标签:编码 研发 去除 上传 溢出 sof 文字 rem 长整型
1、int(整型)
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
x = 10
print(x, type(x))
#输出10 <class ‘int‘>
2、long(长整型)
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
x = 3.5
print(x, type(x))
#输出3.5 <class ‘float‘>
字符串是 Python 中最常用的数据类型。我们可以使用引号(‘或")来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
a = "hello word"
print(a, type(a))
print(a.strip()) #去除首和尾多余的空格
print(a.split("o"))
print(a[1:3])
print(a.isdigit())
print(a.count("l"))
print(len(a))
print(a.replace("hello","hi"))
#输出:
#hello word <class ‘str‘>
#hello word
#[‘hell‘, ‘ w‘, ‘rd‘]
#el
#False
#2
#10
#hi word
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
t = ("gangdan", "yanglei", "xiaofei", "yanglei")
print(t, type(t))
print(t.count("yanglei"))
print(t.index("gangdan"))
#输出:
#(‘gangdan‘, ‘yanglei‘, ‘xiaofei‘, ‘yanglei‘) <class ‘tuple‘>
#2
#0
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
dic = {
"name":"yanglei","age":23,"job":"IT"
}
print(dic, type(dic))
dic.pop("age")
print(dic)
dic.setdefault("age",23)
print(dic)
print(dic.get("job"))
print(dic.get("wu"))
print(dic.items())
print(dic.keys())
print(dic.values())
#输出:
#{‘name‘: ‘yanglei‘, ‘age‘: 23, ‘job‘: ‘IT‘} <class ‘dict‘>
#{‘name‘: ‘yanglei‘, ‘job‘: ‘IT‘}
#{‘name‘: ‘yanglei‘, ‘job‘: ‘IT‘, ‘age‘: 23}
#IT
#None
#dict_items([(‘name‘, ‘yanglei‘), (‘job‘, ‘IT‘), (‘age‘, 23)])
#dict_keys([‘name‘, ‘job‘, ‘age‘])
#dict_values([‘yanglei‘, ‘IT‘, 23])
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
lis = [11,22,33,44,55,66,77,88,99,90]
dic = {}
for i in lis:
if i > 66:
dic.setdefault("k1",[]).append(i)
elif i < 66:
dic.setdefault("k2", []).append(i)
print(dic)
#输出:
#{‘k2‘: [11, 22, 33, 44, 55], ‘k1‘: [77, 88, 99, 90]}
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
Python有6个序列的内置类型,但最常见的是列表和元组。
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
lis = ["yanglei","gangdan","yanglei","xiaolan","xiaolv"]
print(lis, type(lis))
print(lis[1])
print(lis[0:3])
lis.pop()
print(lis)
print(lis.index("gangdan"))
print(lis.count("yanglei"))
lis.append("xiaohong")
print(lis)
lis.insert(1,"xiaolv")
print(lis)
lis.remove("xiaolan")
print(lis)
#输出:
#[‘yanglei‘, ‘gangdan‘, ‘yanglei‘, ‘xiaolan‘, ‘xiaolv‘] <class ‘list‘>
#gangdan
#[‘yanglei‘, ‘gangdan‘, ‘yanglei‘]
#[‘yanglei‘, ‘gangdan‘, ‘yanglei‘, ‘xiaolan‘]
