标签:character blog 语句 自动 选项 int logs 默认 creat
Linux: 安装
--yum -y install mariadb mariadb-server
OR
--yum -y install mysql mysql-server
启动
--service mysqld start 开启
--chkconfig mysqld on 设置开机自动启动
--systemctl start mariadb
--systemctl enable mariadb
查看
--ps aux | grep mysqld 查看进程
--netstat -an | grep 3306 查看端口
设置密码
--mysqladmin -uroot password ‘xxxxx‘ 设置初始密码,初始密码为空因此-p选项没用
--mysqladmin -uroot -pxxxx password ‘xxxxxxxxxx‘ 修改root用户密码
登录
-- mysql #本地登录,默认用户root,空密码,用户为root@127.0.0.1
-- mysql -uroot -p1234 #本地登录,指定用户名和密码,用户为root@127.0.0.1
-- mysql -uroot -p1234 -h 192.168.31.95 #远程登录,用户为root@192.168.31.95
数据库由字段和记录组成
SQL语句是结构化语句
规范:
1、不区分大小写,命令建议大写
2、以分号作为结束符号
3、注释-- 多行注释/* */
数据库的操作
SHOW DATABASES; --显示已有的数据库

CREATE DATABASE 数据库名称(小写) CHARACTER SET utf8; --创建数据库,指定数据库字符集


DROP DATABASE databasename; --删除数据库
ALTER DATABASE databasename CHARACTER SET xxx; --修改数据库的字符集
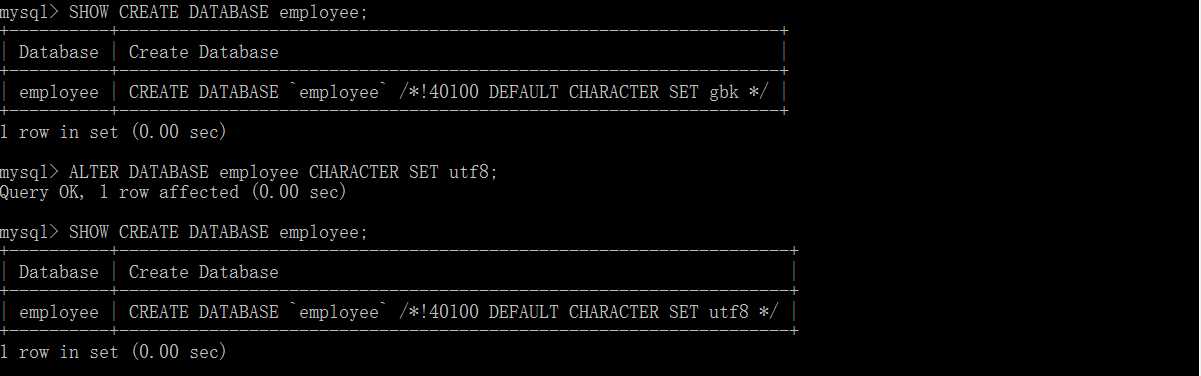
SHOW CREATE DATABASE databasename; --查看创建的数据库信息
DROP DATABASE databasename; --删除某一个数据库
USE databasename; --使用某一个数据库,切换到数据库目录下

创建表
数据表的操作
CREATE TABLE table_name(
字段名 字段数据类型[约束],
字段名 字段数据类型[约束],
字段名 字段数据类型[约束],
字段名 字段数据类型[约束],
)
主键:非空且唯一
/* 约束:
primary key (非空且唯一) :能够唯一区分出当前记录的字段称为主键!
unique
not null
auto_increment :用于主键字段,主键字段必须是数字类型,自增 */

