标签:字符串大小 字符编码 ase pac 去掉 分割 0.00 小数 star
1.Python变量类型:
(1)数字
int类型:有符号整数,就是C语言中所指的整型,也就是数学中的整数,它的大小与安装的解释器的位数有关
查看当前系统下的Int最大值:
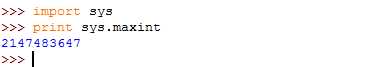
与C语言不同,Python给变量赋值时不需要预先声明变量类型,也就是说在给变量赋值时小于2147483647的数字默认认为是int类型,超过了则自动为Long类型
另外,八进制数字,十六进制数字都属于int(Long)类型的
Long类型:长整型,超过int类型的整数默认转换为Long,一般来说int足够用了,只要内存足够大,Long类型没有限制大小,想赋值多大都行
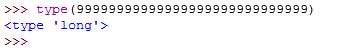
Float类型:浮点型实数,也就是数学中带小数点的数,不包括无限小数,不区分精度,只要是带小数点的数都可以看作是浮点型数据
Complex类型:复数,在C语言中需要自定义的一个数据类型,在Python中把它单独列出作为基本数据类型
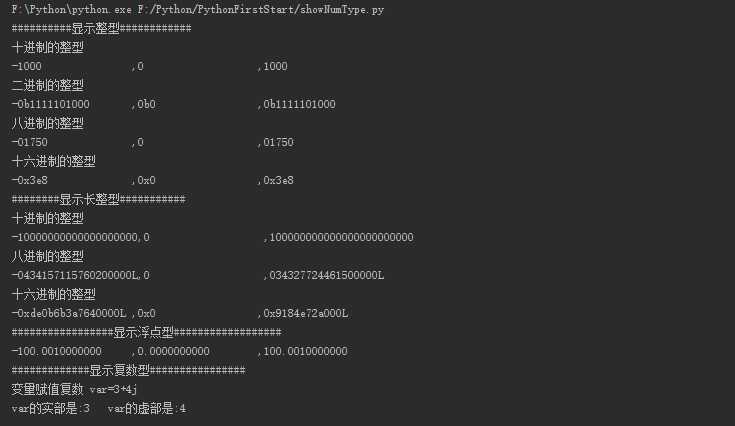
用一个简单的程序来显示Python的数字类型:
# !usr/bin/env python
# -*- coding:utf-8 -*-
class ShowNumType(object):
def __init__(self):
self.showInt()
self.showLong()
self.showFloat()
self.showComplex()
def showInt(self):
print(u"##########显示整型############")
print(u"十进制的整型")
print("%-20d,%-20d,%-20d" %(-1000,0,1000))
print(u"二进制的整型")
print("%-20s,%-20s,%-20s" %(bin(-1000),bin(0),bin(1000)))
print(u"八进制的整型")
print("%-20s,%-20s,%-20s" %(oct(-1000),oct(0),oct(1000)))
print(u"十六进制的整型")
print("%-20s,%-20s,%-20s" %(hex(-1000),hex(0),hex(1000)))
def showLong(self):
print(u"########显示长整型###########")
print(u"十进制的整型")
print("%-20Ld,%-20Ld,%-20Ld" %(-10000000000000000000,0,100000000000000000000000))
print(u"八进制的整型")
print("%-20s,%-20s,%-20s" %(oct(-10000000000000000),oct(0),oct(1000000000000000)))
print(u"十六进制的整型")
print("%-20s,%-20s,%-20s" %(hex(-1000000000000000000),hex(0),hex(10000000000000)))
def showFloat(self):
print(u"#################显示浮点型##################")
print("%-20.10f,%-20.10f,%-20.10f" %(-100.001,0,100.001))
def showComplex(self):
print(u"#############显示复数型################")
print(u"变量赋值复数 var=3+4j" )
var=3+4j
print(u"var的实部是:%d\tvar的虚部是:%d" %(var.real,var.imag))
if __name__==‘__main__‘:
showNum=ShowNumType()
2. 字符串是被定义在引号和双引号之间的一组连续的字符,这个字符可以是键盘上的所有可见字符,也可以是不可见的如"回车符"“”“制表符”等等
经典的字符串的操作方法有:
(1)字符串的大小写转换:
S.lower():字母大写转换为小写
S.upper():字母小写转换为大写
S.swapcase():字母大写转换小写,小写转换为大写
S.title():将首字母大写
(2)字符串搜索,替换:
S.find(substr,[start,[end]]):返回S中出现的substr的第一个字母的标号,如果S中没有substr则返回-1,start和end作用就相当于在S[start:end]中搜索
S.count(substr,[start,[end]]):计算substr在S中出现的次数
S.replace(oldstr,newstr,[count]): 把S中的oldstr替换为newstr,count为替换次数
S.strip([chars]):把S左右两端chars中有的字符全部去掉,一般用于去除空格
S.lstrip([chars]):把S左端chars中所有的字符全部去掉
S.rstrip([chars]):把S右端chars中所有的字符全部去掉
(3)字符串分割,组合:
S.split([sep,[maxsplit]]):以sep为分隔符,把S分成一个list,maxsplit表示分割的次数,默认的分割符为空白字符
S.join(seq):把seq代表的序列---字符串序列,用S连接起来
(4)字符串编码,解码:
S.decode([encoding]):将以encoding编码的S解码为unicode编码
S.encode([encoding]):将以unicode编码的S编码为encoding,encoding可以是GB2312,gbk,big5..........
