标签:creat 关注 syn min streams 启动 recv 数据 .com
PipelineDB Version:0.9.7
PostgreSQL Version:9.5.3
PipelineDB的数据处理组件:
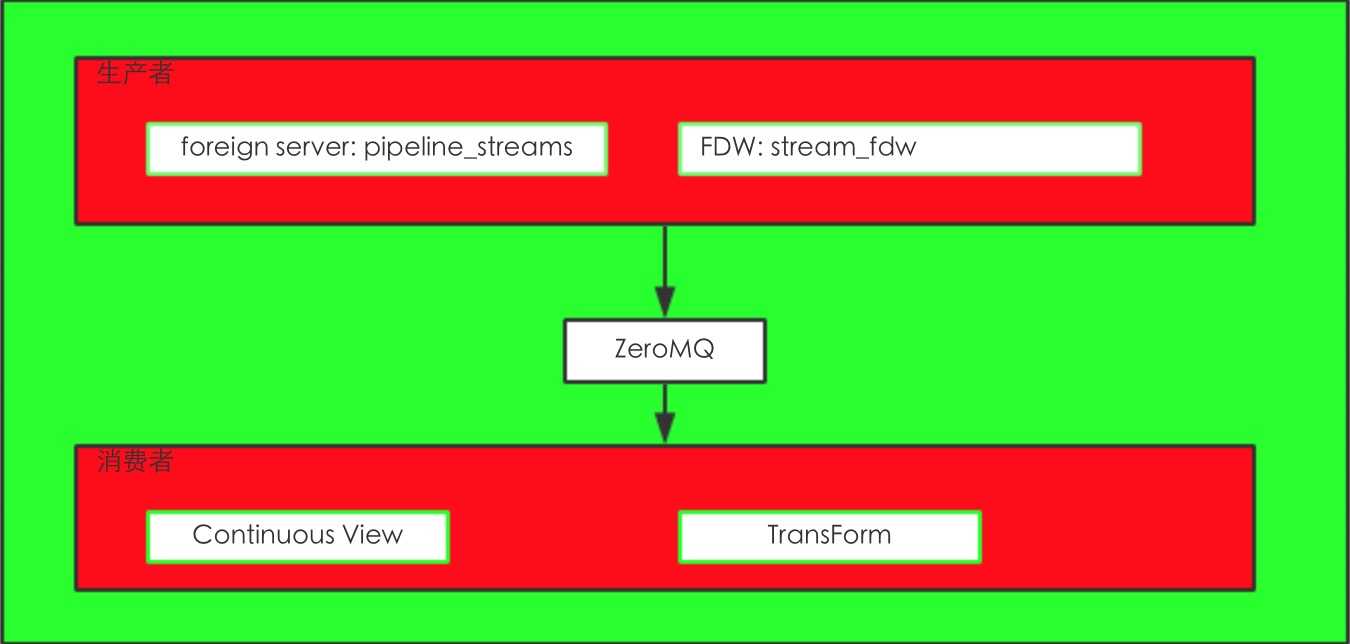
从上图来看主要就是pipeline_streams,stream_fdw,Continuous View,Transform。
其实就是运用了Postgres的FDW功能来实现的stream功能。
从数据库也能看到这个FDW
pipeline=# \des
List of foreign servers
Name | Owner | Foreign-data wrapper
------------------+-----------------+----------------------
pipeline_streams | unknown (OID=0) | stream_fdw
(1 row)
数据流转入下图
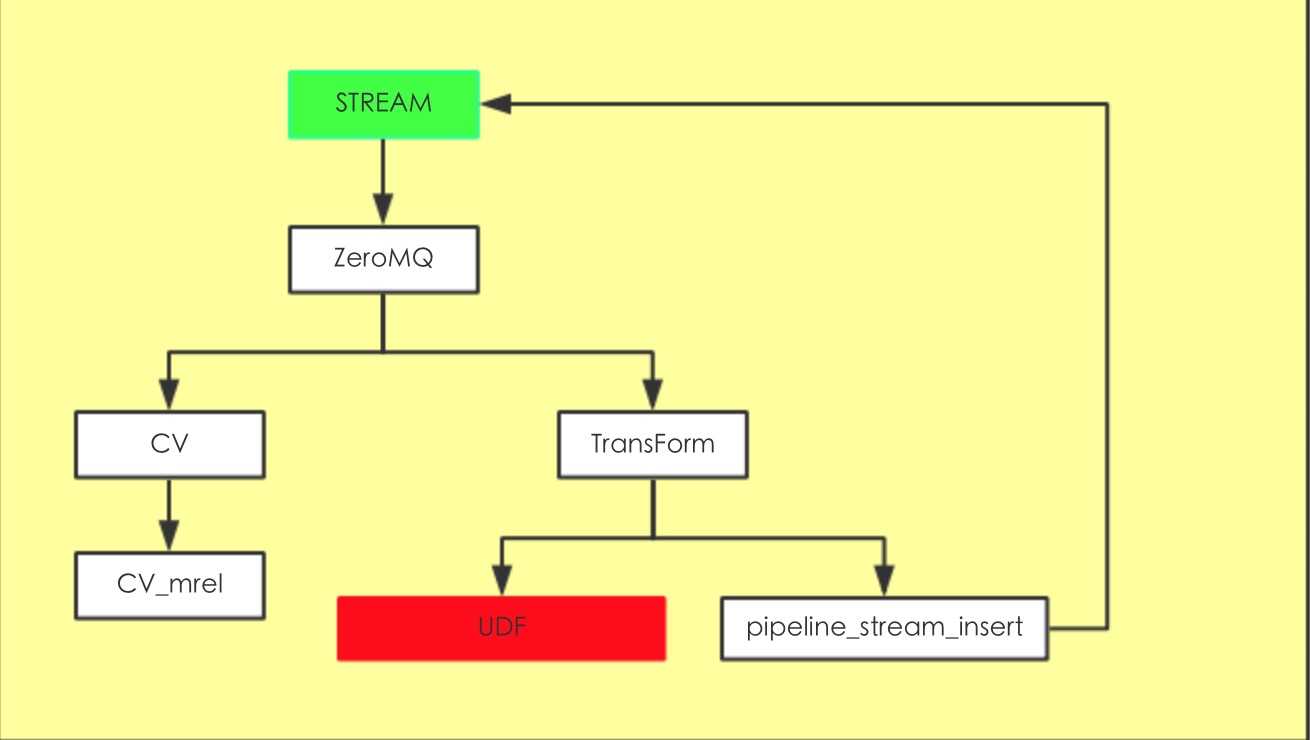
可以看到数据流转都是通过ZeroMQ来实现的(前面的版本0.8.2之前是通过TupleBuff来实现)
数据插入到Stream后然后调用ForiegnInsert,插入到初始化的IPC里面去,在数据库目录下面有个pipeline/zmq
TransForm其实就是把数据的dest指向了Stream,数据库默认有个pipeline_stream_insert其实这个是个Trigger,把tuple再扔到目标stream里面。
或者你可以自己写UDF,就是写个trigger,数据可以写到表或者别的FDW里面,或者是自己封装的消息队列IPC都没问题,这块自由发挥的空间就比较大。
首先我们来创建个STREAM跟CV
pipeline=# create stream my_stream(x bigint,y bigint,z bigint); CREATE STREAM pipeline=# create continuous view v_1 as select x,y,z from my_stream; CREATE CONTINUOUS VIEW pipeline=#
插入一条数据:
pipeline=# insert into my_stream(x,y,z) values(1,2,3); INSERT 0 1 pipeline=# select * from v_1; x | y | z ---+---+--- 1 | 2 | 3 (1 row) pipeline=#
数据插入到CV中了,我们现在来看看PipelineDB是如何插入的。
上面有介绍了Stream就是个FDW。我们来看看他的handler(source:src/backend/pipeline/stream_fdw.c)
/*
* stream_fdw_handler
*/
Datum
stream_fdw_handler(PG_FUNCTION_ARGS)
{
FdwRoutine *routine = makeNode(FdwRoutine);
/* Stream SELECTS (only used by continuous query procs) */
routine->GetForeignRelSize = GetStreamSize;
routine->GetForeignPaths = GetStreamPaths;
routine->GetForeignPlan = GetStreamScanPlan;
routine->BeginForeignScan = BeginStreamScan;
routine->IterateForeignScan = IterateStreamScan;
routine->ReScanForeignScan = ReScanStreamScan;
