标签:orm 网络通信 bind size 三次握手 try 操作 定义 编号
原文地址:http://www.jb51.net/article/87466.htm
网络I/O模型
人多了,就会有问题。web刚出现的时候,光顾的人很少。近年来网络应用规模逐渐扩大,应用的架构也需要随之改变。C10k的问题,让工程师们需要思考服务的性能与应用的并发能力。
网络应用需要处理的无非就是两大类问题,网络I/O,数据计算。相对于后者,网络I/O的延迟,给应用带来的性能瓶颈大于后者。网络I/O的模型大致有如下几种:
网络I/O的本质是socket的读取,socket在linux系统被抽象为流,I/O可以理解为对流的操作。这个操作又分为两个阶段:
等待流数据准备(wating for the data to be ready)。
从内核向进程复制数据(copying the data from the kernel to the process)。
对于socket流而已,
第一步通常涉及等待网络上的数据分组到达,然后被复制到内核的某个缓冲区。
第二步把数据从内核缓冲区复制到应用进程缓冲区。
I/O模型:
举个简单比喻,来了解这几种模型。网络IO好比钓鱼,等待鱼上钩就是网络中等待数据准备好的过程,鱼上钩了,把鱼拉上岸就是内核复制数据阶段。钓鱼的人就是一个应用进程。
阻塞I/O(bloking I/O)
阻塞I/O是最流行的I/O模型。它符合人们最常见的思考逻辑。阻塞就是进程 "被" 休息, CPU处理其它进程去了。在网络I/O的时候,进程发起recvform系统调用,然后进程就被阻塞了,什么也不干,直到数据准备好,并且将数据从内核复制到用户进程,最后进程再处理数据,在等待数据到处理数据的两个阶段,整个进程都被阻塞。不能处理别的网络I/O。大致如下图:
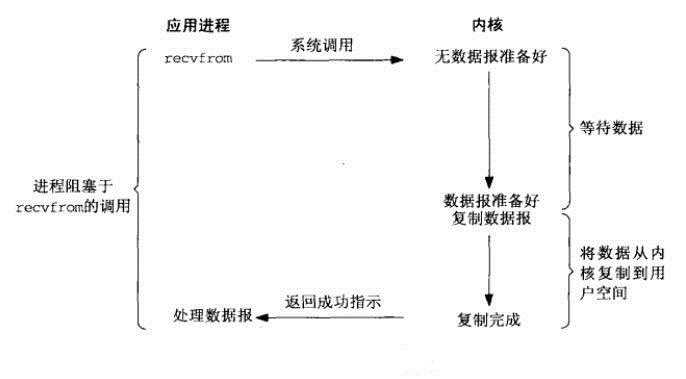
这就好比我们去钓鱼,抛竿之后就一直在岸边等,直到等待鱼上钩。然后再一次抛竿,等待下一条鱼上钩,等待的时候,什么事情也不做,大概会胡思乱想吧。
阻塞IO的特点就是在IO执行的两个阶段都被block了
非阻塞I/O(non-bloking I/O)
在网络I/O时候,非阻塞I/O也会进行recvform系统调用,检查数据是否准备好,与阻塞I/O不一样,"非阻塞将大的整片时间的阻塞分成N多的小的阻塞, 所以进程不断地有机会 ‘被‘ CPU光顾"。
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
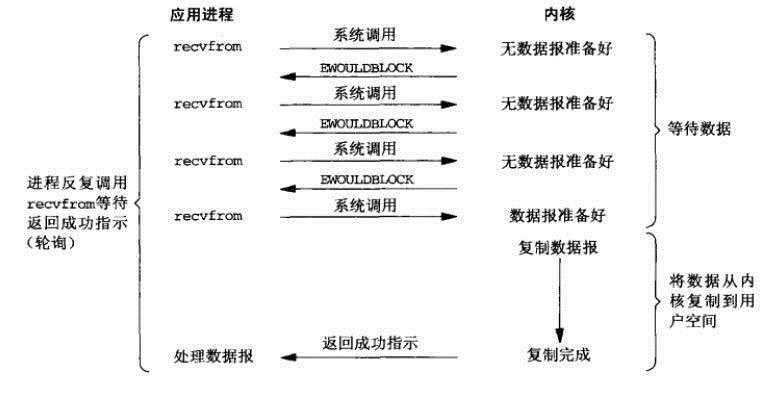
我们再用钓鱼的方式来类别,当我们抛竿入水之后,就看下鱼漂是否有动静,如果没有鱼上钩,就去干点别的事情,比如再挖几条蚯蚓。然后不久又来看看鱼漂是否有鱼上钩。这样往返的检查又离开,直到鱼上钩,再进行处理。
非阻塞 IO的特点是用户进程需要不断的主动询问kernel数据是否准备好。
多路复用I/O(multiplexing I/O)
可以看出,由于非阻塞的调用,轮询占据了很大一部分过程,轮询会消耗大量的CPU时间。结合前面两种模式。如果轮询不是进程的用户态,而是有人帮忙就好了。多路复用正好处理这样的问题。
多路复用有两个特别的系统调用select或poll。select调用是内核级别的,select轮询相对非阻塞的轮询的区别在于---前者可以等待多个socket,当其中任何一个socket的数据准好了,就能返回进行可读,然后进程再进行recvform系统调用,将数据由内核拷贝到用户进程,当然这个过程是阻塞的。多路复用有两种阻塞,select或poll调用之后,会阻塞进程,与第一种阻塞不同在于,此时的select不是等到socket数据全部到达再处理, 而是有了一部分数据就会调用用户进程来处理。如何知道有一部分数据到达了呢?监视的事情交给了内核,内核负责数据到达的处理。也可以理解为"非阻塞"吧。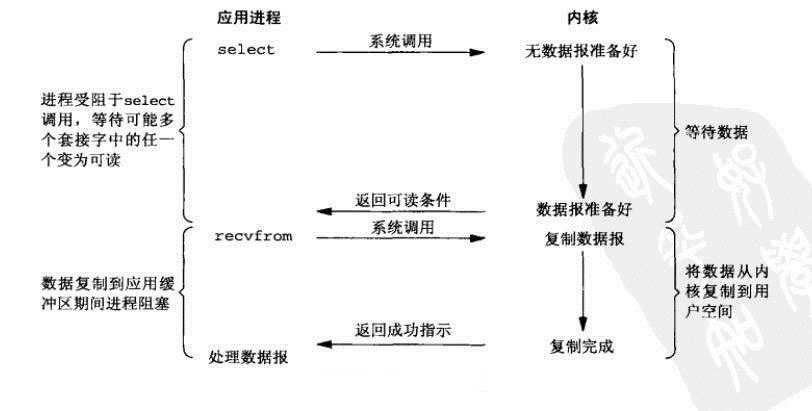
对于多路复用,也就是轮询多个socket。钓鱼的时候,我们雇了一个帮手,他可以同时抛下多个钓鱼竿,任何一杆的鱼一上钩,他就会拉杆。他只负责帮我们钓鱼,并不会帮我们处理,所以我们还得在一帮等着,等他把收杆。我们再处理鱼。多路复用既然可以处理多个I/O,也就带来了新的问题,多个I/O之间的顺序变得不确定了,当然也可以针对不同的编号。