查看表信息
DESC table_name; --查看表结构

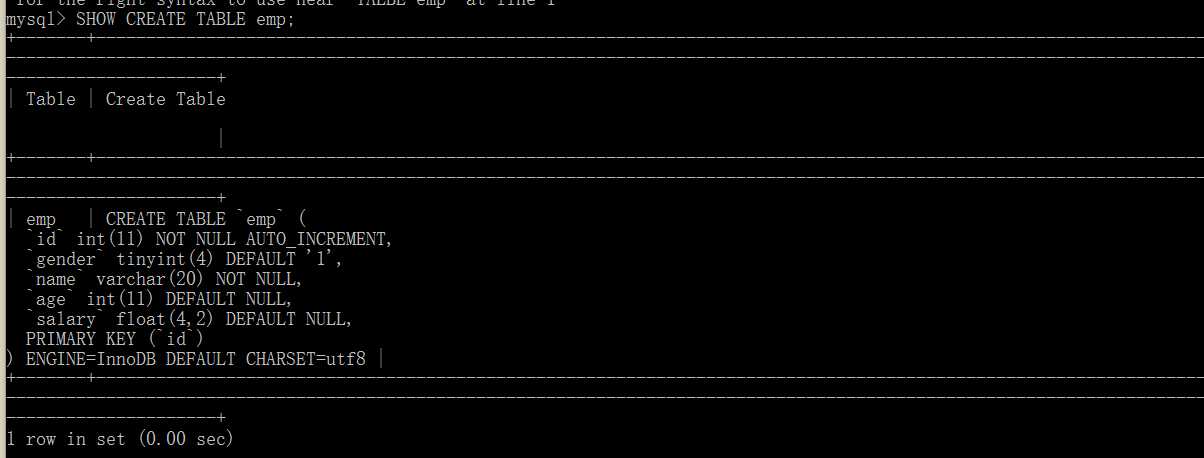
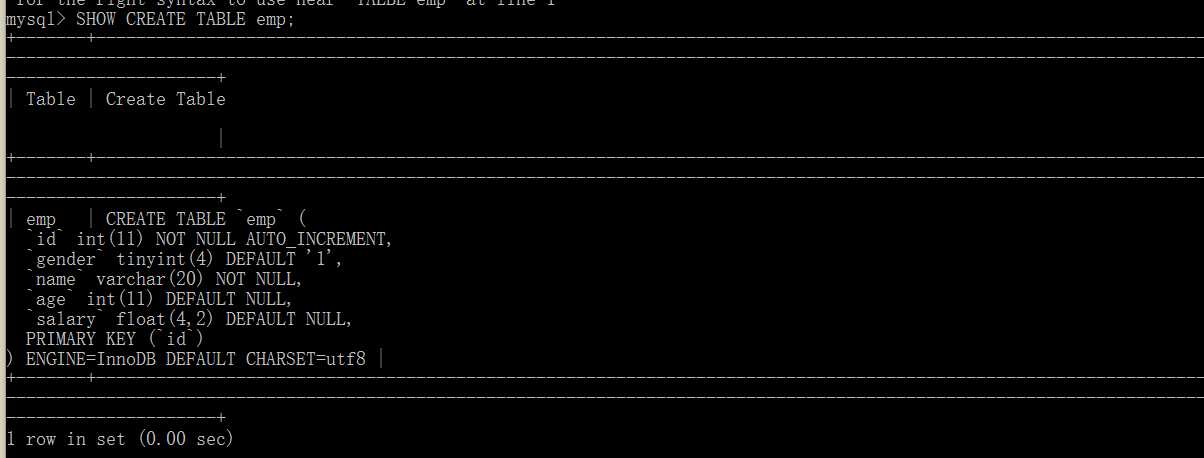
SHOW CREATE table_name; --查看创建表信息
SHOW TABLES; --查看数据库中的表

