标签:any god shel 子节点 ble .sh slist 小问题 ash
第一部分
在搭建mongoDB之前,我们要考虑几个小问题:
1、我们搭建集群的目的是什么?是多备份提高容错和系统可用性还是横向拓展存储大规模数据还是两者兼有?
如果是为了多备份那么选择replication集群搭建即可,如果是为了处理大数据则需要搭建sharding集群,如果两者兼有需要对每个shardsvr创建replica。
2、什么是sharding?和replication有什么不同?
简单而言,replica是mongo提供服务的一个基本单位,单机系统和replication集群对用户来讲没有区别,都只相当于一个服务节点,只不过replication集群有多备份,还有服务端选举,安全性更加有保证。而sharding集群包含3个角色:mongos,configsvr,shardsvr,对于一个集群来说mongos相当于master,负责对外提供服务,shardsvr相当于slave,负责分片存储数据,而configsvr相当于router,负责记录分片元信息。这3种角色中的任何一个角色中的子节点都是一个replica。具体说明参考官方网站对sharding和replication的描述:
replication:https://docs.mongodb.com/manual/replication/
sharding:https://docs.mongodb.com/manual/sharding/
3、我们集群的架构又该是什么样子?
如果对问题1和2有足够的认知的话,那么根据本地硬件环境构建一个什么样的集群大致也就清楚了,每个shardsvr的replication相当于一个slave,我们需要几个子节点就需要创建多少个shardsvr,configsvr是router信息,我们可以将所有机器都组成一个configsvr的replication用以提供router服务,至于mongos,内部使用一个节点也可以,如果需要稳定运行的话也需要组一个小的mongos的replication。
第二部分
下面是实战环节:
我这可以有5台服务器用来跑mongodb还有一批数据,当然,这5台机器上也跑着其他框架如spark,hadoop等等,由于spark和hadoop都是单点故障的(什么?多master?secondary?不存在的,老夫部署集群从来都是单点故障)所以mongos也是一台节点,数据端存放在5台机器上,又由于数据量较大,硬盘较小(别人组的raid5,加一起一台服务器也就1T多空间),所以肯定不考虑备份和稳定性了(2备份硬盘就没多大地方了,hdfs还有其他数据要放),那么架构可以构建如下:
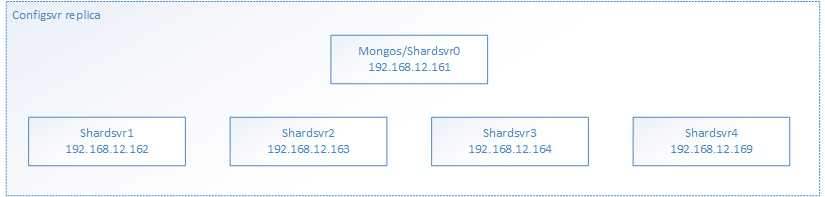
下面shardsvr每一个都是一个单独的replica,开始部署:
1、创建配置文件:
a) configsvr
systemLog: destination: file path: "/home/cloud/platform/logs/mongodb/configsvr.log" logAppend: true storage: dbPath: "/home/cloud/platform/data/configData" journal: enabled: true setParameter: enableLocalhostAuthBypass: false processManagement: fork: true replication: replSetName: "configsvr0" sharding: clusterRole: "configsvr"
b) shardsvr