多路复用的特点是通过一种机制一个进程能同时等待IO文件描述符,内核监视这些文件描述符(套接字描述符),其中的任意一个进入读就绪状态,select, poll,epoll函数就可以返回。对于监视的方式,又可以分为 select, poll, epoll三种方式。
了解了前面三种模式,在用户进程进行系统调用的时候,他们在等待数据到来的时候,处理的方式不一样,直接等待,轮询,select或poll轮询,第一个过程有的阻塞,有的不阻塞,有的可以阻塞又可以不阻塞。当时第二个过程都是阻塞的。从整个I/O过程来看,他们都是顺序执行的,因此可以归为同步模型(asynchronous)。都是进程主动向内核检查。
异步I/O(asynchronous I/O)
相对于同步I/O,异步I/O不是顺序执行。用户进程进行aio_read系统调用之后,无论内核数据是否准备好,都会直接返回给用户进程,然后用户态进程可以去做别的事情。等到socket数据准备好了,内核直接复制数据给进程,然后从内核向进程发送通知。I/O两个阶段,进程都是非阻塞的。
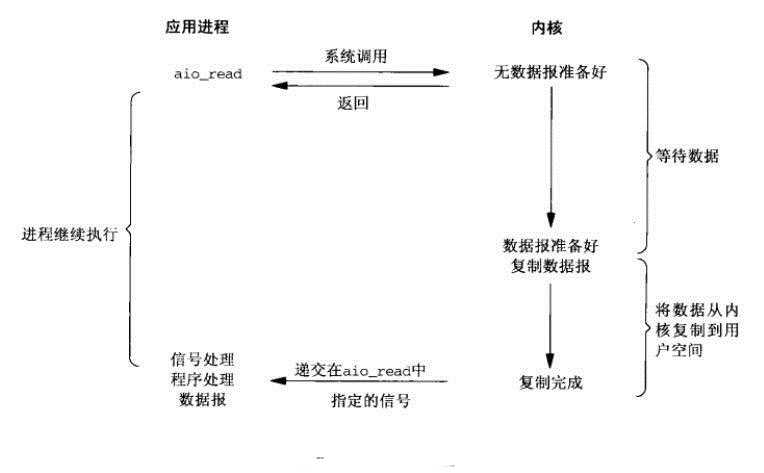
比之前的钓鱼方式不一样,这一次我们雇了一个钓鱼高手。他不仅会钓鱼,还会在鱼上钩之后给我们发短信,通知我们鱼已经准备好了。我们只要委托他去抛竿,然后就能跑去干别的事情了,直到他的短信。我们再回来处理已经上岸的鱼。
同步和异步的区别
通过对上述几种模型的讨论,需要区分阻塞和非阻塞,同步和异步。他们其实是两组概念。区别前一组比较容易,后一种往往容易和前面混合。在我看来,所谓同步就是在整个I/O过程。尤其是拷贝数据的过程是阻塞进程的,并且都是应用进程态去检查内核态。而异步则是整个过程I/O过程用户进程都是非阻塞的,并且当拷贝数据的时是由内核发送通知给用户进程。

对于同步模型,主要是第一阶段处理方法不一样。而异步模型,两个阶段都不一样。这里我们忽略了信号驱动模式。这几个名词还是容易让人迷惑,只有同步模型才考虑阻塞和非阻塞,因为异步肯定是非阻塞,异步非阻塞的说法感觉画蛇添足。
Select 模型
同步模型中,使用多路复用I/O可以提高服务器的性能。
在多路复用的模型中,比较常用的有select模型和poll模型。这两个都是系统接口,由操作系统提供。当然,Python的select模块进行了更高级的封装。select与poll的底层原理都差不多。千呼万唤始出来,本文的重点select模型。
1.select 原理
网络通信被Unix系统抽象为文件的读写,通常是一个设备,由设备驱动程序提供,驱动可以知道自身的数据是否可用。支持阻塞操作的设备驱动通常会实现一组自身的等待队列,如读/写等待队列用于支持上层(用户层)所需的block或non-block操作。设备的文件的资源如果可用(可读或者可写)则会通知进程,反之则会让进程睡眠,等到数据到来可用的时候,再唤醒进程。
这些设备的文件描述符被放在一个数组中,然后select调用的时候遍历这个数组,如果对于的文件描述符可读则会返回改文件描述符。当遍历结束之后,如果仍然没有一个可用设备文件描述符,select让用户进程则会睡眠,直到等待资源可用的时候在唤醒,遍历之前那个监视的数组。每次遍历都是线性的。
2.select 回显服务器
select涉及系统调用和操作系统相关的知识,因此单从字面上理解其原理还是比较乏味。用代码来演示最好不过了。使用python的select模块很容易写出下面一个回显服务器:
1 import select 2 import socket 3 import sys 4 5 HOST = ‘localhost‘ 6 PORT = 5000 7 BUFFER_SIZE = 1024 8 9 server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 10 server.bind((HOST, PORT)) 11 server.listen(5) 12 13 inputs = [server, sys.stdin] 14 running = True 15 16 while True: 17 try: 18 # 调用 select 函数,阻塞等待 19 readable, writeable, exceptional = select.select(inputs, [], []) 