标签:sed max extra category not its 随机选择 随机化 bin
【本文转自】http://www.cnblogs.com/gaochundong/p/comparison_sorting_algorithms.html
比较排序(Comparison Sort)通过对数组中的元素进行比较来实现排序。
注:关于 Memory,如果算法为 "in place" 排序,则仅需要 O(1) 内存;有时对于额外的 O(log(n)) 内存也可以称为 "in place"。
注:Microsoft .NET Framework 中 Array.Sort 方法的实现使用了内省排序(Introspective Sort)算法。
Stable 与 Not Stable 的比较
稳定排序算法会将相等的元素值维持其相对次序。如果一个排序算法是稳定的,当有两个有相等的元素值 R 和 S,且在原本的列表中 R 出现在 S 之前,那么在排序过的列表中 R 也将会是在 S 之前。

O(n2) 与 O(n*logn) 的比较
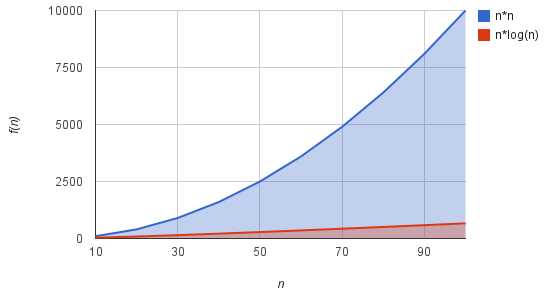
合并排序和堆排序在最坏情况下达到上界 O(n*logn),快速排序在平均情况下达到上界 O(n*logn)。对于比较排序算法,我们都能给出 n 个输入的数值,使算法以 Ω(n*logn) 时间运行。
注:有关算法复杂度,可参考文章《算法复杂度分析》。有关常用数据结构的复杂度,可参考文章《常用数据结构及复杂度》。
算法描述
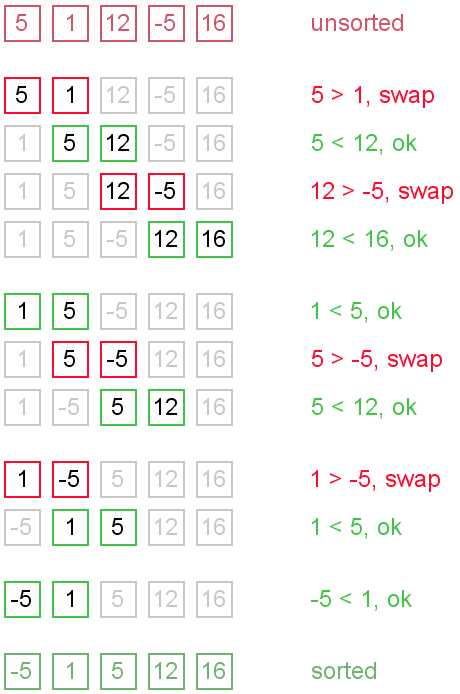
重复地比较要排序的数列,一次比较两个元素,如果后者较小则与前者交换元素。
算法复杂度
冒泡排序对 n 个元素需要 O(n2) 的比较次数,且可以原地排序。冒泡排序仅适用于对于含有较少元素的数列进行排序。
示例代码

1 class Program
2 {
3 static void Main(string[] args)
4 {
5 int[] unsorted = { 4, 1, 5, 2, 6, 3, 7, 9, 8 };
6
7 OptimizedBubbleSort(unsorted);
8
9 foreach (var key in unsorted)
10 {
11 Console.Write("{0} ", key);
12 }
13
14 Console.Read();
15 }
16
17 static void BubbleSort(int[] unsorted)
18 {
19 for (int i = 0; i < unsorted.Length; i++)
20 {
21 for (int j = 0; j < unsorted.Length - 1 - i; j++)
22 {
23 if (unsorted[j] > unsorted[j + 1])
24 {
25 int temp = unsorted[j];
26 unsorted[j] = unsorted[j + 1];
27 unsorted[j + 1] = temp;
28 }
29 }
30 }
31 }
32
33 static void OptimizedBubbleSort(int[] unsorted)
34 {
35 int exchange = unsorted.Length - 1;
36 while (exchange > 0)
37 {
38 int lastExchange = exchange;
39 exchange = 0;
40
41 for (int i = 0; i < lastExchange; i++)
42 {
43 if (unsorted[i] > unsorted[i + 1])
44 {
45 int temp = unsorted[i];
46 unsorted[i] = unsorted[i + 1];
47 unsorted[i + 1] = temp;
48
49 exchange = i;
50 }
51 }
52 }
53 }
54 }
算法描述
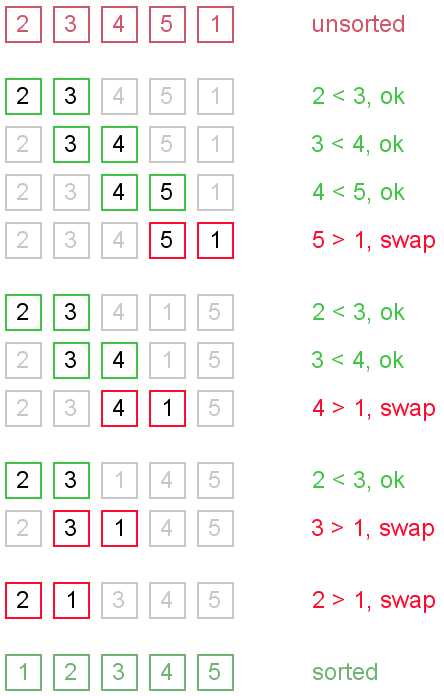
鸡尾酒排序,也就是双向冒泡排序(Bidirectional Bubble Sort),是冒泡排序的一种变形。此算法与冒泡排序的不同处在于排序时是以双向在序列中进行排序。如果序列中的大部分元素已经排序好时,可以得到比冒泡排序更好的性能。
算法复杂度
代码示例
1 class Program
2 {
3 static void Main(string[] args)
4 {
5 int[] unsorted = { 4, 1, 5, 2, 6, 3, 7, 9, 8 };
6
7 OptimizedCocktailSort(unsorted);
8
9 foreach (var key in unsorted)
10 {
11 Console.Write("{0} ", key);
12 }
13
14 Console.Read();
15 }
16
17 static void CocktailSort(int[] unsorted)
18 {
19 for (int i = 0; i < unsorted.Length / 2; i++)
20 {
21 // move the larger to right side
22 for (int j = i; j + 1 < unsorted.Length - i; j++)
23 {
24 if (unsorted[j] > unsorted[j + 1])
25 {
26 int temp = unsorted[j];
27 unsorted[j] = unsorted[j + 1];
28 unsorted[j + 1] = temp;
29 }
30 }
31
32 // move the smaller to left side
33 for (int j = unsorted.Length - i - 1; j > i; j--)
34 {
35 if (unsorted[j - 1] > unsorted[j])
36 {
37 int temp = unsorted[j - 1];
38 unsorted[j - 1] = unsorted[j];
