标签:理解 万达 默认参数 第一个 arch rem 整数 tabs 开始
1、列表、元素操作
定义列表
list = [‘Doris‘,‘Linda‘,‘Dandy‘,‘Allen‘]
基础的读取操作

1 list = [‘Doris‘,‘Linda‘,‘Dandy‘,‘Allen‘]
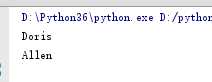
2 print(list[0]) # 填写元素下表就可以读取
3 print(list[-1])# 根据基础一讲过的可以知道-1代表最后一位
结果如下:
1 import copy
2 list = [‘scott‘,‘steven‘,‘linda‘,‘doris‘,‘joy‘,‘dandy‘]
3 listcopy = list.copy()
4 #add
5 list.append(‘allen‘)#追加
6 list.insert(0,‘alex‘)#插入
7 list.insert(2,‘i am follow scott‘)
8 #modify
9 list[2]=‘i do not care‘
10 print(list)
11 #delete
12 del list[2]
13 list.remove(‘allen‘)
14 list.pop()#pop()默认参数是-1表示数组的最后一位,当然也可以加上下标数字来指定删除
15
16 print(list)
17 print(listcopy)
18 #search
19 print(list[0:2])#表示切片取出0,1 (不包括2)
20 print(list[1:-1])#表示切片取出1到最后一位但不包含它
21 print(list[1:])#想要包含最后一位的话,使用这种格式
22 print(list[:2])#同理从数组开始取也可以这样写
23 print(list[::2])#从for循环我们得到一个类似的样式是否此处也可以用隔位符来隔位取?答案当然是可以的
24 #扩展 追加一个数组
25 listend=[‘1‘,‘2‘,‘3‘,‘4‘,‘5‘]
26 list.extend(listend)
27 #统计
28 print(list.count(‘scott‘))
29 print(list)
代码里涉及到增删改查的运行结果如下:
[‘alex‘, ‘scott‘, ‘i do not care‘, ‘steven‘, ‘linda‘, ‘doris‘, ‘joy‘, ‘dandy‘, ‘allen‘]
[‘alex‘, ‘scott‘, ‘steven‘, ‘linda‘, ‘doris‘, ‘joy‘]
[‘scott‘, ‘steven‘, ‘linda‘, ‘doris‘, ‘joy‘, ‘dandy‘]
[‘alex‘, ‘scott‘]
[‘scott‘, ‘steven‘, ‘linda‘, ‘doris‘]
[‘scott‘, ‘steven‘, ‘linda‘, ‘doris‘, ‘joy‘]
[‘alex‘, ‘scott‘]
[‘alex‘, ‘steven‘, ‘doris‘]
1
[‘alex‘, ‘scott‘, ‘steven‘, ‘linda‘, ‘doris‘, ‘joy‘, ‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘]
数组的排序&翻转&获取下标:
1 list = [‘scott‘,‘steven‘,‘linda‘,‘doris‘,‘joy‘,‘dandy1‘,‘Dandy‘,‘2alex‘,‘_guapi‘]
2 list.sort()#排序
3 print(list)
4 list.reverse()#翻转
5 print(list)
运行结果如下:
[‘2alex‘, ‘Dandy‘, ‘_guapi‘, ‘dandy1‘, ‘doris‘, ‘joy‘, ‘linda‘, ‘linda‘, ‘scott‘, ‘steven‘]
[‘steven‘, ‘scott‘, ‘linda‘, ‘linda‘, ‘joy‘, ‘doris‘, ‘dandy1‘, ‘_guapi‘, ‘Dandy‘, ‘2alex‘]
2 #其中如果存在2个同样的值,输出第一个的位置
上面基本讲完了数组的基本操作,现在提一点,刚刚对于copy只是一带而过,但是copy真的这么简单么?答案当然是否定的,下面我们讲解浅copy
1 import copy
2 #首先我们定义一个多维数组
3 list = [‘scott‘,[‘steven‘,‘10000‘],[‘linda‘,‘10530‘],‘doris‘,‘joy‘,‘dandy1‘,‘Dandy‘]
4 #copy 列表
5 listnew = list.copy()
6 #改一个单个的试一下
7 list[0] =‘老陈‘
8 #再改一个里面的数组试试
9 list[1][1] =‘50000‘
10 print(list)
11 print(listnew)
仔细看一下运行结果:
[‘老陈‘, [‘steven‘, ‘50000‘], [‘linda‘, ‘10530‘], ‘doris‘, ‘joy‘, ‘dandy1‘, ‘Dandy‘]
[‘scott‘, [‘steven‘, ‘50000‘], [‘linda‘, ‘10530‘], ‘doris‘, ‘joy‘, ‘dandy1‘, ‘Dandy‘]
代码只是改了原数组里面的数组,为什么会copy的那份也被改了呢?这就是我们提到的浅copy,只是浅浅的复制了第一层的数值,可以理解为第一层的下表指向这个数组,此数组魔种意义上来说,类似于一个共享的。
现在简单说一下元组
元组其实跟数组很类似也是存储一组数,只是一旦被创建了,就不能修改,所以又叫做只读列表
yuanzu = (‘tenglan wu‘,‘daqiaoweijiu‘,‘tianhai yi‘,‘jiatengying‘)
print(yuanzu)
没什么好说的,有且只有2个方法,index,count,(GG)
2、字符串操作
字符串的特性:不可修改。
1 name = "my NAme is dandy"
2
3 print(name.capitalize())#首字母大写
4 print(name.casefold())#全部小写
5 print(name.center(50,‘-‘))#用-补全2侧
6 print(name.count(‘a‘))#a的数量
7 print(name.encode())#二进制编码 输出结果会带 b
8 print(name.encode().decode())#二进制编码与转码
9 print(name.endswith(‘dy‘))#是否以此字符结尾
10
11 name1 = ‘i am \t dandy‘
12 print(name1.expandtabs(20))#TAB位置补全到20
13 print(name1.find(‘z‘))#找不到返回-1,有多个返回最前面的一个位置
14 print(name1.find(‘a‘))
15 print(name1.rfind(‘a‘))#rfind,lfind
运行结果:
My name is dandy
my name is dandy
-----------------my NAme is dandy-----------------
1
b‘my NAme is dandy‘
my NAme is dandy
True
i am dandy
-1
2
8
说到这,再熟悉一下format
1 #format
2 msg = ‘my name is {} and i am {} years old‘
3 print(msg.format(‘dandy‘,‘18‘))
4 msg1 = ‘my name is {0} and i am {1} years old‘
5 print(msg1.format(‘dandy‘,‘18‘))
6 msg2 = ‘my name is {name} and i am {age} years old‘
7 print(msg2.format(name=‘dandy‘,age=18))
8 msg3 = ‘my name is {name} and i am {age} years old‘
9 print(msg3.format_map({‘name‘:‘dandy‘,‘age‘:‘18‘}))
结果如下
my name is dandy and i am 18 years old
再来一波
1 name = "my Name is dandy"
2 print(name.index(‘a‘))#第一个a 的位置
3 print(‘9aD‘.isalnum())#是否全部为字母数字,是返回true
4 print(‘97823‘.isdigit())#是否是纯整数,是,返回true
5 print(‘11283121‘.isnumeric())#港真的,没发现跟上面的区别,妄点明
6 namelist = ‘aaa bbb ccc‘
7 print(‘My Name Is‘.istitle())#是否全部首字母大写,是,返回true
8 msgadc=‘taylor swift‘
9 print(msgadc.ljust(20,‘*‘))# 填充
10 print(msgadc.rjust(20,‘*‘))
11
12 msgzzz=‘ I love U \r‘
13 print(msgzzz.swapcase())#转换大小写
14 print(msgzzz.zfill(20))#左侧0填满到字节数
15 print(msgzzz.strip())#去掉空格跟\r ,lstrip & rstrip 不了解的就是瓜皮了
16
17 msg1=‘print‘
18 print(msg1.isidentifier())#是否是关键字
结果如下
4
True
True
True
True
taylor swift********
********taylor swift
i LOVE u
00000000 I love U
I love U
True
最后一波很有趣很有趣很有趣的语法
1 intext = ‘abcdefgh‘
2 outtext = ‘1!2@3#4$‘
