标签:需要 ima 缓存命中 模拟 比例 情况 开始 memory 理论
原文地址:
http://flychao88.iteye.com/blog/1977653
http://blog.csdn.net/cjfeii/article/details/47259519
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是"如果数据最近被访问过,那么将来被访问的几率也更高"。
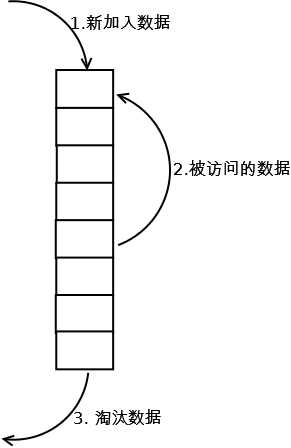
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
可以通过调整样本数量来取得LRU置换算法的速度或是精确性方面的优势。
Redis不采用真正的LRU实现的原因是为了节约内存使用。虽然不是真正的LRU实现,但是它们在应用上几乎是等价的。下图是Redis的近似LRU实现和理论LRU实现的对比:

测试开始首先在Redis中导入一定数目的key,然后从第一个key依次访问到最后一个key,因此根据LRU算法第一个被访问的key应该最新被置换,之后再增加50%数目的key,导致50%的老的key被替换出去。
在上图中你可以看到三种类型的点,组成三种不同的区域:
理论LRU实现就像我们期待的那样,最旧的50%数目的key被置换出去,Redis的LRU将一定比例的旧key置换出去。
可以看到在样本数为5的情况下,Redis3.0要比Redis2.8做的好很多,Redis2.8中有很多应该被置换出去的数据没有置换出去。在样本数为10的情况下,Redis3.0很接近真正的LRU实现。
LRU是一个预测未来我们会访问哪些数据的模型,如果我们访问数据的形式接近我们预想——幂律,那么近似LRU算法实现将能处理的很好。
在模拟测试中我们可以发现,在幂律访问模式下,理论LRU和Redis近似LRU的差距很小或者就不存在差距。
如果你将maxmemory-samples设置为10,那么Redis将会增加额外的CPU开销以保证接近真正的LRU性能,可以通过检查命中率来查看有什么不同。
通过CONFIG SET maxmemory-samples <count>动态调整样本数大小,做一些测试验证你的猜想。
标签:需要 ima 缓存命中 模拟 比例 情况 开始 memory 理论
原文地址:http://www.cnblogs.com/xiaolang8762400/p/7231756.html