39 unsorted[j] = temp;
40 }
41 }
42 }
43 }
44
45 static void OptimizedCocktailSort(int[] unsorted)
46 {
47 bool swapped = false;
48 int start = 0;
49 int end = unsorted.Length - 1;
50 do
51 {
52 swapped = false;
53
54 // move the larger to right side
55 for (int i = start; i < end; i++)
56 {
57 if (unsorted[i] > unsorted[i + 1])
58 {
59 int temp = unsorted[i];
60 unsorted[i] = unsorted[i + 1];
61 unsorted[i + 1] = temp;
62
63 swapped = true;
64 }
65 }
66
67 // we can exit the outer loop here if no swaps occurred.
68 if (!swapped) break;
69 swapped = false;
70 end = end - 1;
71
72 // move the smaller to left side
73 for (int j = end; j > start; j--)
74 {
75 if (unsorted[j - 1] > unsorted[j])
76 {
77 int temp = unsorted[j];
78 unsorted[j] = unsorted[j - 1];
79 unsorted[j - 1] = temp;
80
81 swapped = true;
82 }
83 }
84
85 start = start + 1;
86 }
87 while (swapped);
88 }
89 }
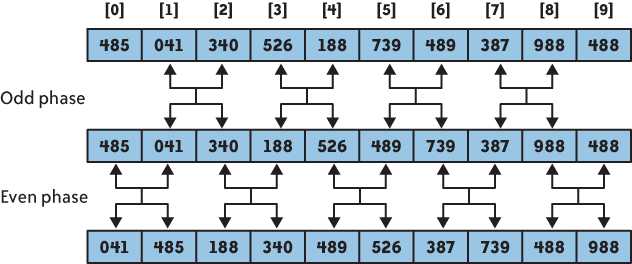
奇偶排序通过比较数组中相邻的(奇-偶)位置元素,如果该奇偶元素对是错误的顺序(前者大于后者),则交换元素。然后再针对所有的(偶-奇)位置元素进行比较。如此交替进行下去。
算法复杂度
代码示例
1 class Program
2 {
3 static void Main(string[] args)
4 {
5 int[] unsorted = { 4, 1, 5, 2, 6, 3, 7, 9, 8 };
6
7 OptimizedOddEvenSort(unsorted);
8
9 foreach (var key in unsorted)
10 {
11 Console.Write("{0} ", key);
12 }
13
14 Console.Read();
15 }
16
17 static void OddEvenSort(int[] unsorted)
18 {
19 for (int i = 0; i < unsorted.Length; ++i)
20 {
21 if (i % 2 > 0)
22 {
23 for (int j = 2; j < unsorted.Length; j += 2)
24 {
25 if (unsorted[j] < unsorted[j - 1])
26 {
27 int temp = unsorted[j - 1];
28 unsorted[j - 1] = unsorted[j];
29 unsorted[j] = temp;
30 }
31 }
32 }
33 else
34 {
35 for (int j = 1; j < unsorted.Length; j += 2)
36 {
37 if (unsorted[j] < unsorted[j - 1])
38 {
39 int temp = unsorted[j - 1];
40 unsorted[j - 1] = unsorted[j];
41 unsorted[j] = temp;
42 }
43 }
44 }
45 }
46 }
47
48 static void OptimizedOddEvenSort(int[] unsorted)
49 {
50 bool swapped = true;
51 int start = 0;
52
53 while (swapped || start == 1)
54 {
55 swapped = false;
56
57 for (int i = start; i < unsorted.Length - 1; i += 2)
58 {
59 if (unsorted[i] > unsorted[i + 1])
60 {
61 int temp = unsorted[i];
62 unsorted[i] = unsorted[i + 1];
63 unsorted[i + 1] = temp;
64
65 swapped = true;
66 }
67 }
68
69 if (start == 0) start = 1;
70 else start = 0;
71 }
72 }
73 }
快速排序使用分治法(Divide-and-Conquer)策略将一个数列分成两个子数列并使用递归来处理。
比如有如下这个 10 个数字,[13, 81, 92, 42, 65, 31, 57, 26, 75, 0]。
随机选择一个数作为中间的元素,例如选择 65。
这样数组就被 65 分成了两部分,左边的都小于 65,右边的都大于 65。
然后分别对左右两边的子数组按照相同的方式进行排序,并最终排序完毕。
算法描述
递归的最底部情形,是数列的大小是 0 或 1 ,也就是总是被排序好的状况。这样一直递归下去,直到算法退出。
下面的过程实现快速排序,调用 QUICKSORT(A, 1, length[A])。
1 QUICKSORT(A, p, r)
2 if p < r
3 then q <- PARTITION(A, p, r)
4 QUICKSORT(A, p, q - 1)
5 QUICKSORT(A, q + 1, r)
快速排序算法的关键是 Partition 过程,它对子数组进行就是重排。
1 PARTITION(A, p, r)
