标签:第三方库 png 为什么 mkdir bsp 命令 优化 文件的 安装
Day 2(上)
一、模块初识
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,以后的课程中会深入讲解常用到的各种库,现在,我们先来象征性的学2个简单的。标准库就是你使用python中最常用的,而第三方库就是必须下载安装后才可以使用的,例如Django。
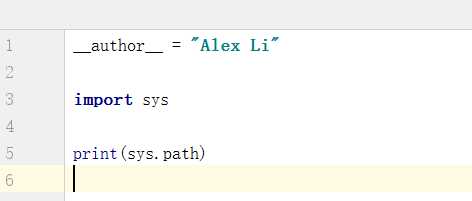
结果打印出一行行的路径,那这些路径是用来干什么的呢?这就是python调用一个库的路径,一般第三方库放在sie-packages中,而标准库放在lib下面:

再认识一下os模块
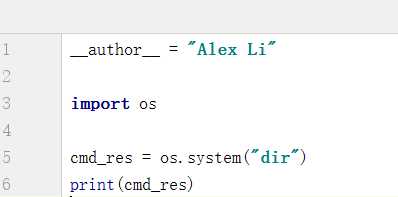
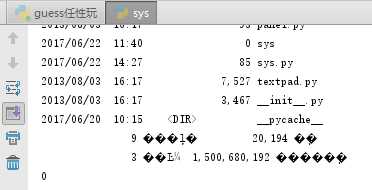
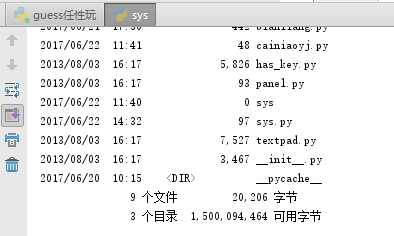
我们看一下输入的结果,为0,这是为什么呢?是因为dir这一行代码只执行命令不保存结果:
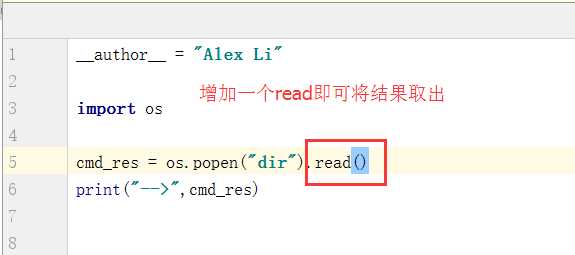
如果我吗需要读取结果,则将system改为popen,在后面加上一个.read()即可将结果取出,显示如下:
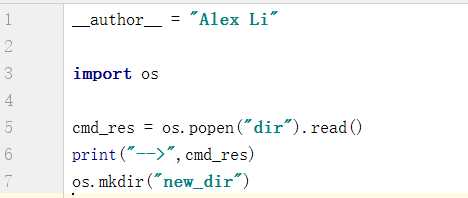
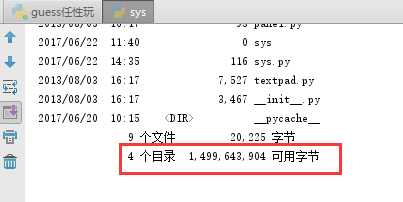
这时候我们想新建一个目录,应该如何操作呢?很简单,增加一行代码为os.mkdir("new_dir")后点击运行,原本的目录则由3个变为四个了:
认识了基本的模块后,我们来见识一下模块的神奇之处,首先先打开之前我们写好的passwd的程序,运行一下,输入用户名和密码之后,显示的是欢迎登陆...,如果我们在另一个py程序中直接调用这个passwd的模块,是否能够运行出相同的结果呢?答案是肯定的。
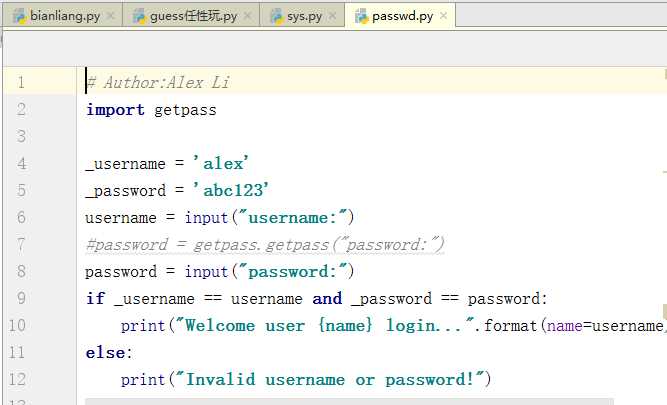
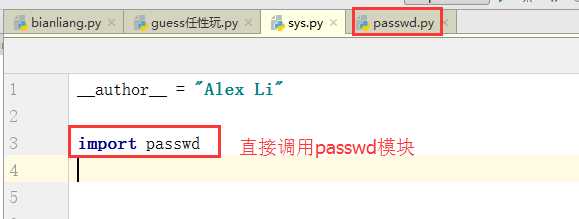
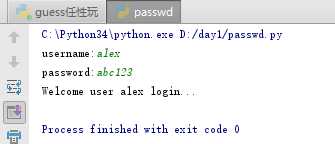
是不是很神奇?