3 trantext = str.maketrans(intext,outtext)
4 example = ‘the shape of you‘
5 print(example.translate(trantext))
6 #类似于一个解密加密的过程,不过却很山炮,真正的加密不是这样的
7 msg = ‘a and b and c ‘
8 print(msg.rpartition(‘and‘))
9 print(msg.rpartition((‘b‘)))
10 print(msg.rpartition((‘or‘)))
11 #如果存在多个匹配字符,默认最后一个操作;如果没有的,补充2个空的
12 namelist = ‘aaa bbb ccc‘
13 namelist1=(‘aaa‘,‘bbb‘,‘ccc‘)
14 print(‘|‘.join(namelist))#隔每个字符
15 print(‘|‘.join(namelist1))#分开3个字符串
结果如下
t$3 s$1p3 o# you
(‘a and b ‘, ‘and‘, ‘ c ‘)
(‘a and ‘, ‘b‘, ‘ and c ‘)
(‘‘, ‘‘, ‘a and b and c ‘)
a|a|a| |b|b|b| |c|c|c
aaa|bbb|ccc
3、字典操作
字典是一种Key - Value的数据类型,我们上学用的字典根据字母,笔画查找,这个有点类似的用key来找。
语法
info = {
‘10000‘:‘Linda Niu‘,
‘10001‘:‘Dandy Zhang‘,
‘10002‘:‘Doris Jing‘,
‘10003‘:‘Danli Wang‘,
‘10004‘:‘Xingyu Gu‘
}
查询
1 #因为字典的key value 的特性,职能根据key来查询(下标,value都不可以)
2 print(info[‘10004‘])#查询确定存在值的时候使用,不然会报错
3 print(info.get(‘10008‘))#查不到显示none
4 print(‘10001‘ in info)#返回真
5
6 info[‘10000‘]=‘曾小琴‘#修改
7 info[‘10005‘]=‘瓜皮‘#没有,自动添加
8 print(info)
9 #删除
10 del info[‘10005‘]
11 info.pop("10004")
12 info.popitem()#随便删除
13 print(info)
结果
Xingyu Gu
None
True
{‘10000‘: ‘曾小琴‘, ‘10001‘: ‘Dandy Zhang‘, ‘10002‘: ‘Doris Jing‘, ‘10003‘: ‘Danli Wang‘, ‘10004‘: ‘Xingyu Gu‘, ‘10005‘: ‘瓜皮‘}
{‘10000‘: ‘曾小琴‘, ‘10001‘: ‘Dandy Zhang‘, ‘10002‘: ‘Doris Jing‘}
字典的多级嵌套
语法
1 menu={
2 ‘江苏‘:{
3 ‘南京‘:{
4 ‘江宁区‘:["南京交院","江宁万达","南京金鹰"],
5 ‘秦淮区‘:["夫子庙","中华门","朝天宫"],
6 ‘玄武区‘:["南京火车站","中山陵","新街口"]
7 },
8 ‘苏州‘:{
9 ‘园区‘:[‘圆融‘,"独墅湖高校区","李公堤"],
10 ‘吴中区‘:[‘吴中万达‘,‘南门汽车站‘]
11 },
12 ‘无锡‘:{},
13 ‘泰州‘:{}
14 },
15 ‘安徽‘:{
16 ‘合肥‘,
17 ‘芜湖‘
18 },
19 ‘浙江‘:{
20 ‘杭州‘,
21 ‘宁波‘,
22 ‘金华‘
23 }
24 }
操作
menu[‘江苏‘][‘南京‘][‘江宁区‘][0] += ‘我跟南京交院是一条‘
print(menu[‘江苏‘][‘南京‘][‘江宁区‘])
结果
[‘南京交院我跟南京交院是一条‘, ‘江宁万达‘, ‘南京金鹰‘]
扩充
1 info = { "1801":"Dandy","1802":"Linda","1803":"Claire","1804":"Taylor"}
2 print(info.values())
3 print(info.keys())
4 info.setdefault("1801","宇宙无敌帅")#存在的话,不改;不存在的话新增一条
5 info.setdefault("1805","宇宙无敌帅")
6 print(info)
7 #update
8 aa_ = {"10086":"中国移动","10000":"中国电信","10010":"中国联通"}
9 info.update(aa_)
10 print(info)
11 print(info.items())
结果
dict_values([‘Dandy‘, ‘Linda‘, ‘Claire‘, ‘Taylor‘])
dict_keys([‘1801‘, ‘1802‘, ‘1803‘, ‘1804‘])
{‘1801‘: ‘Dandy‘, ‘1802‘: ‘Linda‘, ‘1803‘: ‘Claire‘, ‘1804‘: ‘Taylor‘, ‘1805‘: ‘宇宙无敌帅‘}
