标签:erb enc res asn one null 向量 com https
测试数据集:item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
测试程序:org.conan.mymahout.recommendation.job.RecommenderTest.java
package org.conan.mymahout.recommendation.job;
import java.io.IOException;
import java.util.List;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.common.RandomUtils;
public class RecommenderTest {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws TasteException, IOException {
RandomUtils.useTestSeed();
String file = "datafile/item.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
slopeOne(dataModel);
}
public static void userCF(DataModel dataModel) throws TasteException{}
public static void itemCF(DataModel dataModel) throws TasteException{}
public static void slopeOne(DataModel dataModel) throws TasteException{}
...
每种算法都一个单独的方法进行算法测试,如userCF(),itemCF(),slopeOne()….
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
举例说明:
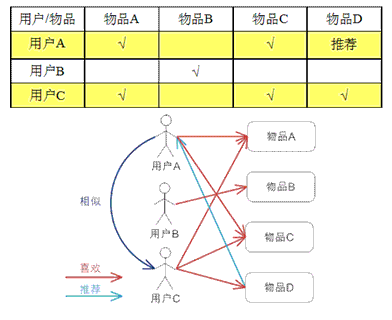
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。图 2 给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 – 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
上文中图片和解释文字,摘自: https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
算法API: org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
DataModel model = getDataModel();
Float actualPref = model.getPreferenceValue(userID, itemID);
if (actualPref != null) {
return actualPref;
}
long[] theNeighborhood = neighborhood.getUserNeighborhood(userID);
return doEstimatePreference(userID, theNeighborhood, itemID);
}
protected float doEstimatePreference(long theUserID, long[] theNeighborhood, long itemID) throws TasteException {
if (theNeighborhood.length == 0) {
return Float.NaN;
}
DataModel dataModel = getDataModel();
double preference = 0.0;
double totalSimilarity = 0.0;
int count = 0;
for (long userID : theNeighborhood) {
if (userID != theUserID) {
// See GenericItemBasedRecommender.doEstimatePreference() too
Float pref = dataModel.getPreferenceValue(userID, itemID);
if (pref != null) {
double theSimilarity = similarity.userSimilarity(theUserID, userID);
if (!Double.isNaN(theSimilarity)) {
preference += theSimilarity * pref;
totalSimilarity += theSimilarity;
count++;
}
}
}
}
// Throw out the estimate if it was based on no data points, of course, but also if based on
// just one. This is a bit of a band-aid on the ‘stock‘ item-based algorithm for the moment.
// The reason is that in this case the estimate is, simply, the user‘s rating for one item
// that happened to have a defined similarity. The similarity score doesn‘t matter, and that
// seems like a bad situation.
if (count <= 1) {
return Float.NaN;
}
float estimate = (float) (preference / totalSimilarity);
if (capper != null) {
estimate = capper.capEstimate(estimate);
}
return estimate;
}
测试程序:
public static void userCF(DataModel dataModel) throws TasteException {
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
}
程序输出:
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.0
Recommender IR Evaluator: [Precision:0.5,Recall:0.5]
uid:1,(104,4.333333)(106,4.000000)
uid:2,(105,4.049678)
uid:3,(103,3.512787)(102,2.747869)
uid:4,(102,3.000000)
mahout demo——本质上是基于Hadoop的分步式算法实现,比如多节点的数据合并,数据排序,网路通信的效率,节点宕机重算,数据分步式存储
标签:erb enc res asn one null 向量 com https
原文地址:http://www.cnblogs.com/bonelee/p/7243282.html