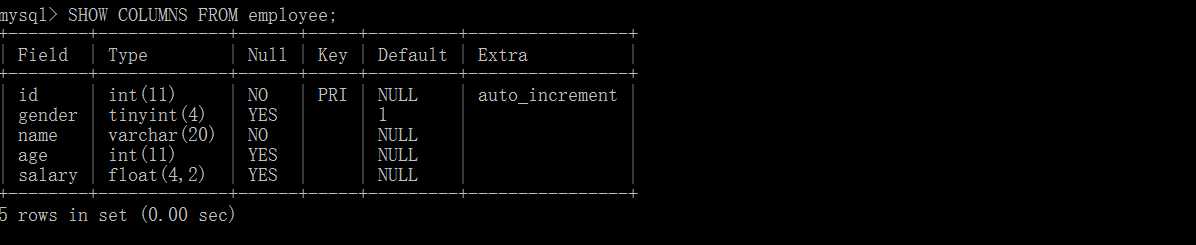
SHOW COLUMNS FROM table_name; --查看表列结构
修改表结构
单次单项操作
ALTER TABLE table_name ADD [column] 列名 类型 [约束条件] [FIRST | AFTER] 字段名; --向表中添加列
单次多项操作
ALTER TABLE table_name ADD [column] 列名 类型 [约束条件] [FIRST | AFTER] 字段名,
ADD [column] 列名 类型 [约束条件] [FIRST | AFTER] 字段名,
ADD [column] 列名 类型 [约束条件] [FIRST | AFTER] 字段名,
ADD [column] 列名 类型 [约束条件] [FIRST | AFTER] 字段名;
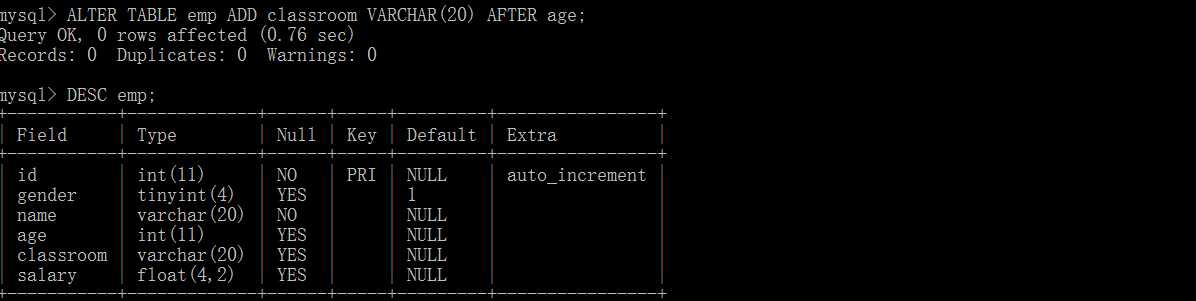
ALTER TABLE table_name MODIFY 列名 类型 [约束条件] [FIRST | AFTER] 字段名; --改变列的数据类型
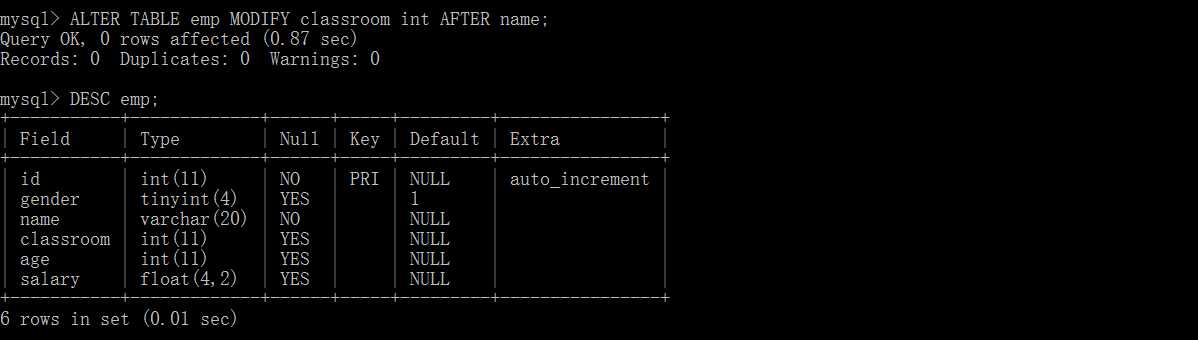
ALTER TABLE table_name DROP [column] 列名; --删除某列
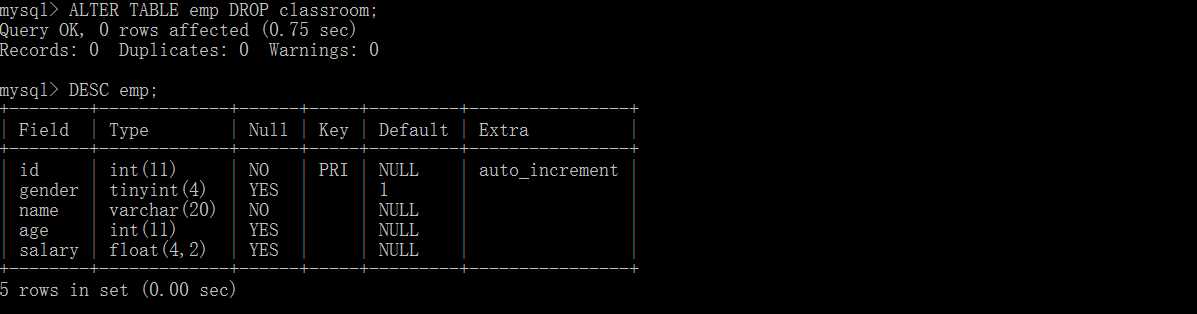
ALTER TABLE table_name CHANGE 列名 新列名 类型 [约束] [FIRST | AFTER] 字段名; --改变某列的名称
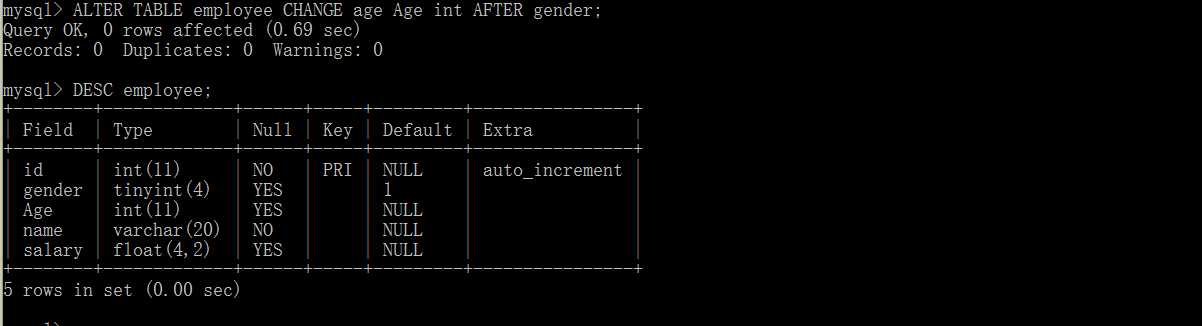
RENAME TABLE 表名 to 新表名; --修改表名称