二、.pyc是什么?
1. Python是一门解释型语言?
我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并且把一些基础概念给理清。
2. 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
3. Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
4. 简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
三、数据类型初识
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
int(整型)

基本操作:
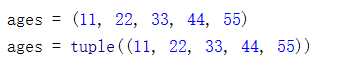
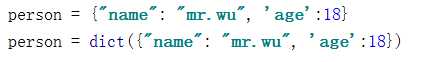
常用操作:
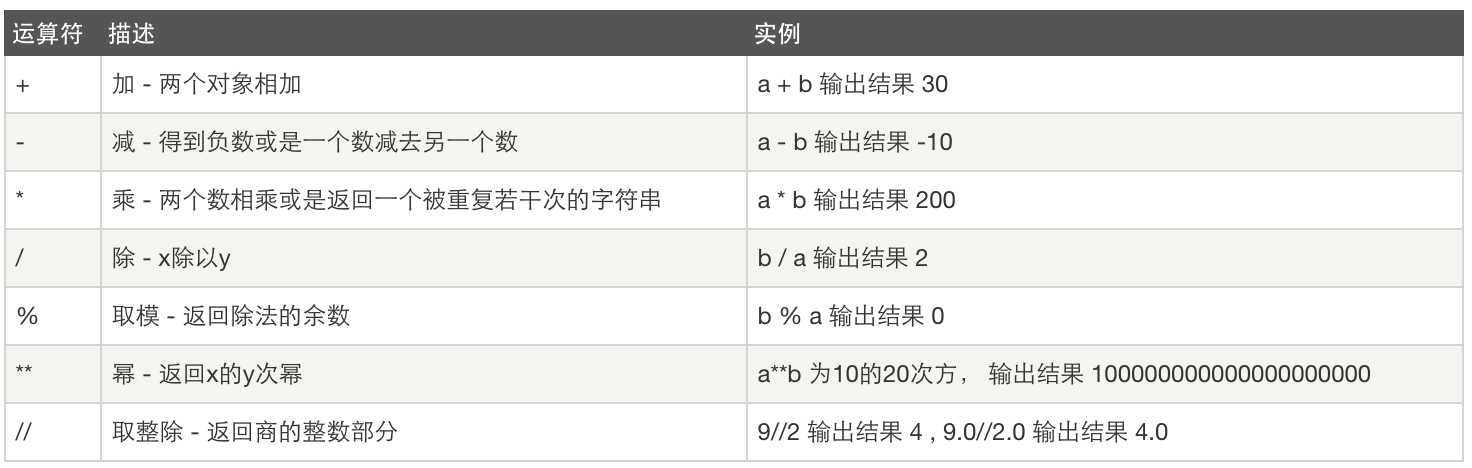
比较运算:

赋值运算:
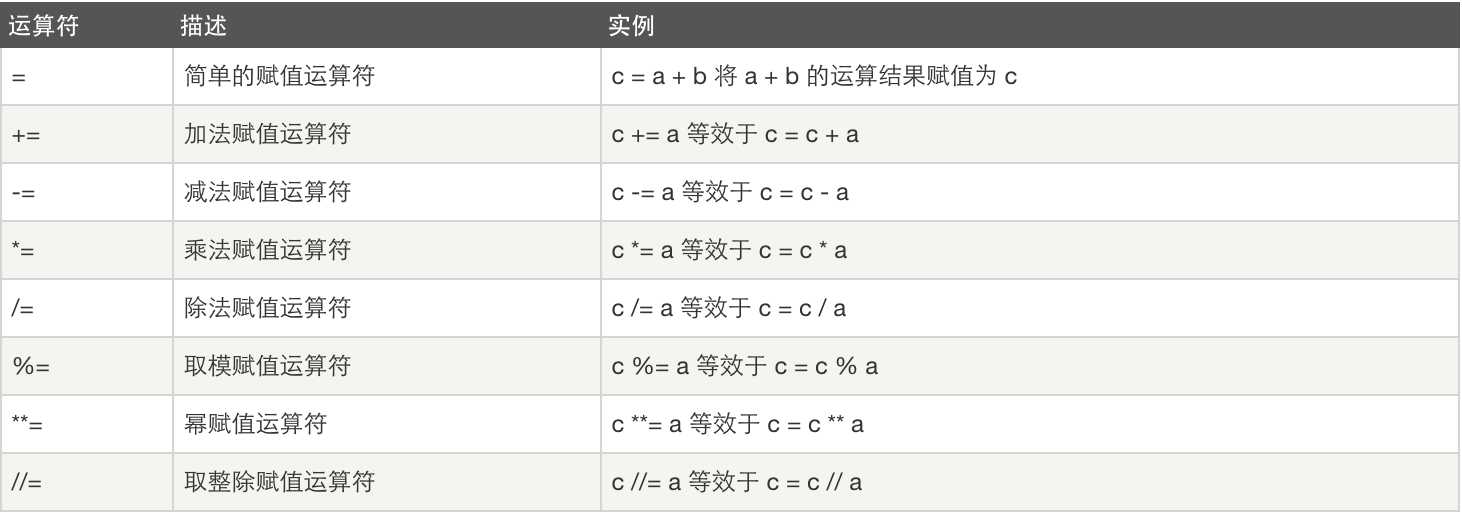
逻辑运算:

成员运算:

身份运算:

位运算:
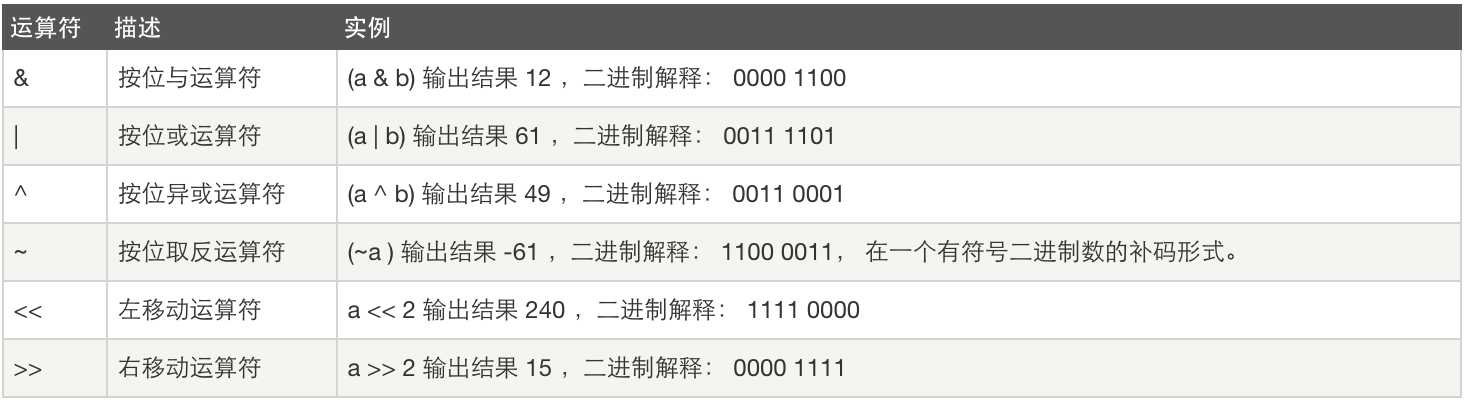
五、byte数据类型
1.bytes类型
2.三元运算
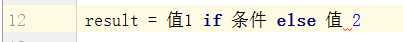
如果条件为真:result = 值1
