标签:ges 去重 博客 有一个 循环 转换 log 自己 远程
“总是向你索取却不曾说谢谢你~~~~”,在博客园和知乎上面吸收了很多知识,以后也会在这里成长,这里挺好,谢谢博客园和知乎,所以今天也把自己在项目期间做的东西分享一下,希望对朋友们有所帮助。。。。
废话少说,let‘s go~~~~!
需求:
项目需要做一个婚恋网站,主要技术有nginx,服务器集群,redis缓存,mysql主从复制,amoeba读写分离等等,我主要用rabbitMQ+python完成并实现了数据爬取工作(数据库写入及图片下载保存),速度的话公司的电脑爬的(i5+16g&网站需要验证登录),网速给力的话应该可以更快些(我公司的网,我也就不多评价了·······^_^),亲测爬“~车之家”的二手车数据,一个小时15-20W(无登陆,无反扒)。
1.爬虫前你需要了解的:
1)网页的结构:
a.你知道吗,爬这个网站能让你恶心,字段极多,并且男生的页面和女生的页面结够还不一样,所以男女数据所在网页里面的位置也就不一样,标签属性也有不同的地方,所以,我是用 if分开男女去分别爬取的,中间也包含一些数据转换和拆分处理,也有一 些小坑,我在下面的代码里会说
b.网站有反扒技术,之前写了一个爬虫,请求,解析,存取都在一个文件中,当请求过快时会被服务器远程强制断掉,解决的办法是使用代理ip和更换UserAgent,但是有一个bug就是代理爬取的代理ip的可用度极低,导致速度极慢,后来就果断注掉了,发现 是ok的,他的反爬机制没有弄的太明白.
c.模拟登陆:严格说不能算模拟,解决的办法是手动在网页登陆之后,然后把去浏览器中把cookie抓出来,放到headers里面,请求的时候带上cookie,这样就能请求到登陆之后才能抓到的数据了。
d.分析网页,用户的详情页是跟随id在改变的,所以爬取的逻辑是用一个for循环id+请求的连接,还能天然的去重,中间有时会出现未知的错误断掉,大家可以自己在for外面捕获一个异常,然后整个代码装在一个def里,用递归实现一直循环
2)在linux中配置rabbitMQ可以参见我的另外一篇文章:http://www.cnblogs.com/devinCat/articles/7172927.html
3)开发工具:pycharm+python3.6
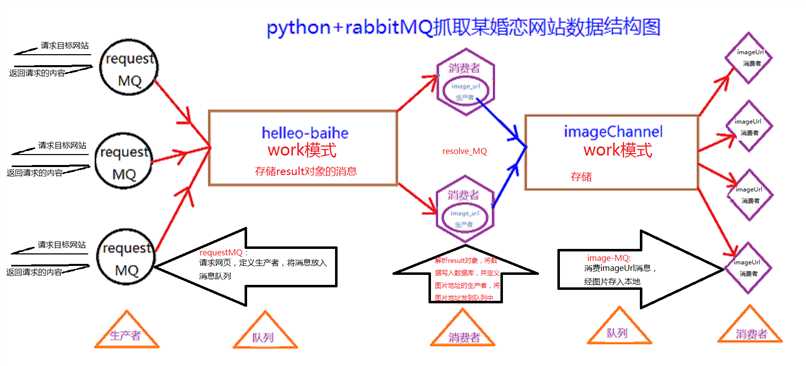
2.简单的说下MQ在这个任务中的作用:将一个任务纵向拆分成若干块,每一块之间以消息队列为介质进行连接并传送需要的信息,这样让执行不同任务逻辑的的代码可以并行工作,互不影响并且能提高程序运行的效率,消息队列有六个工作模式,这里用到的是work模式,建议百度了解原理,在此不过多阐述。下面我自己画了一张图助于大家理解代码的实现逻辑和过程,希望能帮到大家!(大一点看得比较清楚)
代码放在GitHub里,本人小白,希望大神们多多指点:https://github.com/DevinCat/Cat
后续会把多线程也加进去,不断地优化和改进,虽然辛苦,实现之后还是有一种那叫什么感来着^?_?^,望大家多多指点,欢迎留言交流·····!
标签:ges 去重 博客 有一个 循环 转换 log 自己 远程
原文地址:http://www.cnblogs.com/devinCat/p/7172944.html