd,xlwt book = xlrd.open_workbook(‘new_stu.xls‘) #打开原来的excel new_book = copy(book) #通过xlutils里面copy复制一个excel对旬 #print(dir(new_book)) 查看new_book下的方法 sheet = new_book.get_sheet(0) #获取sheet页 sheet.write(0,0,‘id‘)#写入修改的内容 new_book.save(‘new_stu_1.xls‘) #保存excel
AttributeError: 试图访问一个对象没有的属性,比如foo.x,但是foo没有属性x IOError:输入 / 输出异常,一般是无法打开文件 ImportError: 无法导入模块或包,一般是路径问题或名称错误 IndentationError:代码没有正确对齐,属于语法错误 IndexError:下标索引超出序列边界,比如x只有三个元素,却试图访问x[3] KeyError:试图访问字典里不存在的键 KeyboardInterrupt:Ctrl + C被按下 NameError:使用一个还未被赋予对象的变量 SyntaxError: 语法错误 TypeError: 传入对象类型与要求的不符 UnboundLocalError:试图访问一个还未被设置的局部变量,一般是由于在代码块外部还有另一个同名变量 ValueError: 传入一个调用者不期望的值,即使值的类型是正确的
(1)try...except..else...finally info = { "id":1, "name":"xiaobai", "sex":"nan", } choice =input(‘请输入你要查看的属性:‘) try: #print(info[choice]) print(info[choice]()) #也会报错 TypeError except Exception as e: #这个exception能捕捉到所有的异常 #Python3 #这个是出了异常的话,怎么处理,e代表异常信息 print("出错了,错误信息是:",e) else: #没有异常的话,走这里 print("没有出异常的话,走这里") finally: #不管有没有出异常都会走 #什么时候用:关闭文件,关闭数据库连接 print("这里是finally")
def is_correct_sql(sql): sql_start =[‘select‘,‘update‘,‘insert‘,‘delete‘] flag = 0 if sql.startswith(sql_start[0]) or sql.startswith(sql_start[1]) or sql.startswith(sql_start[2]) or sql.startswith(sql_start[3]): return True else: raise TypeError #主动抛出异常 s = OpertionMysql(sql="xxxxxx") print(s)
(1)urlopen(url)发送get请求 from urllib.request import urlopen import json url= ‘//127.0.0.1:8888/json‘ data = {‘user_id‘:1} req = request.urlopen(balance_url + ‘?‘ + new_balance_data) # 发送get请求 print(req.read().decode()) # 获取接口返回的结果,返回的结果是bytes类型的,需要使用decode方法解码,变成一个字符串 (2)urlopen()发送post请求 from urllib.request import urlopen from urllib.parse import urlencode import json url2 = ‘http://127.0.0.1:8888/reg‘ data = { "username":"haha", "password":"123456", "c_passwd":"123456" } print(urlencode(data))#把参数拼接成xxx=xxx&xxx=xxx #结果:password=123456&username=haha&c_passwd=123456 param = urlencode(data).encode() #转成二进制 # 发送post请求,传入参数的话,参数必须是bytes类型,所以需要先encode一下,变成bytes类型 print(urlopen(url2,param).read().decode()) #print(urlopen(url2,urlencode(data)).read().decode()) #这种会报错 TypeError: POST data should be bytes or an iterable of bytes. It cannot be of type str (3)url编码 from urllib.parse importquote,unquote,quote_plus,unquote_plus url = ‘http://127.0.0.1:5000/reg:.,\\‘ url2 = "http%3A//127.0.0.1%3A5000/reg%3A.%2C%5C" quote把特殊写字符变成url编码,quote_plus转更复杂的字符 unquote就是把url编码转成字符串,unquote_plus转更复杂的url编码 print(quote(url)) print(unquote(url2)) print(unquote_plus(url2)) 2.requests模块 (1)调用get方法 import requests url = ‘http://127.0.0.1:5000/get_sites‘ url2 = ‘http://127.0.0.1:5000/json‘ data = {‘user_id‘: 1} res = requests.get(url).text # 发送get请求,并获取返回结果,text获取的结果是一个字符串 res = requests.get(url,data).json() # 发送get请求,并获取返回结果,json()方法获取的结果直接是一个字典 print(res) (2)调用post方法 import requests url_reg = ‘http://127.0.0.1:5000/reg?username=hha&password=123456&c_passwd=123456‘ #直接传拼接好的url res = requests.post(url_reg).json() print(type(res),res) (3)入参是json串 url_set = ‘http://127.0.0.1:5000/set_sites‘ d = { "name":"妞妞杂货铺", "url":"http://www.nnzhp.cn" } #通过 json=xx来传值 res = requests.post(url_set,json=d).json() print(res) (3)添加cookie import requests cookie_url = "http://127.0.0.1:5000/set_cookies" data = {‘userid‘:1,"money":9999} cookie = {‘token‘:"token12345"} res = requests.post(cookie_url,data=data,cookies={"token":"token1111"}).json()#使用cookies参数指定cookie print(res) #flask怎么获取cookie的值 request.cookies.get("cookie") (4)发送文件 import requests up_url = ‘http://127.0.0.1:5000/upload‘ file = {‘file_name‘:open(‘aaa.py‘)} res = requests.post(up_url,files=file).text #指定files参数,传文件,是一个文件对象 print(res)
标签:sdfs xxxxx 输出 url should 路径 oca 内容 nbsp
原文地址:http://www.cnblogs.com/hhfzj/p/7137021.html