(5)字符串测试:
S.isalpha():S是否全是字母,至少是一个字符
S.isdigit():S是否全是数字,至少有一个字符
S.isspace():S是否全是空白字符,至少有一个字符
S.islower():S中的字母是否全是小写
S.isupper():S中的字母是否全是大写
S.istitle():S是否首字母大写的
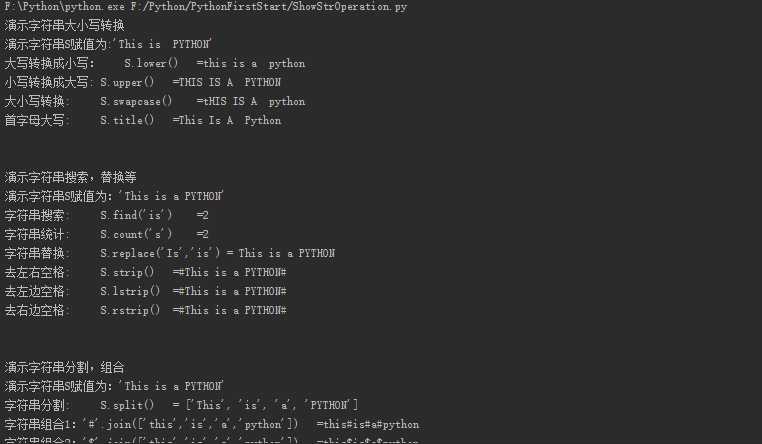
编写一个showStrOperation.py实验测试一下:
# !usr/bin/env python
# -*- coding:utf-8 -*-
def strCase():
"""字符串大小写转换"""
print "演示字符串大小写转换"
print "演示字符串S赋值为:‘This is PYTHON‘"
S=‘This is a PYTHON‘
print "大写转换成小写:\tS.lower()\t=%s" %(S.lower())
print "小写转换成大写:\tS.upper()\t=%s" %(S.upper())
print "大小写转换:\t\tS.swapcase()\t=%s" %(S.swapcase())
print "首字母大写:\t\tS.title()\t=%s" %(S.title())
print ‘\n‘
def strFind():
"""字符串搜索,替换"""
print "演示字符串搜索,替换等"
print "演示字符串S赋值为:‘This is a PYTHON‘"
S=‘This is a PYTHON‘
print "字符串搜索:\t\tS.find(‘is‘) \t=%s" %(S.find(‘is‘))
print "字符串统计:\t\tS.count(‘s‘) \t=%s" %(S.count(‘s‘))
print "字符串替换:\t\tS.replace(‘Is‘,‘is‘) = %s" %(S.replace(‘Is,‘,‘is‘))
print "去左右空格:\t\tS.strip() \t=#%s#" %(S.strip())
print "去左边空格:\t\tS.lstrip() \t=#%s#" %(S.lstrip())
print "去右边空格:\t\tS.rstrip() \t=#%s#" %(S.rstrip())
print ‘\n‘
def strSplit():
"""字符串分割,组合"""
print "演示字符串分割,组合"
print "演示字符串S赋值为:‘This is a PYTHON‘"
S=‘This is a PYTHON‘
print "字符串分割:\t\tS.split() \t= %s" %(S.split())
print "字符串组合1:‘#‘.join([‘this‘,‘is‘,‘a‘,‘python‘]) \t=%s" %(‘#‘.join([‘this‘,‘is‘,‘a‘,‘python‘]))
print "字符串组合2:‘$‘.join([‘this‘,‘is‘,‘a‘,‘python‘]) \t=%s" %(‘$‘.join([‘this‘,‘is‘,‘a‘,‘python‘]))
print "字符串组合3:‘ ‘.join([‘this‘,‘is‘,‘a‘,‘python‘]) \t=%s" %(‘ ‘.join([‘this‘,‘is‘,‘a‘,‘python‘]))
print ‘\n‘
def strCode():
"""字符串编码,解码"""
print "演示字符串编码,解码"
print "演示字符串S赋值为:‘编码解码测试‘"
S=‘编码解码测试‘
print "GBK编码的S \t=%s" %(S)
print "GBK编码的S转换为unicode编码"
print "S.decode(‘GBK‘)=%s" %(S.decode("GBK"))
print "GBK编码的S转换为utf8"
print "S.decode(‘GBK‘).encode(‘utf8‘)=%s" %(S.decode("GBK").encode("utf8"))
print "注意:不管是编码还是解码针对的都是unicode字符编码,\n所以要编码或解码前必须先将源字符串转换成unicode编码格式"
print ‘\n‘
def strTest():
"""字符串测试"""
print "演示字符串测试"
print "演示字符串S赋值为:‘abcd‘"
S1=‘abcd‘
print "测试S.isalpha()= %s" %(S1.isalpha())
print "测试S.isdigit()= %s" %(S1.isdigit())
print "测试S.isspace()= %s" %(S1.isspace())
print "测试S.islower()= %s" %(S1.islower())
print "测试S.isupper()= %s" %(S1.isupper())
print "测试S.istitle()= %s" %(S1.istitle())
if __name__==‘__main__‘:
strCase()
strFind()
strSplit()
strCode()
strTest()
2017.07.17 Python网络爬虫之Python基础1
标签:字符串大小 字符编码 ase pac 去掉 分割 0.00 小数 star
原文地址:http://www.cnblogs.com/hqutcy/p/7192853.html