systemLog: destination: file path: "/home/cloud/platform/logs/mongodb/shardsvr.log" logAppend: true storage: dbPath: "/home/cloud/platform/data/shardData" journal: enabled: true setParameter: enableLocalhostAuthBypass: false processManagement: fork: true replication: replSetName: "shardsvr1" sharding: clusterRole: "shardsvr"
c) mongos
systemLog: destination: file path: "/home/cloud/platform/logs/mongodb/mongos.log" logAppend: true net: bindIp: 192.168.12.161 port: 27017 setParameter: enableLocalhostAuthBypass: false processManagement: fork: true sharding: configDB: "configsvr0/192.168.12.161:27019,192.168.12.162:27019,192.168.12.163:27019,192.168.12.164:27019,192.168.12.169:27019"
注意:每台机器上的配置都略有不同,简易参考官方文档进行修改,replSetName这个是replication的设置,每个角色的子replication应该有相同的值,不同的replication应该有不同的值
接下来是启动脚本
a)shardsvr
#!/bin/bash # use this to initiate: rs.initiate({_id:"shardsvr1",members:[{_id:0,host:"192.168.12.161:27018"}]}) /home/cloud/platform/mongodb-3.4.5/bin/mongod --config /home/cloud/platform/mongodb-3.4.5/shardserver.conf
b)configsvr
#!/bin/bash #use this to initiate: rs.initiate({_id:"configsvr0",configsvr:true,members:[{_id:0,host:"192.168.12.161:27019"},{_id:1,host:"192.168.12.162:27019"},{_id:2,host:"192.168.12.163:27019"},{_id:3,host:"192.168.12.164:27019"},{_id:4,host:"192.168.12.169:27019"}]}) MONGO_HOME=/home/cloud/platform/mongodb-3.4.5/ ${MONGO_HOME}/bin/mongod --config ${MONGO_HOME}/configserver.conf
c)mongos
#!/bin/bash #mogos dont need to initiate, #sh.enableSharding("dbname") to create database #sh.shardCollection("dbname.tablename", {id: "hashed"}) to create a shard table split by id /home/cloud/platform/mongodb-3.4.5/bin/mongos --config /home/cloud/platform/mongodb-3.4.5/mongosserver.conf
2、启动过程
a、将脚本和配置文件复制到每台机器上
b、启动每个shardsvr,然后登录到shardsvr上,执行初始化过程:
