标签:style blog http color os io 使用 java strong
JAVA 并发
java的并行编程比较复杂,我也理解不深。但是最近由于要并行训练分类器,琢磨了一点,有错误请指正。只是大体介绍一下而已。
很多问题我们使用顺序编程便可以解决,但是有些问题如果能够使用多线程并行的执行其中的任务则可以很大程度的提高时间效率,所以多线程还是很有必要的。
我自己总结了JAVA并行的3个发展阶段(菜鸟总结,请体谅)
第一阶段:Thread ,Runable
第二阶段:Executor框架
第三阶段: ForkJoin并行框架
并发很大一方面是为了提高程序运行速度,如果想要一个程序运行的更快,那么可以将其分为多个片段,然后在每个单独的处理器上运行多个任务。现在是多核时代我们应该掌握,
但是我们知道并发通常是用在提高单核机器的程序性能上,这个咋一听感觉有点不能理解,学过操作系统的人应该知道,从一个任务切换到另一个任务是会有上下文开销的。但是因为有了“阻塞”,使得这个问题变得有些不同。
“阻塞”通常指的是一个程序的某个任务由于要执行程序控制之外的事,比如请求I/O资源,由于需要等待请求的I/O资源,所以会导致程序的暂停,就是cpu空闲。我们知道cpu是很宝贵的资源,我们应当充分利用它才对,这时候多线程就出来了,想想啊,当某个线程阻塞导致cpu空闲,这时候操作系统就将cpu分配给其他等待的线程使得cpu无时无刻不在运行。单个进程可以有多个并发执行的任务,我们感觉好像每个任务都有自己的cpu一样,其底层机制就是切分cpu时间,通常来说不需要我们管。
从事实上来看,如果程序没有任何阻塞,那么在单处理器上的并发是没有意义的。
(1)传统的并发编程(Thead、Runable)
我们看到最多的就是继承Thread类或者继承Runable接口。这两中方式都可以,如下继承Thread:
public class App { public static class demo extends Thread { int x; public demo(int x) { this.x=x; } public void run() { System.out.print("线程"+x); } } public static void main(String[] args) { demo dem=new demo(1); dem.start(); } }
无论是Thread还是Runable其实都只要我们覆盖实现Run方法就好了,但是由于java类只能继承一次而接口可以有无数个所以我们更经常使用Ruanble接口。我们调用新线程都是使用start()方法而不是run()方法。
start方法的本质:从cpu中申请另一个线程空间来执行run方法,这样是并发线程。(其实它也是会自己调用run里面的方法,但是如果我们直接调用run方法的话,那么就是单线程而已)
以上两种虽然可以实现基本的并行结构,但是对于复杂的问题就会很麻烦,因此就有了在jdk5里面引入的Excutor执行器。
(2)Executor框架
Executor框架是指java 5中引入的一系列并发库中与executor相关的一些功能类,其中包括线程池,Executor,Executors,ExecutorService,CompletionService,Future,Callable等。
Executor用来管理Runable对象的执行。用来创建并管理一组Runable对象的线程,这组线程就叫做线程池(Thread pool)
并发编程的一种编程方式是把任务拆分为一些列的小任务,即Runnable,然后在提交给一个Executor执行,Executor.execute(Runnalbe) 。Executor在执行时使用内部的线程池完成操作。
Thread t1 =new Thread(s1);
Thread t2 =new Thread(s2);
Thread t3 =new Thread(s3);
ExecutorService service = Executors.newCachedThreadPool();
service.execute(t1);
service.execute(t2);