2 x <- A[r]
3 i <- p - 1
4 for j <- p to r - 1
5 do if A[j] <= x
6 then i <- i + 1
7 exchange A[i] <-> A[j]
8 exchange A[i + 1] <-> A[r]
9 return i + 1
算法复杂度
快速排序的运行时间与划分是否对称有关,而后者又与选择了哪一个元素来进行划分有关。如果划分是对称的,那么快速排序从渐进意义上来讲,就与合并算法一样快;如果划分是不对称的,那么从渐进意义上来讲,就与插入排序一样慢。
快速排序的平均运行时间与其最佳情况运行时间很接近,而不是非常接近于最差情况运行时间。
QUICKSORT 的运行时间是由花在过程 PARTITION 上的时间所决定的。每当 PARTITION 过程被调用时,就要选出一个 Pivot 元素。后续对 QUICKSORT 和 PARTITION 的各次递归调用中,都不会包含该元素。于是,在快速排序算法的整个执行过程中,至多只可能调用 PARTITION 过程 n 次。
快速排序的随机化版本
快速排序的随机化版本是对足够大的输入的理想选择。
RANDOMIZED-QUICKSORT 的平均运行情况是 O(n lg n),如果在递归的每一层上,RANDOMIZED-PARTITION 所作出的划分使任意固定量的元素偏向划分的某一边,则算法的递归树深度为 Θ(lg n),且在每一层上所做的工作量都为 O(n)。
1 RANDOMIZED-PARTITION(A, p, r)
2 i <- RANDOM(p, r)
3 exchange A[r] <-> A[i]
4 return PARTITION(A, p, r)
算法比较
快速排序是二叉查找树的一个空间优化版本。但其不是循序地把数据项插入到一个显式的树中,而是由快速排序组织这些数据项到一个由递归调用所隐含的树中。这两个算法完全地产生相同的比较次数,但是顺序不同。
快速排序的最直接竞争者是堆排序(Heap Sort)。堆排序通常会慢于原地排序的快速排序,其最坏情况的运行时间总是 O(n log n) 。快速排序通常情况下会比较快,但仍然有最坏情况发生的机会。
快速排序也会与合并排序(Merge Sort)竞争。合并排序的特点是最坏情况有着 O(n log n) 运行时间的优势。不像快速排序或堆排序,合并排序是一个稳定排序算法,并且非常的灵活,其设计可以应用于操作链表,或大型链式存储等,例如磁盘存储或网路附加存储等。尽管快速排序也可以被重写使用在链表上,但对于基准的选择总是个问题。合并排序的主要缺点是在最佳情况下需要 O(n) 额外的空间,而快速排序的原地分区和尾部递归仅使用 O(log n) 的空间。
代码示例
1 class Program
2 {
3 static bool isPrintArrayEnabled = false;
4
5 static void Main(string[] args)
6 {
7 int[] smallSeed = { 4, 1, 5, 2, 6, 3, 7, 9, 8, 0 };
8
9 MeasureQuickSort(smallSeed, 1000000);
10 MeasureRandomizedQuickSort(smallSeed, 1000000);
11 MeasureOptimizedQuickSorts(smallSeed, 1000000);
12
13 Console.Read();
14 }
15
16 static void MeasureQuickSort(int[] smallSeed, int arrayLength)
17 {
18 int[] unsorted = GenerateBigUnsortedArray(smallSeed, arrayLength);
19
20 Stopwatch watch = Stopwatch.StartNew();
21
22 QuickSort(unsorted, 0, unsorted.Length - 1);
23
24 watch.Stop();
25
26 Console.WriteLine(
27 "ArrayLength[{0}], QuickSort ElapsedMilliseconds[{1}]",
28 unsorted.Length, watch.ElapsedMilliseconds);
29
30 PrintArray(unsorted);
31 }
32
33 static void MeasureRandomizedQuickSort(int[] smallSeed, int arrayLength)
34 {
35 int[] unsorted = GenerateBigUnsortedArray(smallSeed, arrayLength);
36
37 Stopwatch watch = Stopwatch.StartNew();
38
39 RandomizedQuickSort(unsorted, 0, unsorted.Length - 1);
40
41 watch.Stop();
42
43 Console.WriteLine(
44 "ArrayLength[{0}], RandomizedQuickSort ElapsedMilliseconds[{1}]",
45 unsorted.Length, watch.ElapsedMilliseconds);
46
47 PrintArray(unsorted);
48 }
49
50 static void QuickSort(int[] unsorted, int left, int right)
51 {
52 // left 为子数列的最左边元素
53 // right 为子数列的最右边元素
54 if (!(left < right)) return;
55
56 // Partition:
57 // 所有元素比主元值小的摆放在主元的左边,
58 // 所有元素比主元值大的摆放在主元的右边
59 int pivotIndex = Partition(unsorted, left, right);
60
61 // Recursively:
62 // 分别排列小于主元的值和大于主元的值的子数列
63 // 主元无需参加下一次排序