20 except select.error, e: 21 break 22 23 # 数据抵达,循环 24 for sock in readable: 25 # 建立连接 26 if sock == server: 27 conn, addr = server.accept() 28 # select 监听的socket 29 inputs.append(conn) 30 elif sock == sys.stdin: 31 junk = sys.stdin.readlines() 32 running = False 33 else: 34 try: 35 # 读取客户端连接发送的数据 36 data = sock.recv(BUFFER_SIZE) 37 if data: 38 sock.send(data) 39 if data.endswith(‘\r\n\r\n‘): 40 # 移除select监听的socket 41 inputs.remove(sock) 42 sock.close() 43 else: 44 # 移除select监听的socket 45 inputs.remove(sock) 46 sock.close() 47 except socket.error, e: 48 inputs.remove(sock) 49 50 server.close()
运行上述代码,使用curl访问http://localhost:5000,即可看命令行返回请求的HTTP request信息。
下面详细解析上述代码的原理。
1 server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 2 server.bind((HOST, PORT)) 3 server.listen(5)
上述代码使用socket初始化一个TCP套接字,并绑定主机地址和端口,然后设置服务器监听。
1 inputs = [server, sys.stdin]
这里定义了一个需要select监听的列表,列表里面是需要监听的对象(等于系统监听的文件描述符)。这里监听socket套接字和用户的输入。
然后代码进行一个服务器无线循环。
1 try: 2 # 调用 select 函数,阻塞等待 3 readable, writeable, exceptional = select.select(inputs, [], []) 4 except select.error, e: 5 break
调用了select函数,开始循环遍历监听传入的列表inputs。如果没有curl服务器,此时没有建立tcp客户端连接,因此改列表内的对象都是数据资源不可用。因此select阻塞不返回。
客户端输入curl http://localhost:5000之后,一个套接字通信开始,此时input中的第一个对象server由不可用变成可用。因此select函数调用返回,此时的readable有一个套接字对象(文件描述符可读)。
1 for sock in readable: 2 # 建立连接 3 if sock == server: 4 conn, addr = server.accept() 5 # select 监听的socket 6 inputs.append(conn)
select返回之后,接下来遍历可读的文件对象,此时的可读中只有一个套接字连接,调用套接字的accept()方法建立TCP三次握手的连接,然后把该连接对象追加到inputs监视列表中,表示我们要监视该连接是否有数据IO操作。
由于此时readable只有一个可用的对象,因此遍历结束。再回到主循环,再次调用select,此时调用的时候,不仅会遍历监视是否有新的连接需要建立,还是监视刚才追加的连接。如果curl的数据到了,select再返回到readable,此时在进行for循环。如果没有新的套接字,将会执行下面的代码:
1 try: 2 # 读取客户端连接发送的数据 3 data = sock.recv(BUFFER_SIZE) 4 if data: 5 sock.send(data) 6 if data.endswith(‘\r\n\r\n‘): 7 # 移除select监听的socket 8 inputs.remove(sock) 9 sock.close() 10 else: 11 # 移除select监听的socket 12 inputs.remove(sock) 13 sock.close() 14 except socket.error, e: 15 inputs.remove(sock)