如果条件为假:result = 值2
3.进制:
二进制转十六进制的方法:取4合1法即从二进制的小数点为分界点,向左(或者向右)每4位或1位表示一个16位。例如101110011011001转化为十六进制即为B9B9。
注意:十六进制的表示法:用字母H后缀表示,比如BH表示十六进制数11,也可以用0X前缀表示,比如0X23是十六进制的23。
这里需要提醒的是:在向左或者向右取4位,取到最高位如果无法凑足4位,就可以在小数点的最左边或者最右边补0,进行换算。
例如:10111.011换算成十六进制数则为176。
下面我们再看看十六进制转二进制,反过来的方法就是一分为四。
4.encode
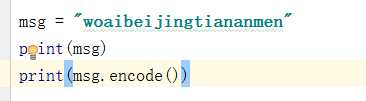
输出结果:
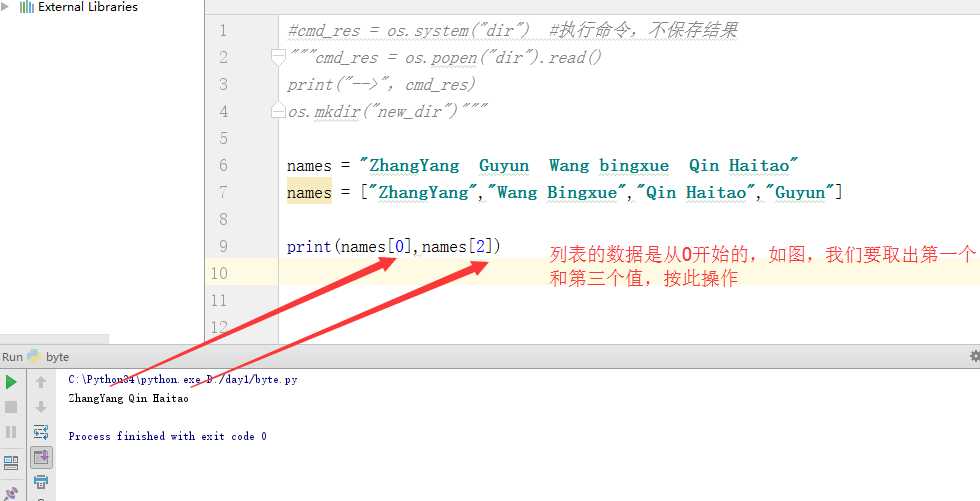
5.列表
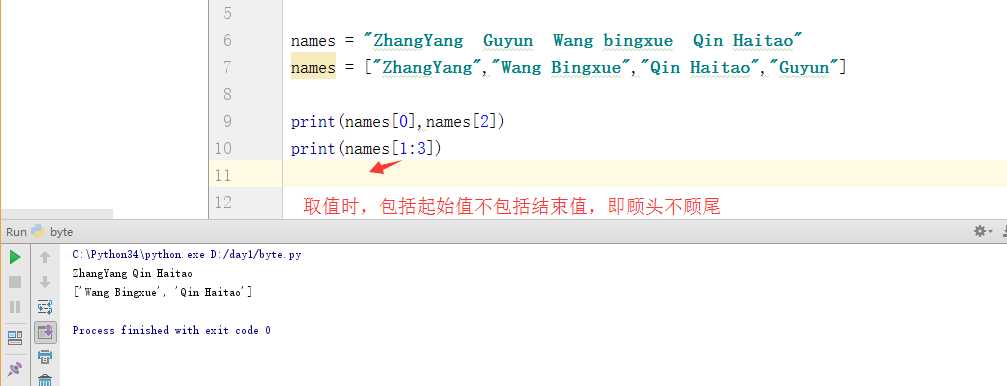
列表中的切片操作:
列表中取最后一个值的方法:
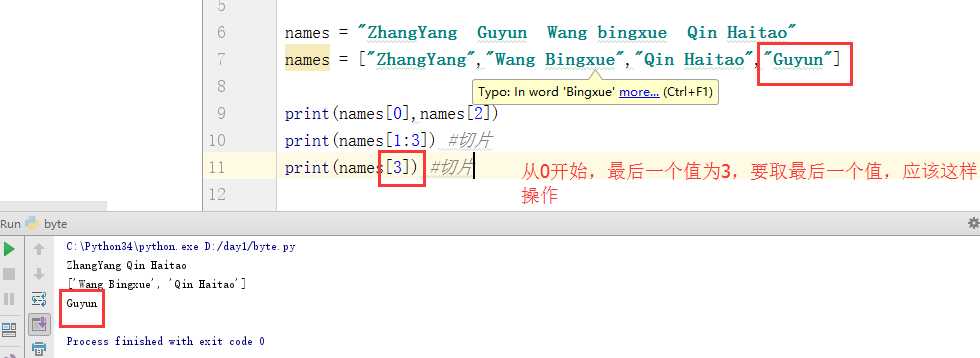
但如果我们不知道最后一个值是第几位应该如何取最后一个值呢(数据较多时),这里print(列表名[-1]):
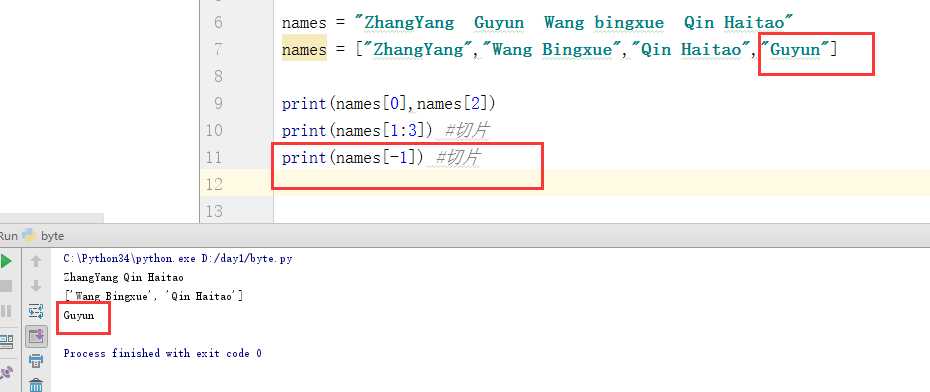
同理,[-2]为取列表中倒数第二个值,即从右往左数取第二个值:
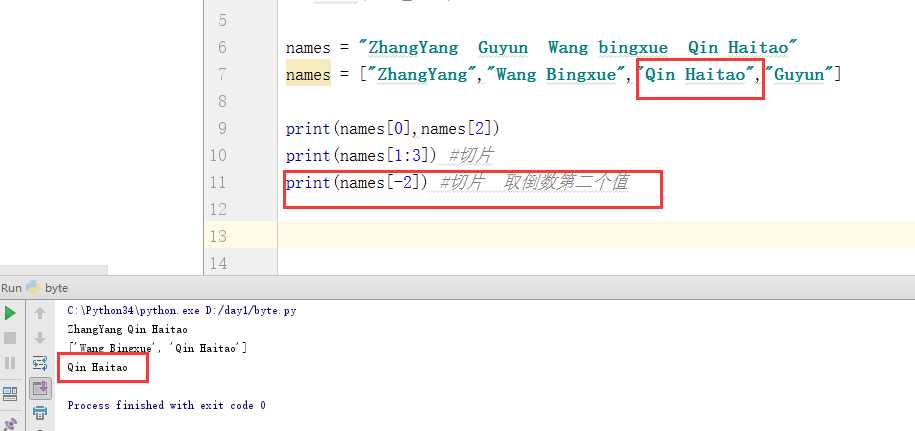
再更复杂一点,如果我取倒数1、2 两个值,应该如何操作呢?