64 QuickSort(unsorted, left, pivotIndex - 1);
65 QuickSort(unsorted, pivotIndex + 1, right);
66 }
67
68 static int Partition(int[] unsorted, int left, int right)
69 {
70 int pivotIndex = right;
71
72 // 哨兵
73 int sentinel = unsorted[right];
74
75 // 子数组长度为 right - left + 1
76 int i = left - 1;
77 for (int j = left; j <= right - 1; j++)
78 {
79 if (unsorted[j] <= sentinel)
80 {
81 i++;
82 Swap(unsorted, i, j);
83 }
84 }
85
86 Swap(unsorted, i + 1, pivotIndex);
87
88 return i + 1;
89 }
90
91 static void RandomizedQuickSort(int[] unsorted, int left, int right)
92 {
93 // left 为子数列的最左边元素
94 // right 为子数列的最右边元素
95 if (!(left < right)) return;
96
97 // Partition:
98 // 所有元素比主元值小的摆放在主元的左边,
99 // 所有元素比主元值大的摆放在主元的右边
100 int pivotIndex = RandomizedPartition(unsorted, left, right);
101
102 // Recursively:
103 // 分别排列小于主元的值和大于主元的值的子数列
104 // 主元无需参加下一次排序
105 RandomizedQuickSort(unsorted, left, pivotIndex - 1);
106 RandomizedQuickSort(unsorted, pivotIndex + 1, right);
107 }
108
109 static int RandomizedPartition(int[] unsorted, int left, int right)
110 {
111 int i = random.Next(left, right);
112 Swap(unsorted, i, right);
113 return Partition(unsorted, left, right);
114 }
115
116 static void Swap(int[] unsorted, int i, int j)
117 {
118 int temp = unsorted[i];
119 unsorted[i] = unsorted[j];
120 unsorted[j] = temp;
121 }
122
123 static void MeasureOptimizedQuickSorts(int[] smallSeed, int arrayLength)
124 {
125 foreach (var pivotSelection in
126 Enum.GetValues(typeof(QuickSortPivotSelectionType)))
127 {
128 int[] unsorted = GenerateBigUnsortedArray(smallSeed, arrayLength);
129
130 Stopwatch watch = Stopwatch.StartNew();
131
132 OptimizedQuickSort(unsorted, 0, unsorted.Length - 1,
133 (QuickSortPivotSelectionType)pivotSelection);
134
135 watch.Stop();
136
137 Console.WriteLine(
138 "ArrayLength[{0}], "
139 + "QuickSortPivotSelectionType[{1}], "
140 + "ElapsedMilliseconds[{2}]",
141 unsorted.Length,
142 (QuickSortPivotSelectionType)pivotSelection,
143 watch.ElapsedMilliseconds);
144
145 PrintArray(unsorted);
146 }
147 }
148
149 static int[] GenerateBigUnsortedArray(int[] smallSeed, int arrayLength)
150 {
151 int[] bigSeed = new int[100];
152 for (int i = 0; i < bigSeed.Length; i++)
153 {
154 bigSeed[i] =
155 smallSeed[i % smallSeed.Length]
156 + i / smallSeed.Length * 10;
157 }
158
159 int[] unsorted = new int[arrayLength];
160 for (int i = 0; i < unsorted.Length / bigSeed.Length; i++)
161 {
162 Array.Copy(bigSeed, 0, unsorted, i * bigSeed.Length, bigSeed.Length);
163 }
164
165 return unsorted;
166 }
167
168 static void OptimizedQuickSort(int[] unsorted, int left, int right,
169 QuickSortPivotSelectionType pivotSelection)
170 {
171 // left 为子数列的最左边元素
172 // right 为子数列的最右边元素
173 if (!(left < right)) return;
174
