标签:sci star multiple 图片 register ack append follow rmi
原文: https://wiki.linuxfoundation.org/networking/kernel_flow
Refer to Net:Network Overview for an overview of all aspects of the networking kernel: routing, neighbour discovery, NAPI, filtering, …
The network data (including headers etc.) is managed through the sk_buff data structure. This minimizes copying overhead when going through the networking layers. A basic understanding of sk_buff is required to understand the networking kernel.
The kernel as a whole makes heavy use of virtual methods. These are recorded as function pointers in data structures. In the figure these are indicated with diamonds. This article never shows all possible implementations for these virtual methods, just the main ones.
This article only discusses TCP over IPv4 over Ethernet connections. Of course, many combinations of the different networking layers are possible, as well as tunnelling, bridging, etc.
There are three system calls that can send data over the network:
All of these eventually end up in __sock_sendmsg(), which does security_sock_sendmsg() to check permissions and then forwards the message to the next layer using the socket‘s sendmsg virtual method.
tcp_sendmsg: for each segment in the message
The main function of the kernel at the link layer is scheduling the packets to be sent out. For this purpose, Linux uses the queueing discipline (struct Qdisc) abstraction. For detailed information, see Chapter 9 (Queueing Disciplines for Bandwidth Management) of the Linux Advanced Routing & Traffic Control HOWTO and Documentation//networking/multiqueue.txt.
dev_queue_xmit puts the sk_buff on the device queue using the qdisc→enqueue virtual method.
The device output queue is immediately triggered with qdisc_run(). It calls qdisc_restart(), which takes an skb from the queue using the qdisc→dequeue virtual method. Specific queueing disciplines may delay sending by not returning any skb, and setting up a qdisc_watchdog_timer() instead. When the timer expires, netif_schedule() is called to start transmission.
Eventually, the sk_buff is sent with dev_hard_start_xmit() and removed from the Qdisc. If sending fails, the skb is re-queued.netif_schedule() is called to schedule a retry.
netif_schedule() raises a software interrupt, which causes net_tx_action() to be called when the NET_TX_SOFTIRQ is ran by ksoftirqd. net_tx_action() calls qdisc_run() for each device with an active queue.
dev_hard_start_xmit() calls the hard_start_xmit virtual method for the net_device. But first, it calls dev_queue_xmit_nit(), which checks if a packet handler has been registered for the ETH_P_ALL protocol. This is used for tcpdump.
The device driver‘s hard_start_xmit function will generate one or more commands to the network device for scheduling transfer of the buffer. After a while, the network device replies that it‘s done. This triggers freeing of the sk_buff. If the sk_buff is freed from interrupt context,dev_kfree_skb_irq() is used. This delays the actual freeing until the next NET_TX_SOFTIRQ run, by putting the skb on the softnet_data completion_queue. This avoids doing frees from interrupt context.
The network device pre-allocates a number of sk_buffs for reception. How many, is configured per device. Usually, the addresses to the data space in these sk_buffs are configured directly as DMA area for the device. The device interrupt handler takes the sk_buff and performs reception handling on it. Before NAPI, this was done using netif_rx(). In NAPI, it is done in two phases.
netif_receive_skb() finds out how to pass the sk_buff to upper layers.
The packet handlers are called with the deliver_skb() function, which calls the protocol‘s func virtual method to handle the packet.
ARP packets are handled with arp_rcv(). It processes the ARP information, stores it in the neighbour cache, and sends a reply if required. In the latter case, a new sk_buff (with new data space) is allocated for the reply.
IPv4 packets are handled with ip_rcv(). It parses headers, checks for validity, sends an ICMP reply or error message if required. It also looks up the destination address using ip_route_input(). The destination‘s input virtual method is called with the sk_buff.
ip_local_deliver() delivers to any raw sockets for this connection first, using raw_local_deliver(). Then, it calls the L4 protocol handler for the protocol specified in the datagram. The L4 protocol is called even if a raw socket exists.
Throughout, xfrm4_policy_check calls are included to support IPSec.
The net_protocol handler for TCP is tcp_v4_rcv(). Most of the code here deals with the protocol processing in TCP, for setting up connections, performing flow control, etc.
A received TCP packet may include an acknowledgement of a previously sent packet, which may trigger further sending of packets (tcp_data_snd_check()) or of acknowledgements (tcp_ack_snd_check()).
Passing the incoming packet to an upper layer is done in tcp_rcv_established() and tcp_data_queue(). These functions maintain the tcp connection‘s out_of_order_queue, and the socket‘s sk_receive_queue and sk_async_wait_queue. If a user process is already waiting for data to arrive, the data is immediately copied to user space using skb_copy_datagram_iovec(). Otherwise, the sk_buff is appended to one of the socket‘s queues and will be copied later.
Finally, the receive functions call the socket‘s sk_data_ready virtual method to signal that data is available. This wakes up waiting processes.
There are three system calls that can receive data from the network:
All of these eventually end up in __sock_recvmsg(), which does security_sock_recvmsg() to check permissions and then requests the message to the next layer using the socket‘s recvmsg virtual method. This is often sock_common_recvmsg(), which calls the recvmsg virtual method of the socket‘s protocol.
tcp_recvmsg() either copies data from the socket‘s queue using skb_copy_datagram_iovec(), or waits for data to arrive using sk_wait_data(). The latter blocks and is woken up by the layer 4 processing.
官方文档配图内容丰富地讲解了上述具体函数调用关系及其中的数据对象操作
下面是图片一角
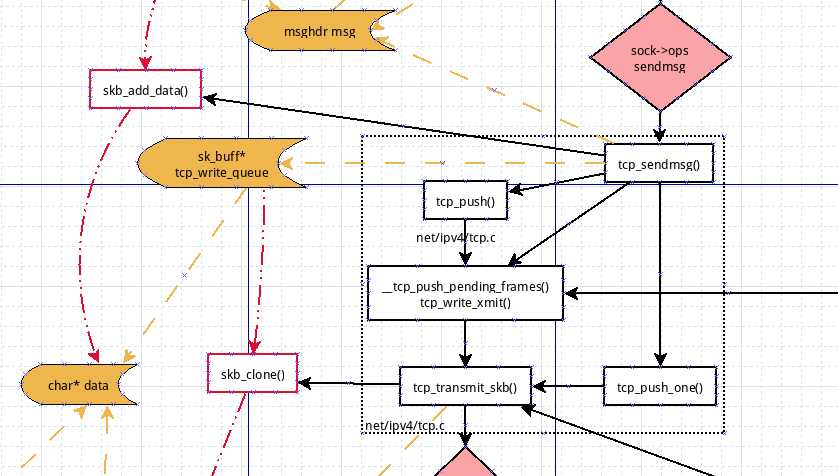
图片下载地址:https://wiki.linuxfoundation.org/images/a/a3/Network_data_flow_through_kernel.dia.gz
标签:sci star multiple 图片 register ack append follow rmi
原文地址:http://www.cnblogs.com/haoqingchuan/p/7157352.html
{kind=link}