标签:src 示例 数据库 格式 使用 行数据 名称 脚本 开源
“根据访谈记录和专家估计,数据科学家将50%至80%的时间花在搜集和准备难以梳理的数字数据的琐碎工作中,然后才能开发这些数据完成有用的工作”
— Steve Lohr, Aug 17, 2014, New York Times (For Big-Data Scientists, ‘Janitor Work’ Is Key Hurdle to Insights)
BigGorilla是一个开源数据整合和数据准备生态系统(由Python提供支持),以允许数据科学家执行数据整合和分析。BigGorilla整合和记录数据科学家将不同来源的数据融合到一个数据库以进行数据分析时通常采取的不同步骤。
对于其中的每个步骤,我们记录现有的技术,并指出可以开发的所需技术。
BigGorilla的各个组件可供免费下载和使用。我们鼓励数据科学家为BigGorilla贡献代码、数据集和示例。我们的目标还在于推进教育和培训,以通过BigGorilla提供的开发、文档和工具启示数据科学家。使用我们的BigGorilla教程立即开始数据整合与数据准备。
下面的虚构情境阐释如何使用BigGorilla的不同组件(参见页面底部)。假设一家公司尝试了解其客户和潜在客户对于公司产品以及对于竞争对手产品的想法。其目标在于,从相关的推特、博客和新闻文章中获取和准备数据,
然后再对数据进行最喜好情感分析。下文描述了在执行情感分析算法之前为准备数据而采取的一种可能步骤。
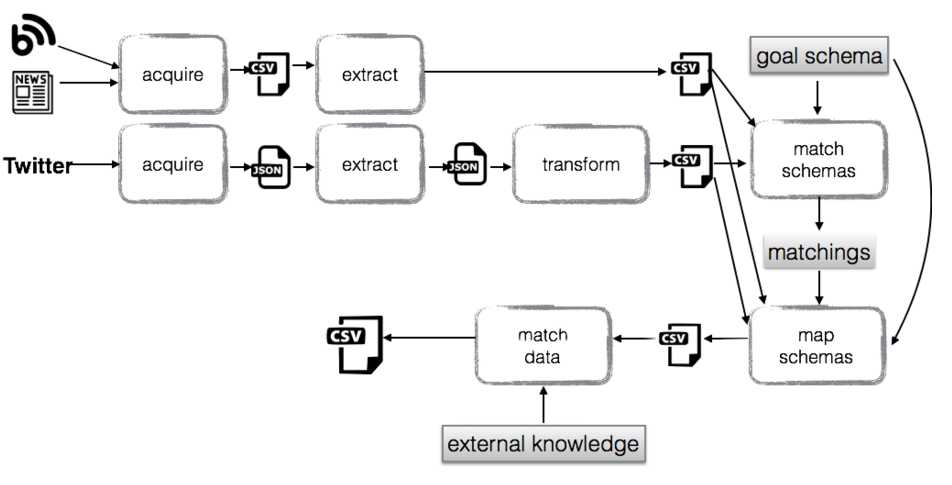
首先从不同来源(在本例中,从相关的推特、博客和新闻文章中)获取数据。一个获取步骤生成一个CSV文件,而另一个获取步骤生成一个JSON文件。然后使用两个抽取文件分别抽取以下信息:
1、 JSON格式的推特(公司、项目、{sentence, tweetid, date}),其中句子、推特ID和日期按照公司和项目分组;
2、 CSV格式的关于内容(公司名称、产品、情感表达、博客URL和日期)。之后,执行数据转换步骤,通过嵌套句子、推特ID和日期与公司名称和项目,将JSON文件转换为CSV文件。下一步就是匹配两个模式与用户设计的目标模式最终方案
(公司、产品、言语、省份、日期)。模式映射组件使用由此得到的匹配生成一个脚本,该脚本会将两个源转换并组合为符合目标模式的数据。最后一步是数据匹配,其目标在于识别属于同一个公司和产品配对的所有言语。
不同的步骤可以手动或者通过流程管理工具进行组合和协调
标签:src 示例 数据库 格式 使用 行数据 名称 脚本 开源
原文地址:http://www.cnblogs.com/shaosks/p/7151471.html