通过套接字连接调用recv函数,获取客户端发送的数据,当数据传输完毕,再把监视的inputs列表中除去该连接。然后关闭连接。
整个网络交互过程就是如此,当然这里如果用户在命令行中输入中断,inputs列表中监视的sys.stdin也会让select返回,最后也会执行下面的代码:
1 elif sock == sys.stdin: 2 junk = sys.stdin.readlines() 3 running = False
有人可能有疑问,在程序处理sock连接的是时候,假设又输入了curl对服务器请求,将会怎么办?此时毫无疑问,inputs里面的server套接字会变成可用。等现在的for循环处理完毕,此时select调用就会返回server。如果inputs里面还有上一个过程的conn连接,那么也会循环遍历inputs的时候,再一次针对新的套接字accept到inputs列表进行监视,然后继续循环处理之前的conn连接。如此有条不紊的进行,直到for循环结束,进入主循环调用select。
任何时候,inputs监听的对象有数据,下一次调用select的时候,就会繁返回readable,只要返回,就会对readable进行for循环,直到for循环结束在进行下一次select。
主要注意,套接字建立连接是一次IO,连接的数据抵达也是一次IO。
3.select的不足
尽管select用起来挺爽,跨平台的特性。但是select还是存在一些问题。
select需要遍历监视的文件描述符,并且这个描述符的数组还有最大的限制。随着文件描述符数量的增长,用户态和内核的地址空间的复制所引发的开销也会线性增长。即使监视的文件描述符长时间不活跃了,select还是会线性扫描。
为了解决这些问题,操作系统又提供了poll方案,但是poll的模型和select大致相当,只是改变了一些限制。目前Linux最先进的方式是epoll模型。
许多高性能的软件如nginx, nodejs都是基于epoll进行的异步。
1 import socket 2 import select 3 sk=socket.socket() 4 sk.bind(("127.0.0.1",8800)) 5 sk.listen(5) 6 sk.setblocking(False) 7 inputs=[sk,] 8 9 while True: # [sk, conn, conn, conn] 10 r,w,e=select.select(inputs,[],[]) # 原理就是通过 select 来监听多个 socket 对象,只要如果所有对象都没有接收到信息,那么就 阻塞 在这里 11 # 如果有 socket 对象接受到了信息,就把他们 放到一个新的列表 r 中 12 # 将 r 中的每一个对象拿出来,判断它是 服务端用来创建与客户端连接的 socket 对象还是,和client接收、发送信息的队形 13 # 通过判断他们不同的身份来进行不同的操作(创建与新的 client 连接的通道,或者是与 已经存在的 client 进行通信) 14 15 # r = [sk, conn, conn] 16 print(len(r)) 17 18 for obj in r: 19 if obj==sk: 20 conn,add=obj.accept() 21 print("conn:",conn) 22 inputs.append(conn) 23 else: 24 25 data_byte=obj.recv(1024) 26 print(str(data_byte,‘utf8‘)) 27 if not data_byte: 28 inputs.remove(obj) 29 continue 30 inp=input(‘回答%s: >>>‘%inputs.index(obj)) 31 obj.sendall(bytes(inp,‘utf8‘)) 32 33 print(‘>>‘,r)
标签:orm 网络通信 bind size 三次握手 try 操作 定义 编号
原文地址:http://www.cnblogs.com/alwaysInMe/p/7219511.html