175 // Partition:
176 // 所有元素比主元值小的摆放在主元的左边,
177 // 所有元素比主元值大的摆放在主元的右边
178 Tuple<int, int> pivotPair =
179 OptimizedPartition(unsorted, left, right, pivotSelection);
180
181 // Recursively:
182 // 分别排列小于主元的值和大于主元的值的子数列
183 // 主元无需参加下一次排序
184 OptimizedQuickSort(unsorted, left, pivotPair.Item1 - 1, pivotSelection);
185 OptimizedQuickSort(unsorted, pivotPair.Item2 + 1, right, pivotSelection);
186 }
187
188 static Tuple<int, int> OptimizedPartition(
189 int[] unsorted, int left, int right,
190 QuickSortPivotSelectionType pivotSelection)
191 {
192 int pivotIndex = SelectPivot(unsorted, left, right, pivotSelection);
193 int sentinel = unsorted[pivotIndex];
194
195 // 子数组长度为 right - left + 1
196 int i = left - 1;
197 int j = right + 1;
198 while (true)
199 {
200 while (unsorted[++i] < sentinel) ;
201 while (unsorted[--j] > sentinel) ;
202 if (i >= j) break;
203
204 // 在主元左侧找到一个大于主元值的位置 i,
205 // 在主元右侧找到一个小于主元值的位置 j,
206 // 交换两个值
207 Swap(unsorted, i, j);
208 }
209
210 return new Tuple<int, int>(i, j);
211 }
212
213 static int SelectPivot(int[] unsorted, int left, int right,
214 QuickSortPivotSelectionType pivotSelection)
215 {
216 switch (pivotSelection)
217 {
218 case QuickSortPivotSelectionType.FirstAsPivot:
219 return left;
220 case QuickSortPivotSelectionType.MiddleAsPivot:
221 return (left + right) / 2;
222 case QuickSortPivotSelectionType.LastAsPivot:
223 return right;
224 case QuickSortPivotSelectionType.RandomizedPivot:
225 {
226 // 在区间内随机选择位置
227 if (right - left > 1)
228 {
229 return random.Next(left, right);
230 }
231 else
232 {
233 return left;
234 }
235 }
236 case QuickSortPivotSelectionType.BalancedPivot:
237 {
238 // 选择起始、中间和结尾位置中的中位数
239 int leftValue = unsorted[left];
240 int middleValue = unsorted[(left + right) / 2];
241 int rightValue = unsorted[right];
242
243 if (leftValue < middleValue)
244 {
245 if (middleValue < rightValue)
246 {
247 return (left + right) / 2;
248 }
249 else
250 {
251 return right;
252 }
253 }
254 else
255 {
256 if (leftValue < rightValue)
257 {
258 return left;
259 }
260 else
261 {
262 return right;
263 }
264 }
265 }
266 }
267
268 return (left + right) / 2;
269 }
270
271 static void PrintArray(int[] unsorted)
272 {
273 if (!isPrintArrayEnabled) return;
274
275 foreach (var item in unsorted)
276 {
277 Console.Write("{0} ", item);
278 }
279 Console.WriteLine();
280 }
281
282 static Random random = new Random(new Guid().GetHashCode());
283
284 enum QuickSortPivotSelectionType
285 {
286 FirstAsPivot,
287 MiddleAsPivot,
288 LastAsPivot,
289 RandomizedPivot,
290 BalancedPivot,
291 }
292 }
算法原理
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
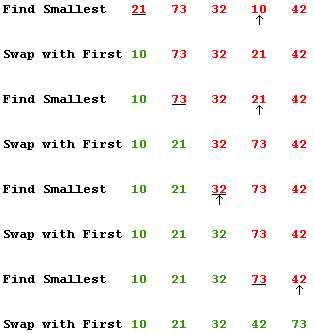
算法复杂度
选择排序的交换操作介于 0 和 (n-1) 次之间。选择排序的比较操作为 n(n-1)/2 次之间。选择排序的赋值操作介于 0 和 3(n-1) 次之间。
