标签:page parse his tor list 一个 png 网页 port
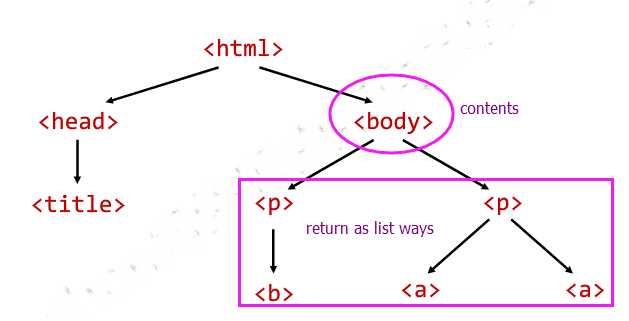
1. HTML的基本格式
<html> <head> <title> This is a python demo page </title> </head> <body> <p class="title"> <b> The demo python introduces several python courses. </b> </p> <p class="course"> Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> Basic Python </a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2"> Advanced Python </a>
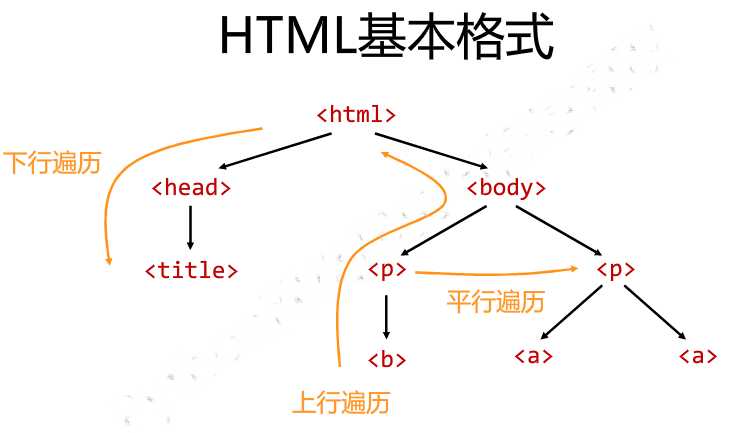
1. 下行游历。
1.1 contents
import requests # r = requests.get("http://python123.io/ws/demo.html") demo = r.text from bs4 import BeautifulSoup soup = BeautifulSoup(demo,"html.parser") print(soup.body.contents) # 返回所有子节点的信息。。 print(soup.body.contents[1]) # 以列表的形势,因此可以进行列表的处理
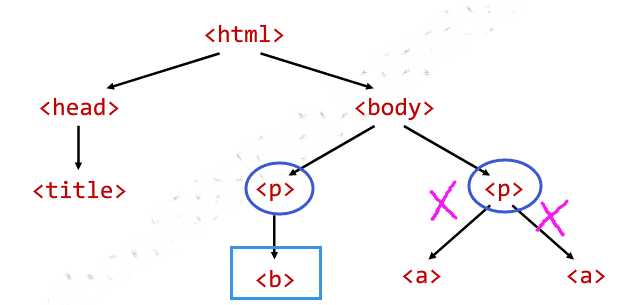
print(soup.p.contents) # 只返回标签的全部子第一个信息
1.2 气死我了连续两次都没保存上。。。。。
children and descendants
print(soup.body.children) # 仅循环 # <list_iterator object at 0x01383D10> print(soup.body.descendants) # 仅循环 # <generator object descendants at 0x024B42A0> for i in soup.body.children: print(i) for j in soup.body.descendants: print(j)
2. 上行游历

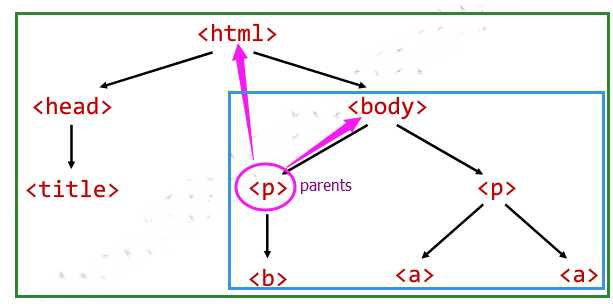
2.1 parent
print(soup.a.parents)print(soup.p.parent)
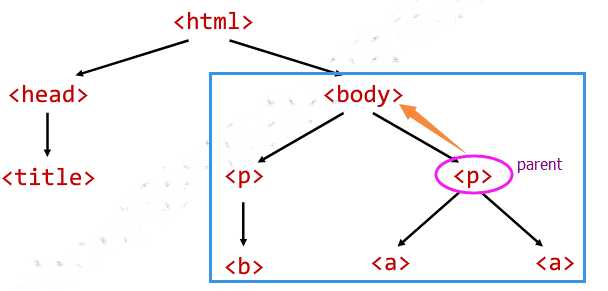
2.2 parents
for i in soup.p.parents: print(i.prettify())
3. 平行游历(仅同一父亲节点下)

标签:page parse his tor list 一个 png 网页 port
原文地址:http://www.cnblogs.com/hanbb/p/7223375.html