标签:vlc new 运行 idc ber win 高效 同方 form
本文就Pandas的运行效率作一个对比的测试,来探讨用哪些方式,会使得运行效率较好。
测试环境如下:
需要说明的是,不同的系统,不同的电脑配置,不同的软件环境,运行结果可能有些差异。就算是同一台电脑,每次运行时,运行结果也不完全一样。
测试的内容为,分别用三种方法来计算一个简单的运算过程,即 a*a+b*b 。
三种方法分别是:
首先构造一个DataFrame,数据量的大小,即DataFrame的行数,分别为10, 100, 1000, … ,直到10,000,000(一千万)。
然后在jupyter notebook中,用下面的代码分别去测试,来查看不同方法下的运行时间,做一个对比。
import pandas as pd
import numpy as np
# 100分别用 10,100,...,10,000,000来替换运行
list_a = list(range(100))
# 200分别用 20,200,...,20,000,000来替换运行
list_b = list(range(100,200))
print(len(list_a))
print(len(list_b))
df = pd.DataFrame({‘a‘:list_a, ‘b‘:list_b})
print(‘数据维度为:{}‘.format(df.shape))
print(len(df))
print(df.head())
100
100
数据维度为:(100, 2)
100
a b
0 0 100
1 1 101
2 2 102
3 3 103
4 4 104
执行运算, a*a + b*b
Method 1: for循环
%%timeit
# 当DataFrame的行数大于等于1000000时,请用 %%time 命令
for i in range(len(df)):
df[‘a‘][i]*df[‘a‘][i]+df[‘b‘][i]*df[‘b‘][i]
100 loops, best of 3: 12.8 ms per loop
type(df[‘a‘])
pandas.core.series.Series
%%timeit
df[‘a‘]*df[‘a‘]+df[‘b‘]*df[‘b‘]
The slowest run took 5.41 times longer than the fastest. This could mean that an intermediate result is being cached.
1000 loops, best of 3: 669 µs per loop
type(df[‘a‘].values)
numpy.ndarray
%%timeit
df[‘a‘].values*df[‘a‘].values+df[‘b‘].values*df[‘b‘].values
10000 loops, best of 3: 34.2 µs per loop
运行结果如下:
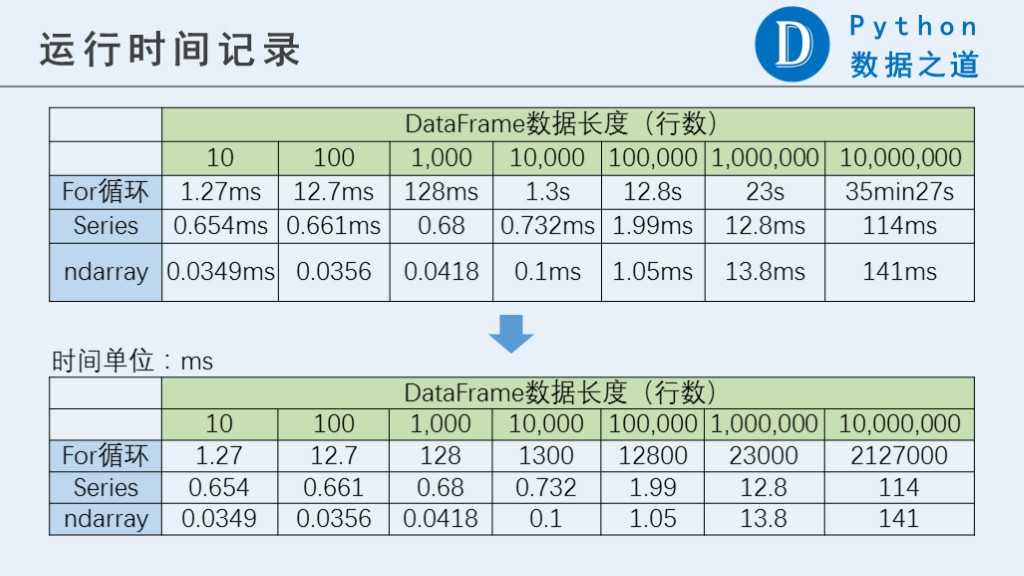
从运行结果可以看出,for循环明显比Series和ndarray要慢很多,并且数据量越大,差异越明显。当数据量达到一千万行时,for循环的表现也差一万倍以上。 而Series和ndarray之间的差异则没有那么大。
PS: 1000万行时,for循环运行耗时特别长,各位如果要测试,需要注意下,请用 %%time 命令(只测试一次)。
下面通过图表来对比下Series和ndarray之间的表现。
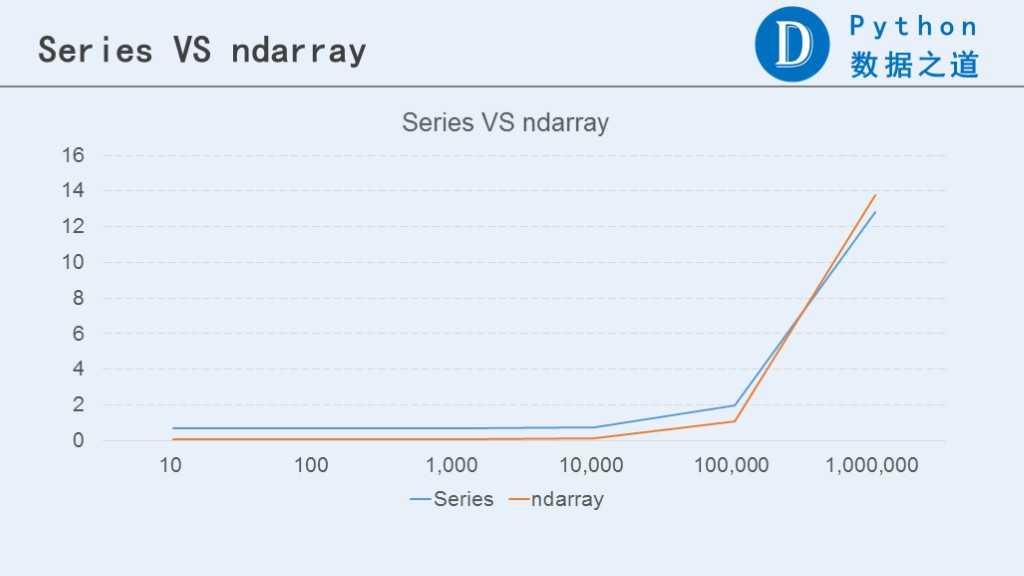
从上图可以看出,当数据小于10万行时,ndarray的表现要比Series好些。而当数据行数大于100万行时,Series的表现要稍微好于ndarray。当然,两者的差异不是特别明显。
所以一般情况下,个人建议,for循环,能不用则不用,而当数量不是特别大时,建议使用ndarray(即df[‘col’].values)来进行计算,运行效率相对来说要好些。
Python: Pandas运算的效率探讨以及如何选择高效的运算方式
标签:vlc new 运行 idc ber win 高效 同方 form
原文地址:http://www.cnblogs.com/lemonbit/p/7162257.html