标签:window copy 浅复制 初始化 sed closed sub 说明 元素
list = [ 1, 2,3,4,5 ]
set1 = set ( list )
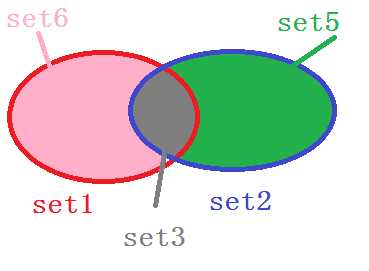
求交集: set3 = set1.intersection(set2) 或者 set3 = set1 & set2
求并集:set1.union(set2) 或者 set1 | set2
求差集:set6 = set1.difference(set2) 或者 set6 = set1 - set2
set5 = set2.difference(set1) 或者 set5 = set2 - set1
求对称差集: set5 + set6 = set1.symmetric_difference(set2) 或者 set5+set6 = set1 ^ set2
判断a是不是b的子集:a.issubset(b) 或者是判断b是不是a的父集, b.issuperset(a)
判断ab是否有交集: a.isdisjoint(b) 无交集返回TRUE 有交集返回FALSE
长度:len(set) , 判断元素是否在set里:x in set , 浅复制:set.copy()
增:set.add("aaaa")
set.update( [1,2,3,4,5] )
删:set.remove("aaa") 没有aaa报错 , set.discard("aaa") 没有aaa返回none
很神奇 , 没有改和查。。看来是不能直接在集合里改和查
比较low的方法: f = open("file_path","r","encoding=utf-8") 操作完后要关闭文件 f.close
高大上的方法:用完自动关闭
with open("file_path", "r" , "encoding=utf-8") as f1,
open("file_path", "r" , "encoding=utf-8") as f2 :
打开方式参数说明:
r : 只能读,一行一行的读
w:只能写,按顺序写,这个参数会创建一个新文件。切记
a:追加,打开一个文件然后,只能从最后面开始写
r+:这个读就是跟r一样,写就是跟a一样。前提是你不移动光标
w+:这个要创建空白文件或覆盖一个同名旧文件。不移动光标读不出任何数据,但是移动光标是闲的蛋疼才去干的事
a+:追加读。无论怎样移动光标,只能追加,但是不移动光标读不出来数据,也是个蛋疼的设计
rb:以二进制格式去读文件,读bytes类型的二进制,或者视频等文件,如果你想看010100101100可以这么干
wb:二进制写,写010110011010进去,传输bytes应该用得到
rU:\r\n变成\n打开,Windows写的可以拿到Linux里面运行了,不过,请问谁会用Windows的记事本去写脚本?除非他觉得自己时间没地方花。
读一下光标移动一下, 写一下光标移动一下,想象一下往记事本里写东西的感觉
操作光标:f.tell() 当前光标所在的字符位置(按字符个数)。 f.seek(0) 光标回到起点 , f.seek(10) 光标移到第10个字符。
我感觉我不太会去使用它,复杂的情况下,天知道你的光标会移动到哪里去了。。
读 : f.readline() 读一行,注意是光标所在位置的那一行,第一行光标移动一行
f.readlines() 把整个文件所有字符读进一个列表中,这个。。有可能把内存花光
f.read() 把整个文件所有字符读进一个字符串中,这个。。有可能把内存花光
f.read(5) 读从光标开始的5个字符,不过谁会去用它呢?
写 : f.write(“balabalabalabala”) 写字符串,按顺序写
遍历: 1. 高大上,速度快的方法:
count = 0
for line in f: f是文件句柄,迭代器
print(line)
count += 1
遍历2. 把内存撑爆的方法:自己搞着玩可以
for index,line in enumerate(f.readlines()):
print (index, line)
其他的一些蛋疼的方法:
| f.encoding 该文件的编码 | f.fileno()该文件句柄编号,操作系统维护 | f.isatty是不是终端设备文件 |
| f.name 文件名字 | f.seekable能不能移动指针 | f.readable 可读? |
| f.writable 可写? | f.closed 是否关闭 | f.flush() 缓存满了刷新进硬盘,同步要求高可用 |
| f.truncate() 干嘛用?需要查一下 | f.truncate(10) 截断10个 a模式下 |
import sys , time
for i in range(20):
sys.stdout.write(">") 标准输出.控制台
sys.stdout.flush()
time.sleep(0.1)
标签:window copy 浅复制 初始化 sed closed sub 说明 元素
原文地址:http://www.cnblogs.com/revo/p/7153448.html