比较次数 O(n2),比较次数与关键字的初始状态无关,总的比较次数 N = (n-1)+(n-2)+...+1 = n*(n-1)/2。交换次数 O(n),最好情况是,已经有序,交换 0 次;最坏情况是,逆序,交换 n-1 次。交换次数比冒泡排序较少,由于交换所需 CPU 时间比比较所需的 CPU 时间多,n 值较小时,选择排序比冒泡排序快。
原地操作几乎是选择排序的唯一优点,当空间复杂度(space complexity)要求较高时,可以考虑选择排序,实际适用的场合非常罕见。
代码示例
1 class Program
2 {
3 static void Main(string[] args)
4 {
5 int[] unsorted = { 4, 1, 5, 2, 6, 3, 7, 9, 8 };
6
7 SelectionSort(unsorted);
8
9 foreach (var key in unsorted)
10 {
11 Console.Write("{0} ", key);
12 }
13
14 Console.Read();
15 }
16
17 static void SelectionSort(int[] unsorted)
18 {
19 // advance the position through the entire array
20 // could do i < n-1 because single element is also min element
21 for (int i = 0; i < unsorted.Length - 1; i++)
22 {
23 // find the min element in the unsorted a[i .. n-1]
24 // assume the min is the first element
25 int min = i;
26
27 // test against elements after i to find the smallest
28 for (int j = i + 1; j < unsorted.Length; j++)
29 {
30 // if this element is less, then it is the new minimum
31 if (unsorted[j] < unsorted[min])
32 {
33 // found new minimum, remember its index
34 min = j;
35 }
36 }
37
38 // swap
39 if (min != i)
40 {
41 int temp = unsorted[i];
42 unsorted[i] = unsorted[min];
43 unsorted[min] = temp;
44 }
45 }
46 }
47 }
算法原理
对于未排序数据,在已排序序列中从后向前扫描,找到相应位置,将位置后的已排序数据逐步向后挪位,将新元素插入到该位置。
算法描述
算法复杂度
插入排序算法的内循环是紧密的,对小规模输入来说是一个快速的原地排序算法。
示例代码
1 class Program
2 {
3 static void Main(string[] args)
4 {
5 int[] unsorted = { 4, 1, 5, 2, 6, 3, 7, 9, 8 };
6
7 InsertionSort(unsorted);
8
9 foreach (var key in unsorted)
10 {
11 Console.Write("{0} ", key);
12 }
13
14 Console.Read();
15 }
16
17 static void InsertionSort(int[] unsorted)
18 {
19 for (int i = 1; i < unsorted.Length; i++)
20 {
21 if (unsorted[i - 1] > unsorted[i])
22 {
23 int key = unsorted[i];
24 int j = i;
25 while (j > 0 && unsorted[j - 1] > key)
26 {
27 unsorted[j] = unsorted[j - 1];
28 j--;
29 }
30 unsorted[j] = key;
31 }
32 }
33 }
34 }
希尔排序是插入排序的一种更高效的改进版本,其基于插入排序的以下两个特点提出改进方法:
算法描述
希尔排序通过将比较的全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了,此时插入排序较快。
假设有一个很小的数据在一个已按升序排好序的数组的末端。如果用复杂度为 O(n2) 的排序(冒泡排序或插入排序),可能会进行 n 次的比较和交换才能将该数据移至正确位置。而希尔排序会用较大的步长移动数据,所以小数据只需进行少量比较和交换即可移到正确位置。
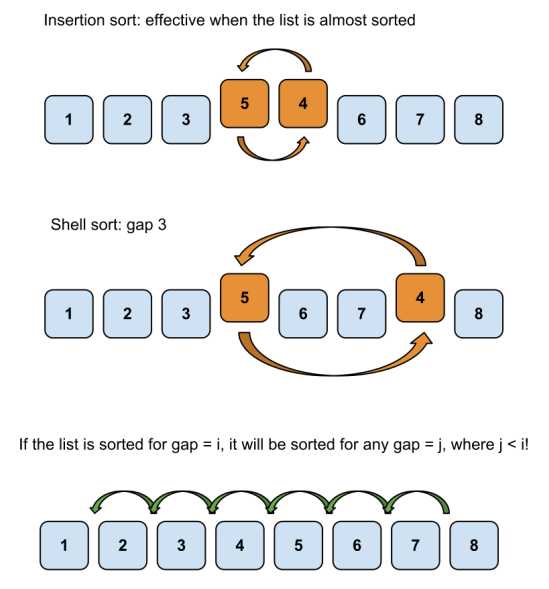
步长序列(Gap Sequences)
步长的选择是希尔排序的重要部分。只要最终步长为 1 任何步长串行都可以工作。算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为 1 进行排序。当步长为 1 时,算法变为插入排序,这就保证了数据一定会被排序。
已知的最好步长串行是由 Sedgewick 提出的 (1, 5, 19, 41, 109,...),该步长的项来自 9 * 4^i - 9 * 2^i + 1 和 4^i - 3 * 2^i + 1 这两个算式。这项研究也表明 "比较在希尔排序中是最主要的操作,而不是交换。" 用这样步长串行的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
算法复杂度
代码示例
1 class Program
2 {
3 static void Main(string[] args)
4 {
5 int[] unsorted = { 4, 1, 5, 2, 6, 3, 7, 9, 8 };
6
7 ShellSort(unsorted);
8
9 foreach (var key in unsorted)