#1
#2
#[‘yanglei‘, ‘gangdan‘, ‘yanglei‘, ‘xiaolan‘, ‘xiaohong‘]
#[‘yanglei‘, ‘xiaolv‘, ‘gangdan‘, ‘yanglei‘, ‘xiaolan‘, ‘xiaohong‘]
#[‘yanglei‘, ‘xiaolv‘, ‘gangdan‘, ‘yanglei‘, ‘xiaohong‘]
在Python set是基本数据类型的一种集合类型,它有可变集合(set())和不可变集合(frozenset)两种。创建集合set、集合set添加、集合删除、交集、并集、差集的操作都是非常实用的方法。
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
s1 = {22,33,55,66,88}
s2 = {33,77,99,66}
#交集
print(s1 & s2)
#并集
print(s1 | s2)
#差集
print(s1 - s2)
print(s2 - s1)
#对称差集
print(s1 ^ s2)
#输出:
#{33, 66}
#{33, 66, 99, 77, 22, 55, 88}
#{88, 22, 55}
#{99, 77}
#{99, 22, 55, 88, 77}
Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串。
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
s = "hello gangdan gangdan say hello sb sb"
dic = {}
for i in s.split():
if i not in dic:
dic[i] = 1
else:
dic[i] += 1
print(dic)
#输出:
#{‘hello‘: 2, ‘gangdan‘: 2, ‘say‘: 1, ‘sb‘: 2}
二进制实际上就是用10进制的数的每一位数字的2的幂数
来看例子:
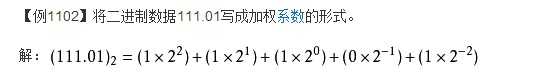
然后再Python的操作中,只要在数字前面加上0b的字符,就可以用二进制来表示十进制数了。
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
print(0b1)
print(0b10)
print(0b11)
print(0b100)
print(0b101)
print(0b110)
print(0b111)
#输出:
#1
#2
#3
#4
#5
#6
#7
python3解释器在加载 .py 文件中的代码时,会对内容进行编码(默认unicode)。
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536, 注:此处说的的是最少2个字节,可能更多,UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
--------------------------------------------------------------------------------------------------------------------------------------------------------------
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
#!/usr/bin/env pyhon
#auth: yanglei
print("中国")
#输出:
#中国
编码与转码
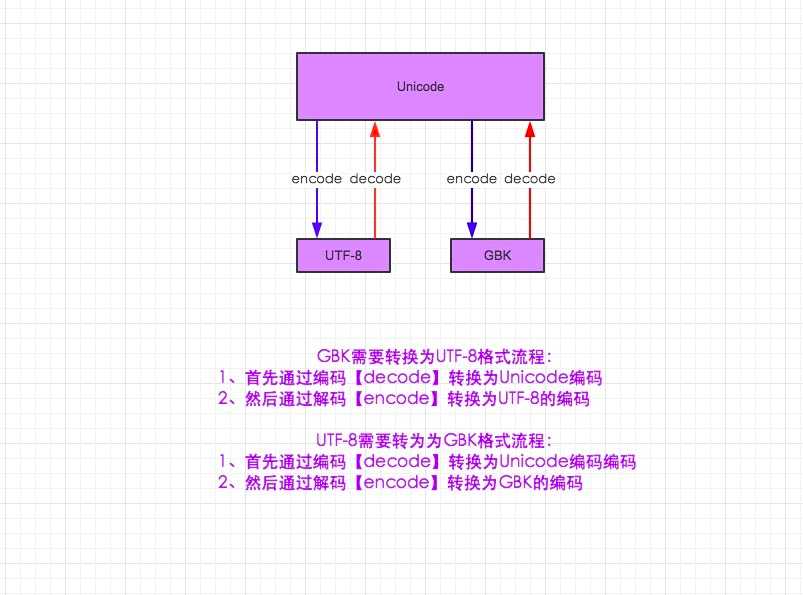
对文件操作流程
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
f_file = open("lock","r",encoding="utf-8")
for i in f_file.read()
print(i)
f_file.close()
打开文件的模式有:
"+" 表示可以同时读写某个文件
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
#!/usr/bin/env pyhon
#encoding: utf-8
#auth: yanglei
import os
with open("old.txt","r",encoding="utf-8") as f_read, open(".old.txt.swap","w",encoding="utf-8") as f_write:
res = f_read.read()
res = res.replace("xiaolan","yanglei")
f_write.write(res)
os.remove("old.txt")
os.rename(".old.txt.swap","old.txt")
标签:编码 研发 去除 上传 溢出 sof 文字 rem 长整型
原文地址:http://www.cnblogs.com/00doudou00/p/7147450.html