标签:信息 width 枝叶 避免 src and 具体步骤 包含 情况
判定树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根节点。
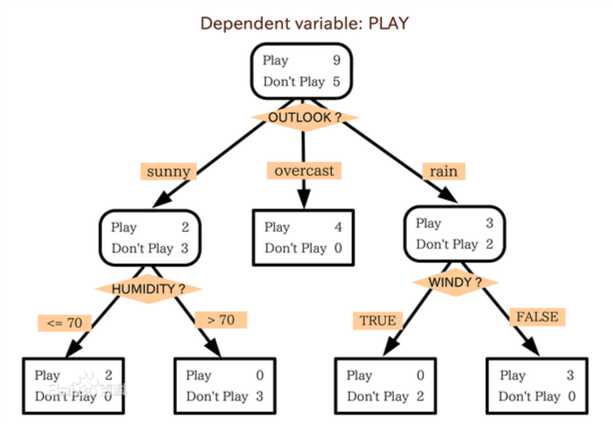
一个根据天气情况判断是否适宜户外运动的决策树示例:
熵(entropy)概念:
信息和抽象,如何度量?
1948年,香农提出了 ”信息熵(entropy)“的概念。
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常非常不确定的事情,或者 是我们一无所知的事情,需要了解大量信息==>信息量的度量就等于不确定性的多少。
比特(bit)来衡量信息的多少。
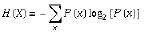
具体步骤与示例:
下表是一组信息:(包含age、income、是否student、credit_rating信用评级、Class:buys_computer是否买电脑)
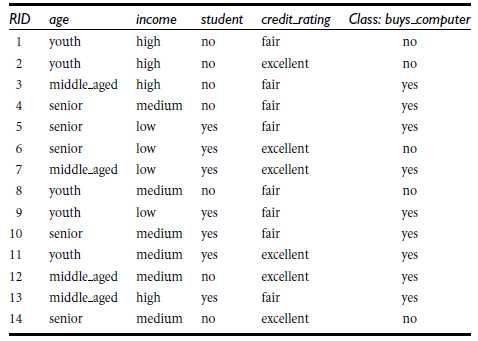
所以信息熵的取值在0~1之间。
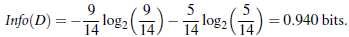
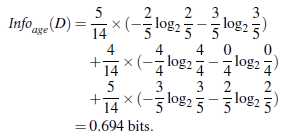
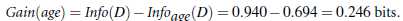
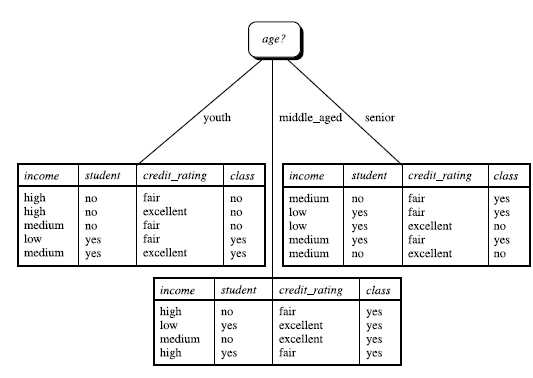
其余结点分类类似上述方法。
- 树以代表训练样本的单个结点开始(步骤1)。
- 如果样本都在同一个类,则该结点成为树叶,并用该类标号(步骤2 和3)。
- 否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性(步骤6)。该属性成为该结点的“测试”或“判定”属性(步骤7)。在算法的该版本中。
- 所有的属性都是分类的,即离散值。连续属性必须离散化。
- 对测试属性的每个已知的值,创建一个分枝,并据此划分样本(步骤8-10)。
- 算法使用同样的过程,递归地形成每个划分上的样本判定树。一旦一个属性出现在一个结点上,就不必该结点的任何后代上考虑它(步骤13)。
- 递归划分步骤仅当下列条件之一成立停止:
- (a) 给定结点的所有样本属于同一类(步骤2 和3)。
- (b) 没有剩余属性可以用来进一步划分样本(步骤4)。在此情况下,使用多数表决(步骤5)。
- 这涉及将给定的结点转换成树叶,并用样本中的多数所在的类标记它。替换地,可以存放结
- 点样本的类分布。
- (c) 分枝
- test_attribute = a i 没有样本(步骤11)。在这种情况下,以 samples 中的多数类
- 创建一个树叶(步骤12)
树剪枝叶(避免过拟合overfitting):
前置裁剪 在构建决策树的过程时,提前停止。
后置裁剪 决策树构建好后,然后才开始裁剪。
决策树的优点:
直观,便于理解,小规模数据集有效
决策树缺点:
处理连续变量不好
类别较多时,错误增加的比较快
可规模性一般
标签:信息 width 枝叶 避免 src and 具体步骤 包含 情况
原文地址:http://www.cnblogs.com/bahcelor/p/7239211.html