10 {
11 Console.Write("{0} ", key);
12 }
13
14 Console.Read();
15 }
16
17 static void ShellSort(int[] unsorted)
18 {
19 int gap = (int)Math.Ceiling(unsorted.Length / 2D);
20
21 // start with the largest gap and work down to a gap of 1
22 while (gap > 0)
23 {
24 // do a gapped insertion sort for this gap size.
25 // the first gap elements a[0..gap-1] are already in gapped order
26 // keep adding one more element until the entire array is gap sorted
27 for (int i = 0; i < unsorted.Length; i++)
28 {
29 // add a[i] to the elements that have been gap sorted
30 // save a[i] in temp and make a hole at position i
31 int j = i;
32 int temp = unsorted[i];
33
34 // shift earlier gap-sorted elements up
35 // until the correct location for a[i] is found
36 while (j >= gap && unsorted[j - gap] > temp)
37 {
38 unsorted[j] = unsorted[j - gap];
39 j = j - gap;
40 }
41
42 // put temp (the original a[i]) in its correct location
43 unsorted[j] = temp;
44 }
45
46 // change gap
47 gap = (int)Math.Floor(0.5 + gap / 2.2);
48 }
49 }
50 }
合并排序是分治法的典型应用。
分治法(Divide-and-Conquer):将原问题划分成 n 个规模较小而结构与原问题相似的子问题;递归地解决这些问题,然后再合并其结果,就得到原问题的解。
分治模式在每一层上都有三个步骤:
合并排序算法完全依照了上述模式:
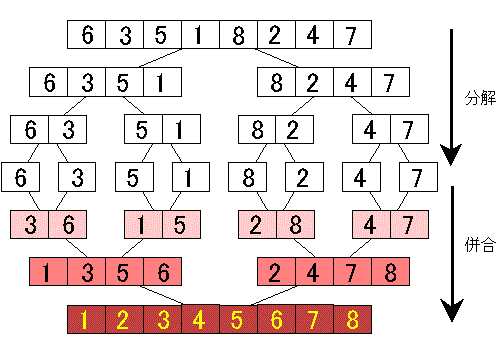
算法描述
算法复杂度
合并排序有着较好的渐进运行时间 Θ(nlogn),但其中的 merge 操作不是 in-place 操作。
示例代码
1 class Program
2 {
3 static void Main(string[] args)
4 {
5 int[] unsorted = { 4, 1, 5, 2, 6, 3, 7, 9, 8 };
6
7 int[] temp = new int[unsorted.Length];
8 MergeSort(unsorted, 0, unsorted.Length, temp);
9 foreach (var key in unsorted)
10 {
11 Console.Write("{0} ", key);
12 }
13
14 Console.Read();
15 }
16
17 static void MergeSort(int[] unsorted, int left, int right, int[] temp)
18 {
19 if (left + 1 < right)
20 {
21 // divide
22 int mid = (left + right) / 2;
23
24 // conquer
25 MergeSort(unsorted, left, mid, temp);
26 MergeSort(unsorted, mid, right, temp);
27
28 // combine
29 Merge(unsorted, left, mid, right, temp);
30 }
31 }
32
33 static void Merge(int[] unsorted, int left, int mid, int right, int[] temp)
34 {
35 int leftPosition = left;
36 int rightPosition = mid;
37 int numberOfElements = 0;
38
39 // merge two slots
40 while (leftPosition < mid && rightPosition < right)
41 {
42 if (unsorted[leftPosition] < unsorted[rightPosition])
43 {
44 temp[numberOfElements++] = unsorted[leftPosition++];
45 }
46 else
47 {
48 temp[numberOfElements++] = unsorted[rightPosition++];
49 }
50 }
51
52 // add remaining
53 while (leftPosition < mid)
54 {
55 temp[numberOfElements++] = unsorted[leftPosition++];
56 }
57 while (rightPosition < right)
58 {
59 temp[numberOfElements++] = unsorted[rightPosition++];
60 }
61
62 // copy back
63 for (int n = 0; n < numberOfElements; n++)
64 {
65 unsorted[left + n] = temp[n];
66 }
67 }
68 }
堆排序(Heap Sort)是指利用堆这种数据结构所设计的一种排序算法。二叉堆数据结构是一种数组对象,它可以被视为一棵完全二叉树。树中每个节点与数组中存放该节点值的那个元素对应。