1、执行start-shardsvr.sh 2、执行bin/mongo --host ${hostIP} --port ${hostport} shardsvr的默认端口是27018 configsvr的默认端口是27019 mongos的默认端口是27017 在上面配置文件中未指定端口,一切都以默认为主 3、执行rs.initiate({_id:"shardsvr1",members:[{_id:0,host:"192.168.12.161:27018"}]}) 进行初始化工作 4、执行rs.status()查看shardsvr状态,一个成功的例子如下:
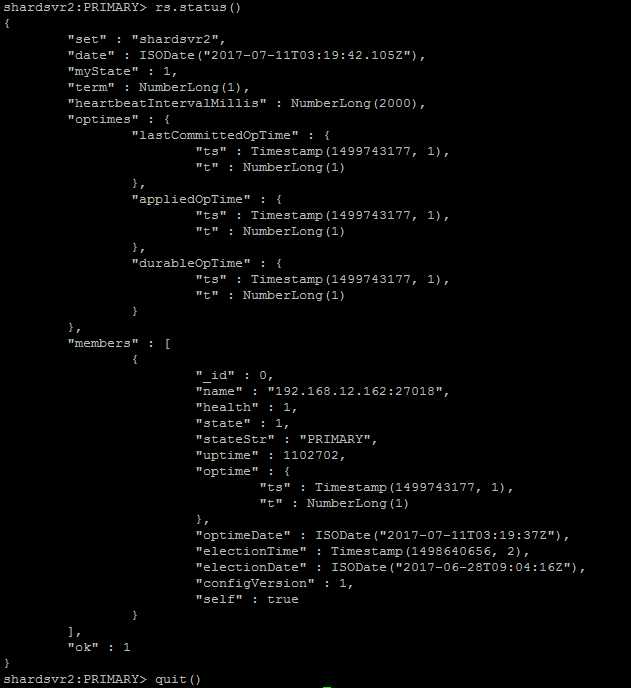
c、启动所有configsvr,并使用mongo --host --port命令登录到任意一台configsvr的configsvr端口上(default:27019)。并执行初始化工作:
rs.initiate({_id:"configsvr0",configsvr:true,members:[{_id:0,host:"192.168.12.161:27019"},{_id:1,host:"192.168.12.162:27019"},{_id:2,host:"192.168.12.163:27019"},{_id:3,host:"192.168.12.164:27019"},{_id:4,host:"192.168.12.169:27019"}]})
d、启动mongos,这时已经可以在mongos上执行我们的操作了。
printShardingStatus()
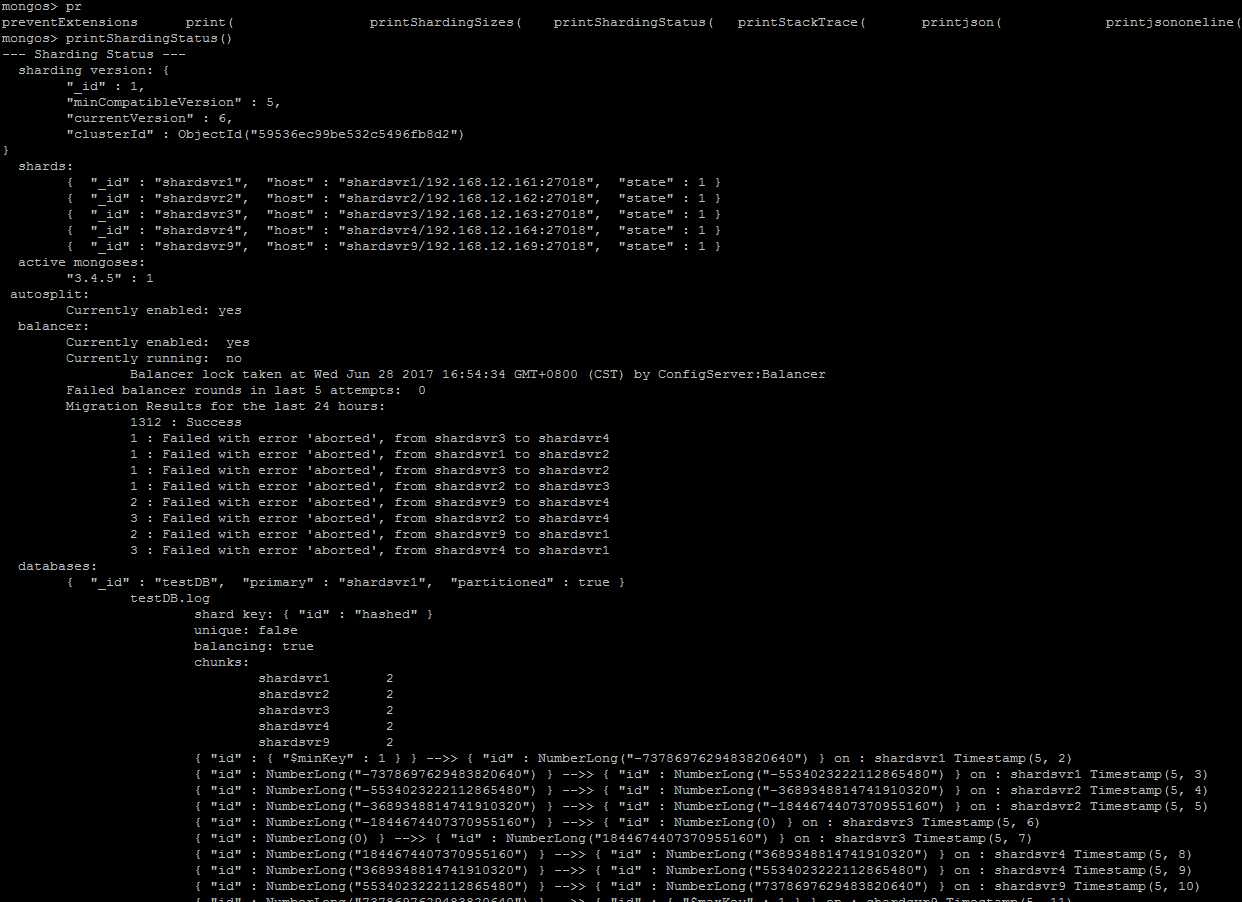
然后就是正常的mongo shell操作了,可以把mongos当成一个普通的单机mongodb来使用,操作基本相同,除了创建sharding表
创建表如下:
sh.enableSharding("dbname") to create database sh.shardCollection("dbname.tablename", {"_id": "hashed"}) to create a shard table hashed by _id
需要注意的是,"_id"是mongo分片依据,不能重复,如果想以其他字段来进行hash,将命令中的"_id"改为字段名称就可以了,但是mongo还是会自动创建一个_id列用来索引
添加索引:
db.collectionname.ensureIndex({"indexColumn":1})
第三部分
JavaAPI小tips
获取连接:
lazy val mongo = new MongoClient("192.168.12.161", 27017) lazy val db = mongo.getDatabase("testdb") lazy val dbColl = db.getCollection("origin2")
插入数据:
var resList = new ArrayList[Document] var d = new Document d.append("path", x.getPath) d.append("name", x.getName) d.append("content", filterHtml(Source.fromFile(x, detector(x)).getLines().toArray).mkString("\n")) resList.add(d) dbColl.insertMany(resList, new InsertManyOptions().ordered(false))
在插入过程中,如果"_id"出现重复值,那么默认情况下会中止当前插入操作并throw一个exception,即之前的数据已经插入进去,后面的数据没插入进表,在后面加入new InsertManyOptions().ordered(false)参数就可以将所有不重复的数据插入完成后再throw一个exception
mongoDB3.4的sharding集群搭建及JavaAPI的简易使用
标签:any god shel 子节点 ble .sh slist 小问题 ash
原文地址:http://www.cnblogs.com/gaoze/p/7149911.html