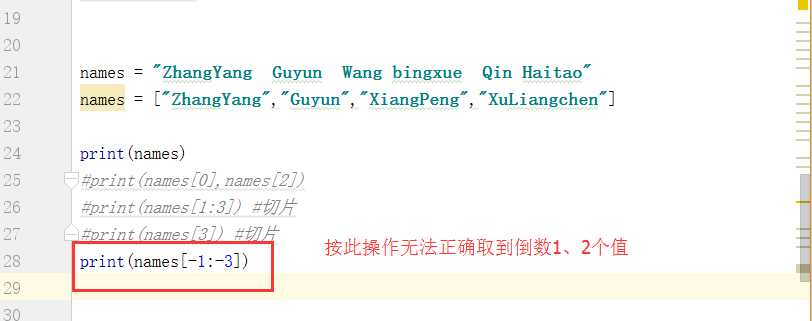
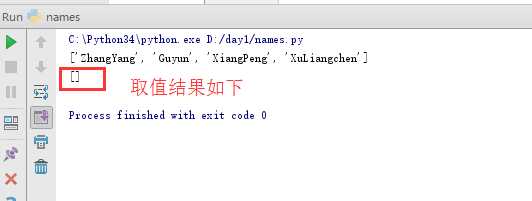
为什么按照此逻辑无法正确取到需要的值呢?我们来看一下:

但我们发现根据此操作取的值并非所需的倒数1、2个数字,而是倒数2、3个数,因为顾头不顾尾的原则导致的:
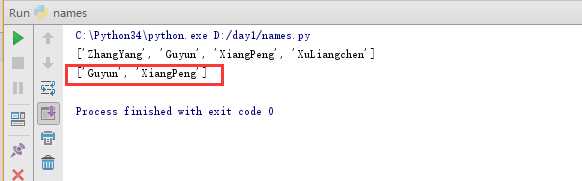
所以正确的取值方式应该为[-2:]:
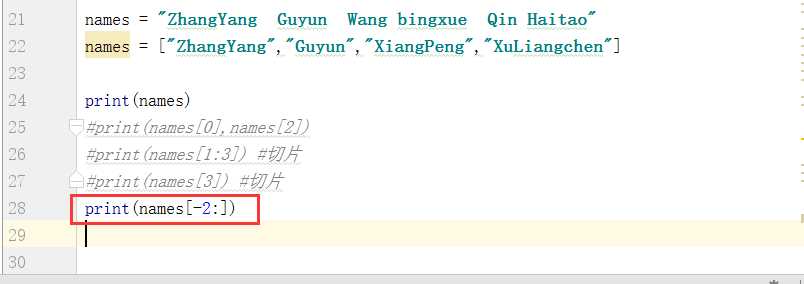
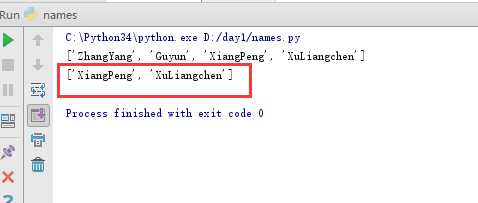
我们可以发现,切片过程中前后为0的时候是可以省略掉的,运行的结果是一样的。
那如果我想在列表中插入一个新的值,应该如何操作呢?有两种方法,这里先介绍直接追加法,使用的是.append:

运行结果如下,情况,LeiHaidong被成功追加至列表末尾了:
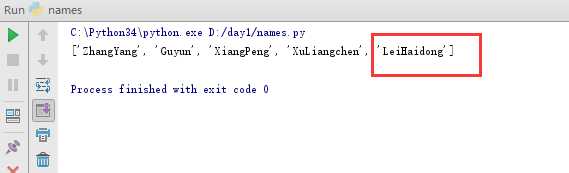
如果不想将新增的值放在列表最末尾而是随机放置在列表的某一位置可不可以呢,答案是肯定的,例如现在我们想将Chen Ronghua插入到Guyun前面:
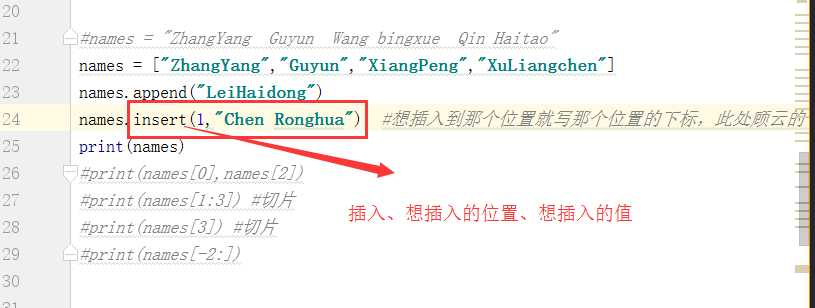
