标签:art 台湾 目的 新加坡 code 中文字符集 推出 python orm
字符集和字符编码一般都是成对出现的,如ASCII、IOS-8859-1、GB2312、GBK,都是即表示了字符集又表示了对应的字符编码。Unicode比较特殊,有多种字符编码(UTF-8,UTF-16等)
ASCII(American Standard Code for Information Interchange, 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以部分支持其他西欧语言,并等同于国际标准ISO/IEC 646。
字符集
ASCII一共定义了128个字符,包括33个控制字符,和95个可显示字符。大部分的控制字符已经被废弃。
字符编码格式
ASCII码为单字节,用7位二进制数表示,由于计算机1个字节是8位二进制数,所以最高位为0,即00000000-01111111或0x00-0x7F。
Unicode,GBXXX,UTF-8等字符编码都兼容ASCII编码。
ASCII的缺点
是只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语。扩展出了EASCII,解决了部份西欧语言的问题。
EASCII(Extended ASCII,延伸美国标准信息交换码)
是将ASCII码由7位扩充为8位而成。EASCII的内码是由0到255共有256个字符组成。EASCII码比ASCII码扩充出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。
GB 2312 或 GB 2312–80 是中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB 2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。
GB 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。但对于人名、古汉语等方面出现的罕用字和繁体字,GB 2312不能处理,因此后来GBK及GB 18030汉字字符集相继出现以解决这些问题。
分区
GB 2312中对所收汉字进行了“分区”处理,每区含有94个汉字/符号。这种表示方式也称为区位码。
01–09区为特殊符号。 16–55区为一级汉字,按拼音排序。 56–87区为二级汉字,按部首/笔画排序。 举例来说,“啊”字是GB 2312之中的第一个汉字,它的区位码就是1601。 10–15区及88–94区则未有编码。
字符编码
在使用GB 2312的程序通常采用EUC储存方法,以便兼容于ASCII。 每个汉字及符号以两个字节来表示。第一个字节称为“高位字节”,第二个字节称为“低位字节”。
汉字内码扩展规范,称GBK,全名为《汉字内码扩展规范(GBK)》1.0版,由中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司和电子工业部科技与质量监督司1995年12月15日联合以《技术标函[1995]229号》文件的形式公布。
GBK的K为汉语拼音Kuo Zhan(扩展)中“扩”字的声母。英文全称Chinese Internal Code Extension Specification。
字符集
GB 2312-80只收录6763个汉字,有不少汉字,如部分在GB 2312-80推出以后才简化的汉字(如“啰”),部分人名用字(如中国前总理朱镕的“镕”字),台湾及香港使用的繁体字,日语及朝鲜语汉字等,并未有收录在内。GBK对GB 2312-80进行扩展, 总计拥有 23940 个码位,共收入21886个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号883 个。
字符编码 GBK 亦采用双字节表示,总体编码范围为8140-FEFE。 GBK向下完全兼容GB2312-80编码。支持GB2312-80编码不支持的部分中文姓,中文繁体,日文假名,还包括希腊字母以及俄语字母等字母。不过这种编码不支持韩国字,也是其在实际使用中与unicode编码相比欠缺的部分。
全称:国家标准GB 18030-2005《信息技术 中文编码字符集》,是中华人民共和国现时最新的内码字集,是GB 18030-2000《信息技术 信息交换用汉字编码字符集 基本集的扩充》的修订版。与GB 2312-1980完全兼容,与GBK基本兼容;支持GB 13000(93版等同于Unicode 1.1;2010版等同于Unicode 4.0)及Unicode的全部统一汉字,共收录汉字70,244个。 本规格的初版是由中华人民共和国信息产业部电子工业标准化研究所起草,由国家质量技术监督局于2000年3月17日发布。现行版本为国家质量监督检验总局和中国国家标准化管理委员会于2005年11月8日发布,2006年5月1日实施。
此标准内的单字节编码部分、双字节编码部分,和四字节编码部分收录的中日韩统一表意文字扩展A区汉字,为强制性标准。其他部分则属于规模性标准。在中华人民共和国境内所有软件产品,都需要支持这个同时包含单字节、双字节和四字节编码的规格。
GB 18030主要有以下特点:
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
可以这样理解:Unicode是字符集,UTF-32/ UTF-16/ UTF-8是三种字符编码方案。 UTF-8是一种很别扭的编码,具体表现在他是变长的,并且兼容ASCII
在python2默认编码是ASCII, python3里默认是unicode
unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
比如一款韩国软件,到中国以后显示乱码,那就得需要通过转码把他们编码集,转换为Unicode(utf-8)编码集。这样他们就可以正常显示韩文了!(这里只是转编码集并不是翻译成中文不要弄混了~~!) 编码转换过程如下图:
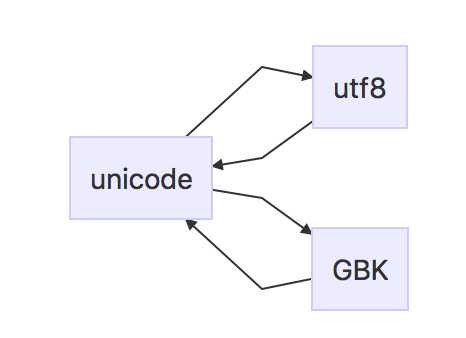
GBK需要转换为UTF-8流程:
UTF-8需要转换为GBK流程:
http://www.imooc.com/code/3269
http://www.cnblogs.com/alex3714/articles/5717620.html
http://www.cnblogs.com/chiguozi/p/5860364.html
http://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html
http://www.cnblogs.com/luotianshuai/articles/5735051.html
标签:art 台湾 目的 新加坡 code 中文字符集 推出 python orm
原文地址:http://www.cnblogs.com/cathywu/p/7209145.html