标签:运算 没有 拷贝 修改环境变量 com sla 源文件 布尔 环境
一、模块
1、标准库
不需要安装,直接调入使用的模块。
import sys模块:
import sys print(sys.path) #打印环境变量绝对路径 print(sys.argv) #打印当前脚本相对路径
打印脚本第二个参数:print(sys.argv [2])
import os 模块:
import os
# cmd_res=os.system("dir") #只执行命令,不保存结果
cmd_res=os.popen("dir").read() #执行命令,且保存结果
print("--->",cmd_res)
os.mkdir("new_dir") #在当前目录下创建一个新目录
2、第三方模块
第三方模块是需要安装的模块,当模块没有在荡秋千路径下时,程序运行出错。解决方法:(1)修改环境变量;(2)将模块拷贝到当前目录。
第三方模块的使用:新建一个登陆程序login.py,在同一目录下创建另一个程序reference.py,写入语句:import login,运行程序即可调用login模块。
二、pyc是什么?
一些解释性语言可以通过解释器的优化来对程序作出翻译时对整个程序作出优化,从而在效率上超过编译语言,如Java。当在命令行中输入python hello.py时,其实是激活python解释器,告诉它,你要开始工作了,但在“解释”之前执行的第一项工作和Java一样,是编译:
Java执行语句:JavaC hello.java
运行结果:java hello
(1)当Python在执行命令时,先将编译的结果保存在位于内存中的PyCodeObject中,当程序运行结束后,Python解释器则将PyCodeObject写回到pyc文件中。
(2)Python程序第二次执行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则重复以上过程。
因此,pyc文件其实是PyCodeObject的一种持久化保存方式。
(3)但如果Python程序被改动时问题来了》》》其实在每次运行程序时,Python是先检测有没有此文件,如果有,再检测pyc与源文件的更新时间哪个更新,若源代码文件时间更新,则重新执行(1)。
三、数据类型
1、数字:整型、浮点型
int(整型)、long(长整型)、float(浮点型)、complex(复数)
科学计数法:78.6E4=78.6*10**4=786000
2、布尔型(True、False)
三元运算:result= 值1 if 条件 else 值2
即如果条件为真:result= 值1,如果条件为假:result= 值2 。
例:a,b,c=2,5,3
d=a if a>b else c
四、数据类型转换
在Python3 中二进制统一用bytes类型表示,不会以任意隐式的方式混用str和bytes。因此,不能拼接字符窜和字节包,两者不能互相操作、互相搜索。

str与bytes之间的转换:
msg="螳螂捕蝉" print(msg) print(msg.encode(encoding="utf-8")) #字符串编码为二进制 print(msg.encode(encoding="utf-8").decode(encoding="utf-8"))#二进制转换为字符串
运行结果:
螳螂捕蝉 b‘\xe8\x9e\xb3\xe8\x9e\x82\xe6\x8d\x95\xe8\x9d\x89‘ 螳螂捕蝉
五、字符串操作
字符编码与转码:在整个过程中unicode作为一个中间件执行编码与解码命令。
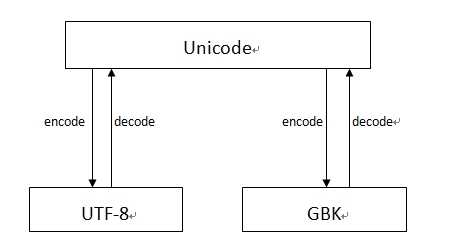
1、GBK与UTF-8之间的转换:
# -*- coding:utf-8 -*-
s="你好"
s_gbk=s.encode("gbk")#编码
print(s)
print(s_gbk)
print("-----gbk转换为utf-8-----")
gbk_to_utf8=s_gbk.decode("gbk").encode("utf-8")
print("utf8",gbk_to_utf8)
运行结果:
你好 b‘\xc4\xe3\xba\xc3‘ -----gbk转换为utf-8----- utf8 b‘\xe4\xbd\xa0\xe5\xa5\xbd‘
2、示例:
# -*- coding:utf-8 -*-
s="好好学习" #注意:此时s仍是系统默认的unicode形式,并不受文头 coding:utf-8 的影响
s_to_gb2312=s.encode("gb2312") #所以可以直接编码为gb2312
gb2312_to_utf8=s_to_gb2312.decode("gb2312").encode("utf-8") #gb2312转换为UTF-8
gb2312_to_str=s_to_gb2312.decode("gb2312").encode("utf-8").decode("utf-8") #最终将utf-8转换为字符串输出
print(s)
print("gb2312",s_to_gb2312)
print("utf-8",gb2312_to_utf8)
print("str",gb2312_to_str)
运行结果:
好好学习 gb2312 b‘\xba\xc3\xba\xc3\xd1\xa7\xcf\xb0‘ utf-8 b‘\xe5\xa5\xbd\xe5\xa5\xbd\xe5\xad\xa6\xe4\xb9\xa0‘ str 好好学习
六、字符串操作
print(‘‘.join([‘1‘,‘2‘,‘3‘,‘4‘])) #字符串连接
s=str.maketrans("abcdefjk","12345678") #两组字符串一一对应
print("yank".translate(s)) #用数字代替表示字母
print(‘garden‘.replace(‘g‘,‘G‘,1)) #替换
print(‘gardedn‘.rfind(‘d‘)) #查找最右边的“d”的索引值
print(‘2+4+7+8‘.split("+")) #将“+”替换为“,”
print(‘2+3 \n +5+4‘.splitlines()) #将换行符用逗号填充
运行结果:
1234
y1n8
Garden
5
[‘2‘, ‘4‘, ‘7‘, ‘8‘]
[‘2+3 ‘, ‘ +5+4‘]
标签:运算 没有 拷贝 修改环境变量 com sla 源文件 布尔 环境
原文地址:http://www.cnblogs.com/yanlin-10/p/7222124.html