service.execute(t3);
在Executor里面。我们可以使用Callable,Future返回结果,Future<V>代表一个异步执行的操作,通过get()方法可以获得操作的结果,如果异步操作还没有完成,则,get()会使当前线程阻塞。FutureTask<V>实现了Future<V>和Runable<V>。Callable代表一个有返回值得操作。
ThreadPoolExecutor myExecutor = new ThreadPoolExecutor(3, 10, 200, TimeUnit.SECONDS, new LinkedBlockingDeque<Runnable>()); List<Future<ArrayList<Integer>>> results = new ArrayList<Future<ArrayList<Integer>>>(); for (int i = 0; i < 3; i++) { AcoTask task = new AcoTask(choose); Future<ArrayList<Integer>> result = null; result = myExecutor.submit(task); results.add(result); } //ExecutoreService提供了submit()方法,传递一个Callable,或Runnable,返回Future。 //如果Executor后台线程池还没有完成Callable的计算,这调用返回Future对象的get()方法,会阻塞直到计算完成 for (Future<ArrayList<Integer>> f : results) { try { f.get(); } catch (Exception ex) { // ex.printStackTrace(); f.cancel(true); } }
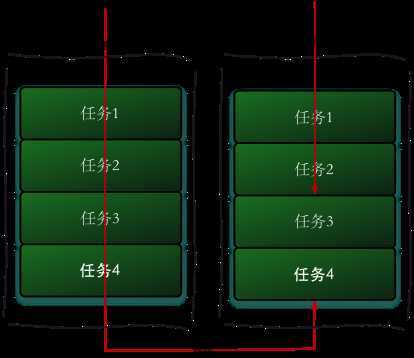
上面并发执行的挺好的,但是有个问题。不同的线程执行有块有慢,有的任务会提早执行完毕,因此为了利用这些提早执行完毕的线程,使用了一种工作窃取(work-stealing)算法。
(3) ForkJoin并行框架
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。是不是很像map/reduce。
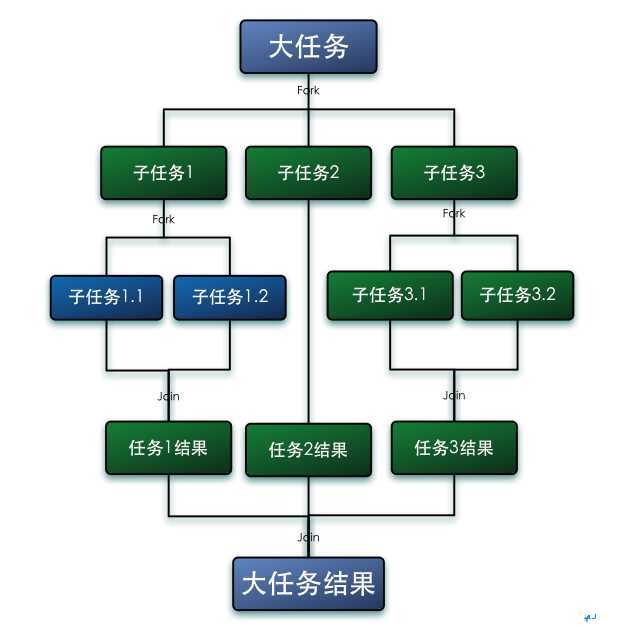
Fork/Join 模式有自己的适用范围。如果一个应用能被分解成多个子任务,并且组合多个子任务的结果就能够获得最终的答案,那么这个应用就适合用 Fork/Join 模式来解决。ForkJoin是将一个问题递归分解成子问题,再将子问题并行运算后合并结果。
让我们通过一个简单的需求来使用下Fork/Join框架,需求是:计算1+2+3+4的结果。
使用Fork/Join框架首先要考虑到的是如何分割任务,如果我们希望每个子任务最多执行两个数的相加,那么我们设置分割的阈值是2,由于是4个数字相加,所以Fork/Join框架会把这个任务fork成两个子任务,子任务一负责计算1+2,子任务二负责计算3+4,然后再join两个子任务的结果。
因为是有结果的任务,所以必须继承RecursiveTask。
我们只需要关注子任务的划分和中间结果的组合。ForkJoinTask完成子任务的划分,然后将它提交给ForkJoinPool来完成应用。
关于Fork/Join的代码查看 : http://blog.csdn.net/lubeijing2008xu/article/details/18036931
http://www.oracle.com/technetwork/cn/articles/java/fork-join-422606-zhs.html
http://www.ibm.com/developerworks/cn/java/j-lo-forkjoin/
标签:style blog http color os io 使用 java strong
原文地址:http://www.cnblogs.com/GuoJiaSheng/p/3950001.html