ALTER TABLE table_name CHARACTER SET xxx; --修改表字符集
DROP TABLE table_name; --删除表
增加表记录
插入一条记录
INSERT [INTO] table_name (field1,filed2,......) VALUES (value1,value2,.......);
插入多条记录
INSERT [INTO] table_name (field1,field2,......) VALUES (value1,value2,......),
(value1,value2,......),
(value1,value2,......),
........;
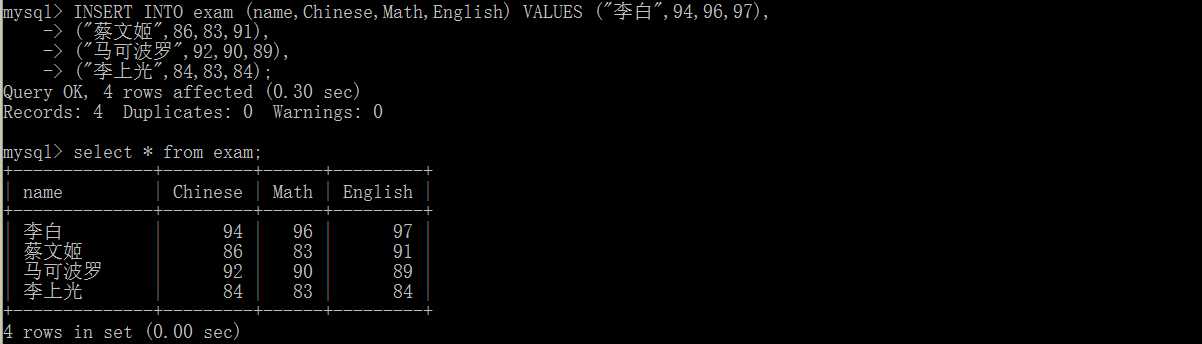
修改表记录
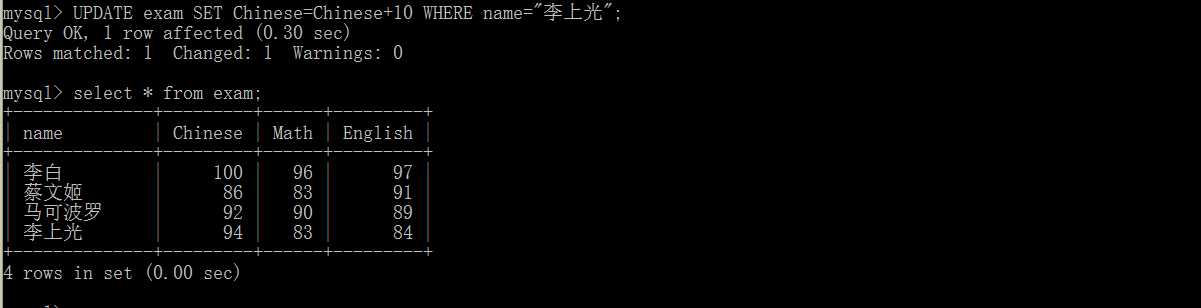
UPDATE table_name SET field1=value1,field2=value2,...... [where]

