标签:append 线程 src 导致 线程锁 tool oba threading 结果
GIL(全局解释器锁)
GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念,是为了实现不同线程对共享资源访问的互斥,才引入了GIL
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
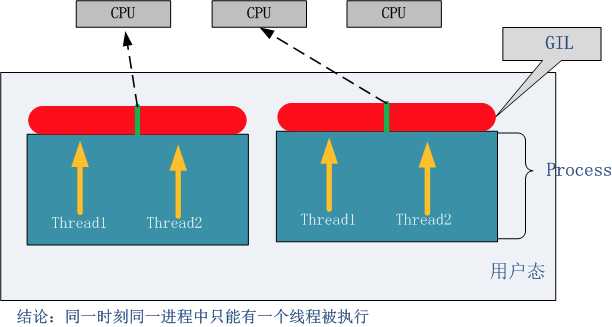
python对于计算密集型的任务开多线程的效率甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
GIL原理图
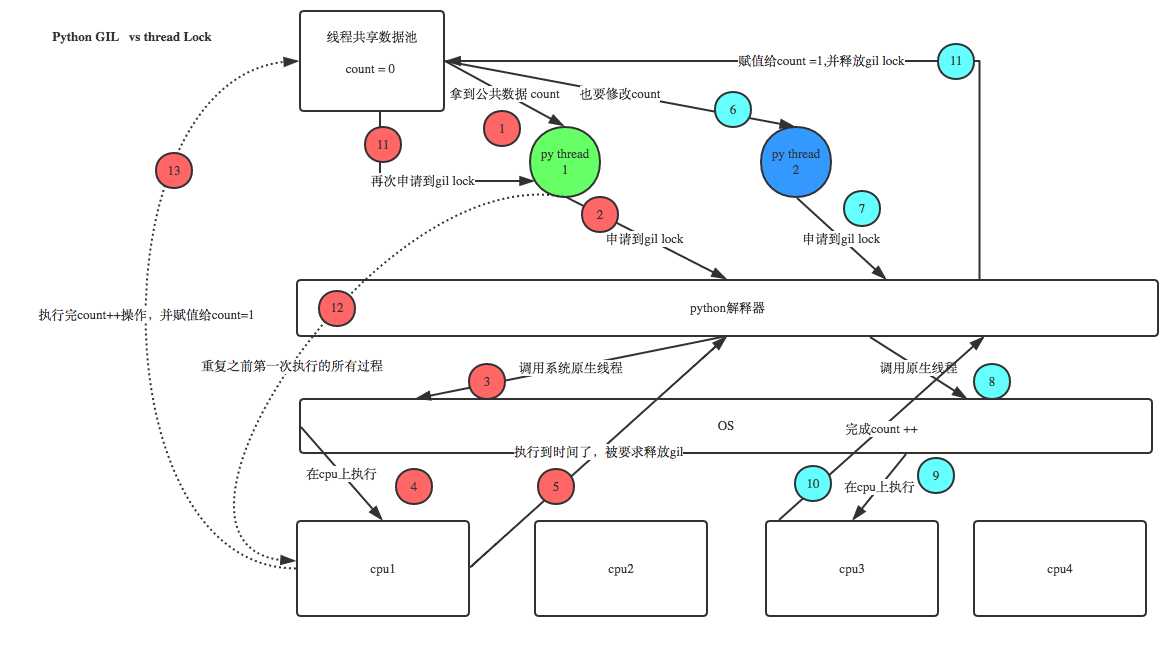
计算密集型:结果肯定是100,因为每一次start结果就已经出来了,所以第二个线程肯定是通过调用第一个线程的count值进行计算的

1 def sub():
2 global count
3
4 ‘‘‘线程的公共数据 下‘‘‘
5 temp=count
6 count=temp+1
7 ‘‘‘线程的公共数据 上‘‘‘
8
9 time.sleep(2)
10 count=0
11
12 l=[]
13 for i in range(100):
14 t=threading.Thread(target=sub,args=())
15 t.start() #每一次线程激活,申请一次gillock
16 l.append(t)
17 for t in l:
18 t.join()
19 print(count)
io密集型:当第一个线程开始start的时候,由于sleep了0.001秒,这0.001秒对于人而言很短,但是对于cpu而言,这0.001秒已经做了很多的事情了,在这里cpu做的事情就是或许已经start了100个线程,所以导致大多数的线程调用的count值还是0,即temp=0,只有少数的线程完成了count=temp+1的操作,所以输出的count结果不确定,可能是7、8、9,也可能是10几。
1 def sub():
2 global count
3
4 ‘‘‘线程的公共数据 下‘‘‘
5 temp=count
6 time.sleep(0.001) #大量的io操作
7 count=temp+1
8 ‘‘‘线程的公共数据 上‘‘‘
9
10 time.sleep(2)
11 count=0
12
13 l=[]
14 for i in range(100):
15 t=threading.Thread(target=sub,args=())
16 t.start()
17 l.append(t)
18 for t in l:
19 t.join()
20 print(count)
注意以下的锁都是多线程提供的锁机制,与python解释器引入的gil概念无关
互斥锁(同步锁)
互斥锁是用来解决上述的io密集型场景产生的计算错误,即目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据。
1 def sub():
2 global count
3 lock.acquire() #上锁,第一个线程如果申请到锁,会在执行公共数据的过程中持续阻塞后续线程
4 #即后续第二个或其他线程依次来了发现已经被上锁,只能等待第一个线程释放锁
5 #当第一个线程将锁释放,后续的线程会进行争抢
6
7 ‘‘‘线程的公共数据 下‘‘‘
8 temp=count
9 time.sleep(0.001)
10 count=temp+1
11 ‘‘‘线程的公共数据 上‘‘‘
12
13 lock.release() #释放锁
14 time.sleep(2)
15 count=0
16
17 l=[]
18 lock=threading.Lock() #将锁内的代码串行化
19 for i in range(100):
20 t=threading.Thread(target=sub,args=())
21 t.start()
22 l.append(t)
23 for t in l:
24 t.join()
25 print(count)
死锁
保护不同的数据就应该加不同的锁。
所以当有多个互斥锁存在的时候,可能会导致死锁,死锁原理如下:
1 import threading
2 import time
3 def foo():
4 lockA.acquire()
5 print(‘func foo ClockA lock‘)
6 lockB.acquire()
7 print(‘func foo ClockB lock‘)
8 lockB.release()
9 lockA.release()
10
11 def bar():
12
13 lockB.acquire()
14 print(‘func bar ClockB lock‘)
15 time.sleep(2) # 模拟io或者其他操作,第一个线程执行到这,在这个时候,lockA会被第二个进程占用
16 # 所以第一个进程无法进行后续操作,只能等待lockA锁的释放
17 lockA.acquire()
18 print(‘func bar ClockA lock‘)
19 lockB.release()
20 lockA.release()
21
22 def run():
23 foo()
24 bar()
25
26 lockA=threading.Lock()
27 lockB=threading.Lock()
28 for i in range(10):
29 t=threading.Thread(target=run,args=())
30 t.start()
31
32 输出结果:只有四行,因为产生了死锁阻断了
33 func foo ClockA lock
34 func foo ClockB lock
35 func bar ClockB lock
36 func foo ClockA lock
递归锁(重要)
解决死锁
1 import threading
2 import time
3 def foo():
4 rlock.acquire()
5 print(‘func foo ClockA lock‘)
6 rlock.acquire()
7 print(‘func foo ClockB lock‘)
8 rlock.release()
9 rlock.release()
10
11 def bar():
12 rlock.acquire()
13 print(‘func bar ClockB lock‘)
14 time.sleep(2)
15 rlock.acquire()
16 print(‘func bar ClockA lock‘)
17 rlock.release()
18 rlock.release()
19
20
21 def run():
22 foo()
23 bar()
24
25 rlock=threading.RLock() #RLock本身有一个计数器,如果碰到acquire,那么计数器+1
26 #如果计数器大于0,那么其他线程无法查收,如果碰到release,计数器-1
27
28 for i in range(10):
29 t=threading.Thread(target=run,args=())
30 t.start()
Semaphore(信号量)
实际上也是一种锁,该锁用于限制线程的并发量
以下代码在sleep两秒后会打印出100个ok
1 import threading
2 import time
3 def foo():
4 time.sleep(2)
5 print(‘ok‘)
6
7 for i in range(100):
8 t=threading.Thread(target=foo,args=())
9 t.start()
每2秒打印5次ok
1 import threading
2 import time
3 sem=threading.Semaphore(5)
4 def foo():
5 sem.acquire()
6 time.sleep(2)
7 print(‘ok‘)
8 sem.release()
9
10 for i in range(100):
11 t=threading.Thread(target=foo,args=())
12 t.start()
标签:append 线程 src 导致 线程锁 tool oba threading 结果
原文地址:http://www.cnblogs.com/fengshuihuan/p/7229807.html