标签:border func 显示 -- int 大写 机器 span 大小
Python的强大之处在于他有非常丰富和强大的标准库和第三方库
运行下列代码,会出现一系列路径,其中python的第三方库一般存在site-package,比如D:\\Program Files\\Anaconda3\\lib\\site-packages,标准库则在其上一级,即:D:\\Program Files\\Anaconda3\\lib
import sys
print(sys.path)
小技巧:
返回值为0表示执行成功了;
PS:2**=2^ 都是求幂;
55E4=55X10^4=55X10**4
PS:python的print 换行用‘\n‘表示
CTRL+单击对应的函数可以显示该函数的源代码,定义,解释之类的东西
真:1
假:0
Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了;
用import调用模块默认从当前目录下找,其次到环境变量里找,若当前目录下没有该模块,则报错;
解决方法:把要调用的模块复制到site-packages目录下,具体用上述代码寻找该目录;
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
创建列表:
|
1
2
3
|
name_list = [‘alex‘, ‘seven‘, ‘eric‘]或name_list = list([‘alex‘, ‘seven‘, ‘eric‘]) |
三元运算
有条件的赋值:
|
1
|
result = 值1 if 条件 else 值2 |
如果条件为真:result = 值1
如果条件为假:result = 值2
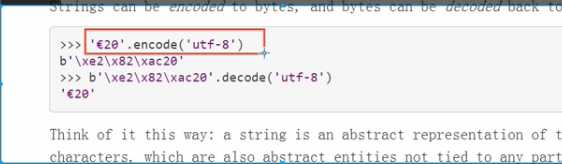
python里文本都是unicode,为str;而二进制都是bytes,主要存储音频视频等无法用文字存储的内容;
在数据传输中无论字符串还是视频等都是用二进制传输,此时字符串就要强制转成二进制;
字符串编码(encode)成二进制;二进制解码(decode)成字符串;
encode and decode 要申明之前是什么编码类型(如utf-8),如果不指定,python3里可以(强制utf-8)
今日的代码
# -----------------Welcome to python---------------------
# names="Alex Jack Bob Tom"
names = ["Alex", "Jack", "Bob", "Tom"]
print(names)
‘‘‘
"Alex", "Jack", "BOb", "Tom"
0 1 2 3
‘‘‘
print(names[1:3]) # 顾头不顾尾‘Jack‘, ‘BOb‘(只包括头部不包括尾部)
print(names[-1]) # 从后往前取
print(names[-3:-1]) # 从后往前取但是是从左往右数‘Jack‘, ‘BOb‘
‘‘‘
"Alex", "Jack", "Bob", "Tom"
-3 -2 -1 0
‘‘‘
‘‘‘
print(names[-2:0])但是要想取到最后一个数据,这个写法是错误的
这样写才对:
print(names[-2:])表示取最后两个数据 结果为‘BOb‘, ‘Tom‘
同理这样也可以:
print(names[0:3])表示取前三个数据
print(names[:3])也表示取前三个数据
‘‘‘
# 数据的追加append(在最后加上数据)
# names.append("Last")
# 数据的插入
names.insert(1, "Jerry")
print(names) # 结果为[‘Alex‘, ‘Jerry‘, ‘Jack‘, ‘BOb‘, ‘Tom‘]
数据的更换 必须是下标!
names[2]="New name"
print(names) 结果为[‘Alex‘, ‘Jerry‘, ‘New name‘, ‘BOb‘, ‘Tom‘]
数据的删除
第一种方法: names.remove("要删除的数据")
比如: names.remove("Jerry")
第二种方法: del names[要删除的下标]
比如:del names[2]
第三种方法: names.pop() #不输入下标就删掉了最后一个数据
输入了下标就删除对应下标的数据
此时names.pop(i)=del names[i] 效果一样
‘‘‘
统计列表里有多少重复的数据 count()
print(names.count("重复的数据"))
对列表数据进行排序(按特殊字符,数字,字母大写,字母小写的顺序依次来的)
names.sort()
列表的合并,extend()
names2=[1,2,3,4]
names.extend(names2)#这里names2的数据加入到names里了
print(names) 结果[‘Alex‘, ‘Jerry‘, ‘Jack‘, ‘Bob‘, ‘Tom‘, 1, 2, 3, 4]
列表的删除 del 列表名
names2=[1,2,3,4]
names.extend(names2)
del names2
print(names,names2) #结果NameError: name ‘names2‘ is not defined
‘‘‘
列表的复制 copy()
如: names2=names.copy()
列表里还可以包含列表(子列表)
names=[‘Alex‘, ‘Jerry‘,[‘aaa‘,‘bbb‘,‘ccc‘], ‘New name‘, ‘BOb‘, ‘Tom‘]
print(names)
print(names[2]) #[‘aaa‘, ‘bbb‘, ‘ccc‘]
子列表的赋值:
names[2][0]="AAA"#父列表第三个[‘aaa‘,‘bbb‘,‘ccc‘],子列表[‘aaa‘, ‘bbb‘, ‘ccc‘]第一个数据
‘‘‘
names = [‘Alex‘, ‘Jerry‘, [‘aaa‘, ‘bbb‘, ‘ccc‘], ‘New name‘, ‘BOb‘, ‘Tom‘]
names2 = names.copy()
names2[1]="JERRY"
names[2][0] = "AAA"
print(names)
print(names2) # [‘Alex‘, ‘Jerry‘, [‘AAA‘, ‘bbb‘, ‘ccc‘], ‘New name‘, ‘BOb‘, ‘Tom‘]
# copy()只是浅copy(很少用到),实际上子列表存在不同于父列表的内存地址里,浅copy只复制了父列表的第一层,
# 子列表的内存地址还是原来的。这样导致列表的复制不全(不独立)
# 比如上例,names的子列表为 [‘aaa‘, ‘bbb‘, ‘ccc‘],copy给names2,然后把names的子列表第一项改为"AAA",按理说names2不会改,
#可是names2也跟着改了(子列表的内存地址还是原来的),因此copy()后的子列表是不独立的!!!(父列表还是完全独立的!)
# 像a=xxx b=a a=yyy 之类简单的字符串或数字 b的值不会变成yyy,这样是完全独立
#但是对于列表来说,像上述赋值这内存地址是完全一样的,即完全不独立
#总之,浅copy的子列表内存地址与原来的一样,一旦对其进行改动则复制前后的子列表都会改动;
#一个列表直接赋值给另一个列表,内存地址不变,即完全不独立;字符串或数字则内存地址改变,完全独立
‘‘‘
列表的循环
for i in names:
print(i)
print(names[0:-1:2])
这里的冒号可以省略,变为names[::2],效果一样
‘‘‘
标签:border func 显示 -- int 大写 机器 span 大小
原文地址:http://www.cnblogs.com/gilgamesh-hjb/p/7198615.html