删除表记录
DELETE FROM table_name [WHERE];
如果不跟WHERE,DELETE语句会删除整张表中的数据,只能删除表内容而不能删除表
TRUNCATE TABLE table_name 也可以删除表中的所有数据,首先摧毁表再创建新表,此种方式不能恢复

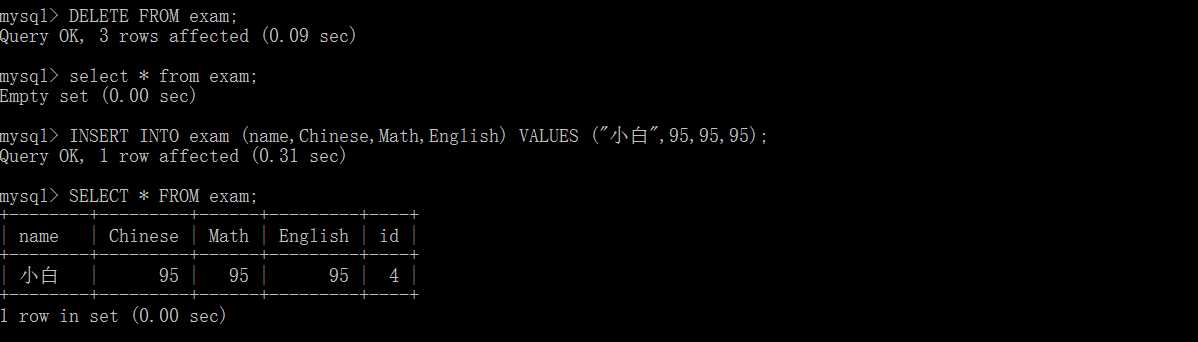

查询表记录
SELECT [DISTINCT] * | field1,field2,...... FROM table_name; --查询显示表中信息
SELECT * FROM table_name; --查询显示表中所有信息
SELECT field1 [AS] 别名,field2 [AS] 别名...... FROM table_name;