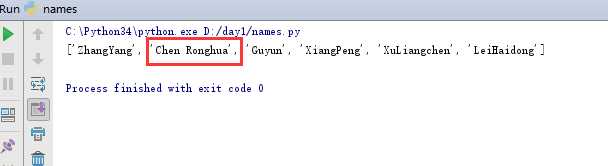
需要注意的是,插入操作只能一步一步来,不可批量插入。
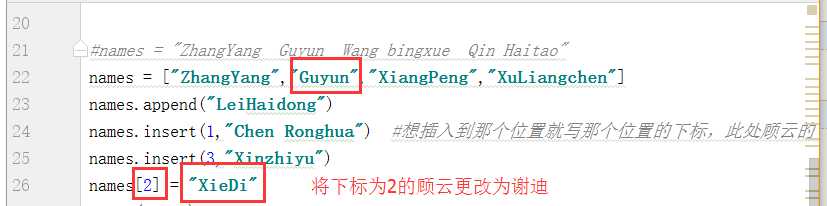
现在我们讲述的操作是替换,目前前面所讲的为“增”,现在来讲“改”,例如将顾云更改为其他的值:

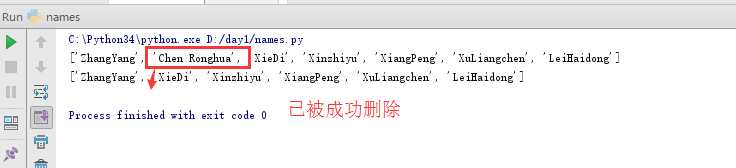
“增删查改”均为基本操作,下面来介绍如何删除操作一个值:



这三种方法均能成功删除指定的值,结果如下:
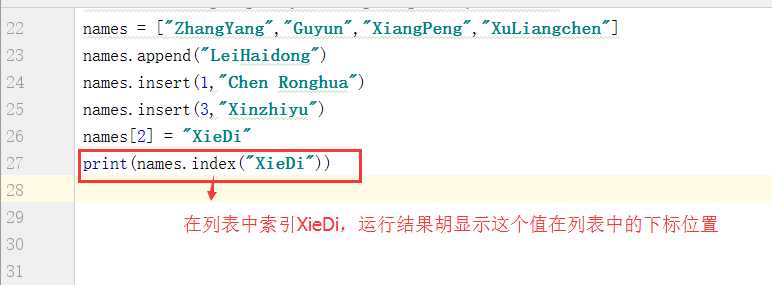
最后再讲讲如何“查”,假如整个列表有80多人,我想知道谢迪在哪个位置,应该如何查询?
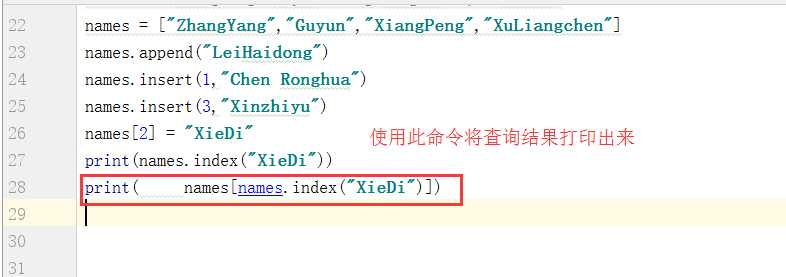
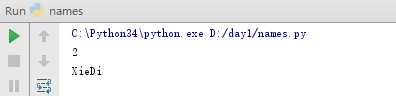
如果列表中有两个或者几个重复值,需要统计有多少个重复值,这里使用count,计算出重复值有2个:

剩下的reverse(反转列表)、sort(排序)、copy(复制)下节课详细讲解。
标签:第三方库 png 为什么 mkdir bsp 命令 优化 文件的 安装
原文地址:http://www.cnblogs.com/hait1234/p/7064162.html