routine->EndForeignScan = EndStreamScan;
/* Streams INSERTs */
routine->PlanForeignModify = PlanStreamModify;
routine->BeginForeignModify = BeginStreamModify;
routine->ExecForeignInsert = ExecStreamInsert;
routine->EndForeignModify = EndStreamModify;
routine->ExplainForeignScan = NULL;
routine->ExplainForeignModify = NULL;
PG_RETURN_POINTER(routine);
}
主要是关注Streams Inserts这几个函数.
每个worker process启动的时候都会初始化一个recv_id,其实这个就是ZeroMQ的ID
数据会发送到对应的队列里面去,worker process就去这个IPC里面去获取数据
source:src/backend/pipeline/ipc/microbath.c
void
microbatch_send_to_worker(microbatch_t *mb, int worker_id)
{
......
worker_id = rand() % continuous_query_num_workers;
}
}
recv_id = db_meta->db_procs[worker_id].pzmq_id;
microbatch_send(mb, recv_id, async, db_meta);
microbatch_reset(mb);
}
首先是获取worker_id 这个是随机获取的一个worker进程。stream数据随机发到一worker process里面去了
recv_id这个就是从初始化的IPC队列获取ID,数据就发送到该队列里面
最后就调用
pzmq_send(recv_id, buf, len, true)
数据就推送到了IPC中了。
(gdb) p recv_id $12 = 1404688165 (gdb)
这部分就是数据生产者部分。
下面就是数据消费者CV
数据接受还是通过ZMQ的API来接受的
这个主要是worker process来干活的
srouce:src/backend/pipeline/ipc/pzmq.c&reader.c
(gdb) p *zmq_state->me
$8 = {id = 1404688165, type = 7 ‘\a‘, sock = 0x1139ba0, addr = "ipc:///home/pipeline/db_0.9.7/pipeline/zmq/1404688165.sock", ‘\000‘ <repeats 965 times>}
(gdb)
可以看到这个数据是从1404688165里面获取的 ,并且把IPC的addr也给出来了,这个就是我数据库目录
获取到是个buf,然后unpack,从消息里面获取到对应的Tuple.
获取到了tuple后,然后就找所有的CV跟这个stream相关的target。遍历他们,然后执行CV中对应的SQL。
执行流程跟标准SQL差不多也是初始化执行计划然后ExecutePlan然后endplan 。
数据会到Combiner里面,如果是AGG还会有一系列操作的。
如果数据符合CV的SQL逻辑,那么数据就插入到对应的物理表。
这就是Stream的一个简单的工作原理。
谢谢
浅谈PipelineDB系列一: Stream数据是如何写到Continuous View中的
标签:creat 关注 syn min streams 启动 recv 数据 .com
原文地址:http://www.cnblogs.com/sangli/p/7143413.html