标签:des order by images share efi 卡尔 sha 编译问题 接收
第一部分 知识准备
1. sql执行过程
2. sql 共享
3. 绑定变量
4. 数据表访问方式
5. sql 执行顺序
6. 索引使用
1. sql执行过程
1)执行过程
当一个oracle实例接收到一条sql后,执行过程如下:
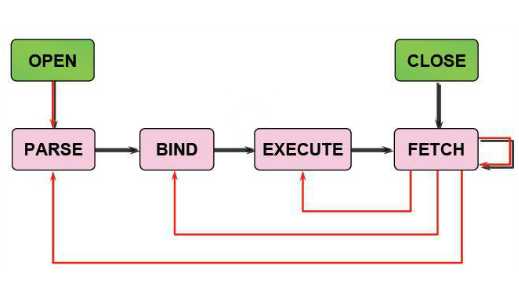
1) create a cursor 创建游标
2) parse the statement 分析语句
3) describe results of a query 描述查询的结果集
4)define output of a query 定义查询的输出数据
5)bind any variables 绑定变量
6)parallelize the statement 并行执行语句
7)run the statement 运行语句
8)fetch rows of a query 取查询结果
9)close the cursor 关闭游标
2.SQL 共享
1. 为不重复解析相同的SQL语句,oracle 将执行过的SQL语句存放在内存的共享池(shared buffer pool)中,可以被所有数据库用户共享
2. 当执行一个SQL语句时,如果它和之前执行过的语句完全相同(注意同义词和表是不同对象),oracle就能获得已经被解析的语句;
3.bind variables绑定变量
1)解决重编译问题
eg1:
insert into tab1(col1,col2) values (val1,val2); --普通方式
insert into tab1(col1,col2) values (:v1,:v2); --绑定变量,只需编译一次
eg2:使用PreparedStatement
PreparedStatement ps = con.prepareStatement("insert into tab1 (col1, col2) values (?,?)");
2)共享游标
好处:减少解析;提高内存使用率;动态内存调整
假如输入如下两个sql:
select * from tab1 where id = :c;
select * from tab1 where id = :d;
这两句sql会被转化为:
select * from tab1 where id = :b;
4.访问数据表方式
1)全表扫描——顺序访问表中每条记录
oracle采用一个读入多个数据块的方式优化全表扫描
2)通过rowid访问表——rowid包含了表中记录的物理位置信息, 基于rowid访问方式可以提高访问表的效率
oracle通过索引实现了数据和存放数据位置rowid之间的联系,通常索引提供了快速访问rowid的方法
5. select sql执行顺序
1)select子句
(8)SELECT (9)DISTINCT (11)<Top Num> <select list>
(1)FROM <left_table>
(3)<join_type> JOIN <right_table>
(2)ON <join_condition>
(4)WHERE <where_condition>
(5)GROUP BY <group_by_list>
(6)WITH <CUBE | RollUP>
(7)HAVING <having_condition>
(10)ORDER BY <order_by_list>
2)执行顺序说明
1)FROM [left table]——from前的表做笛卡尔集 ——虚拟表VT1
2) ON <join condition>——筛选——VT2
3) [join type] JOIN [right table]——连接——VT3
4) WHERE ——where筛选——VT4
5)GROUP BY ——按照GROUP BY子句中的列对VT4中行分组——VT5
6)CUBE|ROLLUP——分组,eg:ROLLUP(A, B),首先会对(A、B)进行GROUP BY,然后对(A)进行GROUP BY,最后对全表GROUP BY
CUBE(A,B), 首先对(A、B)GROUP BY, 然后(A)、(B) GROUP BY, 最后全表GROUP BY;
——VT6
7) HAVING——HAVING筛选——VT7
8)SELECT——VT8
9) DISTINCT——移除重复的行——VT9
10)ORDER BY——按照order by子句中的列将VT9中列表排序,生成游标——VC10
11) TOP ——从VC10的开始处选择一定数量或者比例的行——VT11,返回结果
3)注意事项
1. 只有ORDER BY 子句中可以使用select列表中列的别名
如果要在其他地方使用需要使用如下方式:
SELECT * FROM (SELECT NAME, SALARY AS s FROM EMP ) vt WHERE vt.s<5000;
2. 使用了ORDER BY子句的查询不能用作表表达式(视图、内联表值函数、子查询、派生表和共用表达式),如下的语句都会产生错误
create table tab1 as select * from student order by score;
select * from (select * from student order by score);
标签:des order by images share efi 卡尔 sha 编译问题 接收
原文地址:http://www.cnblogs.com/sunziying/p/7185806.html