使用WHERE子句进行过滤查询
WHERE子句中可以使用:
比较运算符:
> < >= <= != <>
between ... and ... 之间
in (80,90,100) 80 90 100
like "a%" 表示任意多个字符,alpha , abc都可以
如果是"a_"表示一个字符,只有ab , ac符合
逻辑运算符:
多个条件可以使用逻辑运算符 and or not

ORDER BY 排序
SELECT * | field1,field2,... FROM table_name ORDER BY field [ASC | DESC];
-- ASC 升序, DESC降序,其中ASC为默认值,ORDER BY 子句应位于SELECT语句的结尾

GROUP BY 分组查询
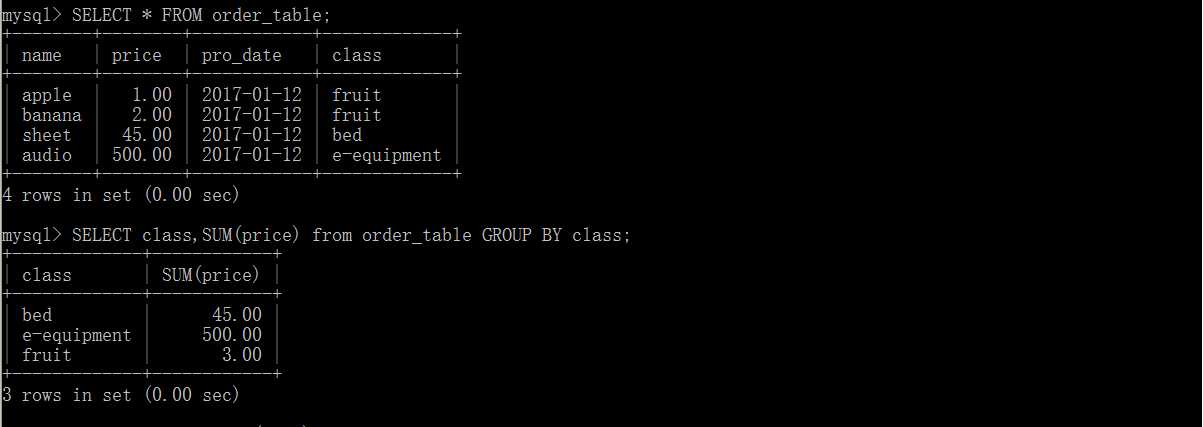
GROUP BY 子句其后可以接多个列名,也可以跟having子句,对GROUP BY 的结果进行筛选

HAVING和WHERE两者都可以对查询结果进行进一步的过滤,差别有:
1、WHERE语句只能用在分组之前的筛选,HAVING可以用在分组之后的筛选
2、使用WHERE的语句的地方可以用HAVING进行替换
3、HAVING中可以使用聚合函数,WHERE中不能
聚合函数
COUNT(列名):统计行的个数

SUM(列名):统计满足条件的行的内容和
SELECT SUM(字段) AS 别名, --多条SUM查询
SUM(字段) AS 别名,
...... FROM table_name;

AVG(列名):求平均值
MAX,MIN : 求最大值,最小值
SELECT MAX((ifnull(字段1,0)+ifnull(字段2,0)+......) FROM table_name; --null和所有的数计算都是null,所以需要用ifnull将null转换为0
标签:character blog 语句 自动 选项 int logs 默认 creat
原文地址:http://www.cnblogs.com/c491873412/p/7236209.html