{‘1801‘: ‘Dandy‘, ‘1802‘: ‘Linda‘, ‘1803‘: ‘Claire‘, ‘1804‘: ‘Taylor‘, ‘1805‘: ‘宇宙无敌帅‘, ‘10086‘: ‘中国移动‘, ‘10000‘: ‘中国电信‘, ‘10010‘: ‘中国联通‘}
dict_items([(‘1801‘, ‘Dandy‘), (‘1802‘, ‘Linda‘), (‘1803‘, ‘Claire‘), (‘1804‘, ‘Taylor‘), (‘1805‘, ‘宇宙无敌帅‘), (‘10086‘, ‘中国移动‘), (‘10000‘, ‘中国电信‘), (‘10010‘, ‘中国联通‘)])
看一种生成字典的方法(有点坑,注意)
1 a = dict.fromkeys([1,2,3],‘tokoy hot‘)
2 print(a)
3 a[3]=‘一本道‘
4 print(a)
5 b = dict.fromkeys([1,2,3],[2,{"Company":"tokoy hot"},4])
6 print(b)
7 b[1][1]["Company"] = "一本道"
8 print(b)
注意看结果
{1: ‘tokoy hot‘, 2: ‘tokoy hot‘, 3: ‘tokoy hot‘}
{1: ‘tokoy hot‘, 2: ‘tokoy hot‘, 3: ‘一本道‘}
{1: [2, {‘Company‘: ‘tokoy hot‘}, 4], 2: [2, {‘Company‘: ‘tokoy hot‘}, 4], 3: [2, {‘Company‘: ‘tokoy hot‘}, 4]}
{1: [2, {‘Company‘: ‘一本道‘}, 4], 2: [2, {‘Company‘: ‘一本道‘}, 4], 3: [2, {‘Company‘: ‘一本道‘}, 4]}
循环简介dict
info = { "1801":"Dandy","1802":"Linda","1803":"Claire","1804":"Taylor"}
for key in info:
print(key,info[key])
for a,b in info.items():
print(a,b)
运行结果
1801 Dandy
1802 Linda
1803 Claire
1804 Taylor
1801 Dandy
1802 Linda
1803 Claire
1804 Taylor
4、集合操作
集合是一个无序的,不重复的数组,他的主要作用如下:
去重:把一个列表变成集合,自动去重
关系测试:测试两组数据之间的交集,差集,并集
1 list = [1,2,3,4,5,5,5,6,7,8,8,1,9]
2 lista = set(list)
3 print(lista)
4
5 list1 = set([1,3,5,7,9,6,8])
6 list2 = set([2,4,6,8,10,11])
7 #1,2 的并集
8 print(list1.union(list2))
9 print(list1 | list2)
10 #交集
11 print(list1.intersection((list2)))
12 print(list1 & list2)
13 #差集
14 print(list1.difference(list2))
15 print(list1 - list2)
16 print(list2.difference(list1))
17 print(list2 - list1)
结果
{1, 2, 3, 4, 5, 6, 7, 8, 9} {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11} {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11} {8, 6}
{8, 6} {1, 3, 5, 7, 9} {1, 3, 5, 7, 9} {11, 2, 10, 4} {11, 2, 10, 4}
语法函数
1 list = set([1,3,5,7,9,6,8])
2 name = set([5,3])
3 #增
4 list.add(‘a‘)#只能加一个元素
5 list.update([‘x‘,18,‘y‘])
6 list.remove(1)
7 print(len(list))
8 print(list)
9 print(name.issubset(list))#是否是子集
10 print(list.issuperset(name))#是否是父集
11 a=3
12 print(a in list)#是否存在于集合
13 list.copy()#浅copy
结果
10
{3, 5, 6, 7, 8, 9, ‘x‘, ‘a‘, 18, ‘y‘}
True
True
True
标签:理解 万达 默认参数 第一个 arch rem 整数 tabs 开始
原文地址:http://www.cnblogs.com/wuzdandz/p/7203472.html