二叉堆有两种,最大堆和最小堆。最大堆特性是指除了根以外的每个节点 i ,有 A(Parent(i)) ≥ A[i] ,即某个节点的值至多是和其父节点的值一样大。最小堆特性是指除了根以外的每个节点 i ,有 A(Parent(i)) ≤ A[i] ,最小堆的最小元素在根部。
在堆排序算法中,我们使用的是最大堆。最小堆通常在构造有限队列时使用。
堆可以被看成一棵树,节点在堆中的高度定义为从本节点到叶子的最长简单下降路径上边的数目;定义堆的高度为树根的高度。因为具有 n 个元素的堆是基于一棵完全二叉树,因而其高度为 Θ(lg n) 。
堆节点的访问
通常堆是通过一维数组来实现的。在数组起始为 0 的情形中,如果 i 为当前节点的索引,则有
堆的操作
在堆的数据结构中,堆中的最大值总是位于根节点。堆中定义以下几种操作:
算法复杂度
示例代码
1 class Program
2 {
3 static void Main(string[] args)
4 {
5 int[] unsorted = { 4, 1, 5, 2, 6, 3, 7, 9, 8 };
6
7 HeapSort(unsorted);
8
9 foreach (var key in unsorted)
10 {
11 Console.Write("{0} ", key);
12 }
13
14 Console.Read();
15 }
16
17 static void HeapSort(int[] unsorted)
18 {
19 // build the heap in array so that largest value is at the root
20 BuildMaxHeap(unsorted);
21
22 // swap root node and the last heap node
23 for (int i = unsorted.Length - 1; i >= 1; i--)
24 {
25 // array[0] is the root and largest value.
26 // the swap moves it in front of the sorted elements
27 int max = unsorted[0];
28 unsorted[0] = unsorted[i];
29 unsorted[i] = max; // now, the largest one is at the end
30
31 // the swap ruined the heap property, so restore it
32 // the heap size is reduced by one
33 MaxHeapify(unsorted, 0, i - 1);
34 }
35 }
36
37 static void BuildMaxHeap(int[] unsorted)
38 {
39 // put elements of array in heap order, in-place
40 // start is assigned the index in array of the last parent node
41 // the last element in 0-based array is at index count-1;
42 // find the parent of that element
43 for (int i = (unsorted.Length / 2) - 1; i >= 0; i--)
44 {
45 // sift down the node at index start to the proper place
46 // such that all nodes below the start index are in heap order
47 MaxHeapify(unsorted, i, unsorted.Length - 1);
48 }
49 // after sifting down the root all nodes/elements are in heap order
50 }
51
52 static void MaxHeapify(int[] unsorted, int root, int bottom)
53 {
54 int rootValue = unsorted[root];
55 int maxChild = root * 2 + 1; // start from left child
56
57 // while the root has at least one child
58 while (maxChild <= bottom)
59 {
60 // more children
61 if (maxChild < bottom)
62 {
63 // if there is a right child and that child is greater
64 if (unsorted[maxChild] < unsorted[maxChild + 1])
65 {
66 maxChild = maxChild + 1;
67 }
68 }
69
70 // compare roots and the older children
71 if (rootValue < unsorted[maxChild])
72 {
73 unsorted[root] = unsorted[maxChild];
74 root = maxChild;
75
76 // repeat to continue sifting down the child now
77 maxChild = root * 2 + 1; // continue from left child
78 }
79 else
80 {
81 maxChild = bottom + 1;
82 }
83 }
84
85 unsorted[root] = rootValue;
86 }
87 }
标签:sed max extra category not its 随机选择 随机化 bin
原文地址:http://www.cnblogs.com/ze7777/p/7239320.html